📄 Ailive Mixer: A Deep Learning Based Zero Latency Automatic Music Mixer for Live Music Performances
#音乐混合 #深度学习 #实时处理 #串音消除
✅ 7.0/10 | 前25% | #音乐混合 | #深度学习 | #实时处理 #串音消除
学术质量 5.5/7 | 选题价值 1.0/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Devansh Zurale(Shure Incorporated)
- 通讯作者:未说明
- 作者列表:Devansh Zurale(Shure Incorporated)、Iris Lorente(Shure Incorporated)、Michael Lester(Shure Incorporated)、Alex Mitchell(Shure Incorporated)
💡 毒舌点评
亮点:该工作首次将端到端深度学习应用于实时音乐混合,并通过“多速率处理”和“预测未来帧”的策略巧妙绕过了模型延迟问题,工程思路清晰。短板:尽管实验声称“零延迟”,但评估完全依赖主观听音测试且样本量小,缺乏如频谱图一致性、增益曲线平滑度等客观量化分析,使得“显著优于基线”的结论说服力打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开模型权重。
- 数据集:训练数据基于公开的MedleyDB,但论文中模拟串音的具体脚本或工具未公开。评估使用的内部现场表演数据集未公开。
- Demo:提供了音频结果在线演示:https://dzurale.github.io/ailive_mixer_icassp2026/。
- 复现材料:给出了详细的架构描述、训练超参数(学习率、调度、epoch数)、损失函数选择(窗长、FFT大小)、数据增强方法(pyroomacoustics随机模拟)。这些信息对复现研究至关重要。
- 论文中引用的开源项目:
- VGGish:音频嵌入模型 [12]。
- pyroomacoustics:用于模拟房间声学和串音 [17]。
- auraloss:用于计算多分辨率STFT损失的PyTorch库 [19]。
- Web Audio Evaluation Tool:用于主观听音测试的框架 [21]。
- 总结:论文未提及开源计划,核心系统(ALM)的代码和模型未开源。复现工作主要依赖论文描述和上述开源工具的重新实现。
📌 核心摘要
这篇论文提出了一种名为AiLive Mixer(ALM)的深度学习系统,用于解决现场音乐表演中自动混音面临的两大核心挑战:乐器间的声学串音和严格的零延迟要求。其方法核心是采用多速率(Multi-Rate)处理架构,将需要大时域上下文的VGGish音频嵌入模块(975ms帧)与需要快速响应的特征提取(50ms帧)解耦,并引入零延迟训练策略(模型预测下一帧的增益参数)。与已有方法(如DMC)相比,ALM的创新在于增加了RMS条件化、用于学习通道间关系的Transformer编码器、用于学习时序上下文的GRU模块,并专门设计用于处理训练时的模拟串音数据。实验基于主观听音测试(15名参与者,8段现场录音),结果显示多速率模型ALM-MR在感知评分上显著优于单速率模型(ALM-SR)、改进版DMC(DMC-B-0L)、原版DMC(DMC-OG)以及原始混音(RAW),且能更稳定地避免增益突变和削波。该研究的实际意义在于为智能现场扩声、直播等应用提供了自动化混音的可行框架。主要局限性在于仅预测了声道增益这一单一混音参数,且验证集规模较小,缺乏客观评估指标。
🏗️ 模型架构
AiLive Mixer(ALM)的系统架构如图1所示,其核心是处理多通道音频输入,为每个通道预测一个单声道增益参数,最终将所有增益应用后的音频波形求和,生成混合输出。
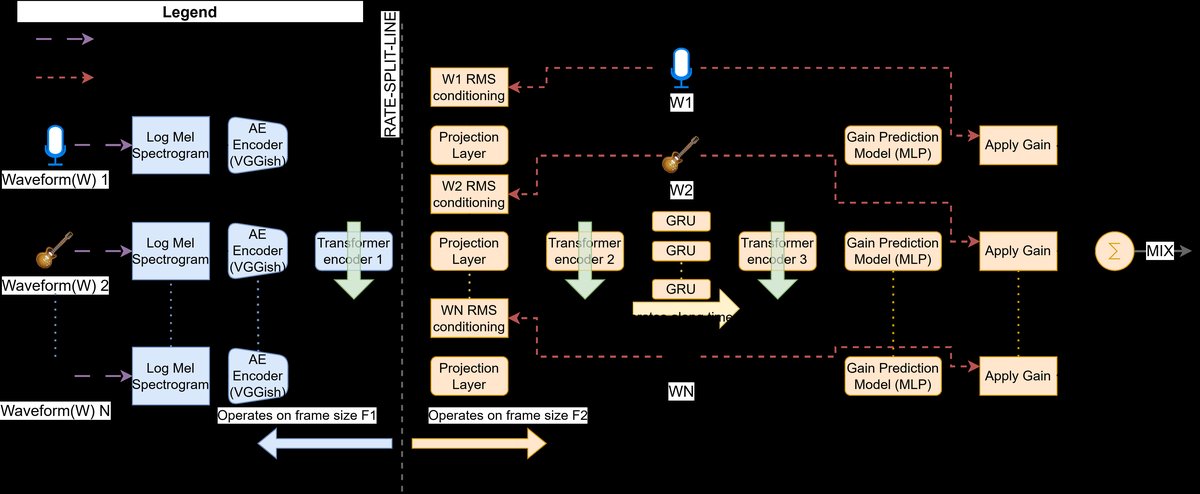
完整数据流与组件详解:
- 音频嵌入模型:每个原始音频通道首先通过一个预训练的VGGish模型,该模型在975ms(F1) 的长帧上运行,提取与乐器类型及串音程度相关的嵌入特征。论文通过微调使VGGish能感知串音信息。
- Transformer-Encoder 1:嵌入特征输入第一个Transformer编码器(单层,2头),该模块沿通道轴运行,用于学习不同乐器通道之间的上下文关系(如乐器类型组合)。
- RMS条件化:计算每个通道在更短的F2帧(50ms) 上的均方根(RMS)值。该值通过一个线性投影层和PReLU激活注入系统,以补偿音频嵌入模型对输入电平不敏感的问题,提供关键的信号强度信息。
- Transformer-Encoder 2:第二个Transformer编码器作用于包含RMS信息的特征,进一步学习基于相对电平的通道间上下文。
- 时序模块(GRU):为引入时间上下文,特征通过一个单层GRU(隐藏维度128),沿时间轴运行。这有助于模型做出更连贯的预测,尤其是在需要预测未来帧时。
- Transformer-Encoder 3:第三个Transformer编码器作用于GRU输出的、包含时序信息的嵌入,学习时序增强后的通道间关系。
- 增益预测MLP:最终,一个MLP(三层隐藏层:128, 64, 32;输出层为1)为该通道预测一个0-1之间的增益值(使用ReLU输出确保非负)。
关键设计选择与动机:
- 多速率处理(Multi-Rate Processing):这是实现低延迟的核心。系统分为两条速率线:左侧(蓝块)处理长帧(F1=975ms),右侧(橙块)处理短帧(F2=50ms)。通过让MLP输出基于短帧的增益,将系统延迟从975ms降低至50ms(理论上可更低)。F1帧以300ms(6个F2帧)的步长滑动,以平衡计算负载。单速率(SR)模式下,F2=F1=975ms,作为基线对比。
- 零延迟训练:为实现真正的“零延迟”,模型被训练为预测当前F2帧所对应的下一帧的增益值。推理时,新音频到达时模型已准备好对应的增益,从而实现即时应用。
- 分布式Transformer:在系统中三个关键点(嵌入后、RMS后、GRU后)分别放置轻量Transformer,比在单点堆叠多层Transformer效果更好,能更针对性地学习不同层面的通道上下文。
💡 核心创新点
- 针对现场表演的端到端深度学习系统:是什么:首个明确针对现场音乐表演场景(存在串音、需零延迟)设计的端到端自动混音深度学习系统。局限:此前工作多面向离线制作,且假设输入是隔离音源。作用与收益:填补了该场景的技术空白,ALM-MR在主观测试中显著优于离线模型(DMC)的现场适配版本。
- 多速率处理架构:是什么:将计算分为长帧(用于提取稳定特征)和短帧(用于快速响应)两种处理速率。局限:单一速率(如975ms)会导致高延迟或慢反应。作用与收益:将系统固有延迟从975ms降至50ms,同时利用长帧信息做出稳健预测,减少了增益突变。
- 零延迟训练策略:是什么:训练模型预测下一时间步的混音参数。局限:常规训练预测当前帧,在实时应用中会引入至少一帧的延迟。作用与收益:结合多速率处理,实现了感知上的“零延迟”,使输出音频与画面同步成为可能。
- 用于串音处理的数据增强与架构:是什么:使用pyroomacoustics模拟多样化的串音场景进行训练,并在架构中加入Transformer来显式建模通道间关系。局限:真实串音比模拟更复杂。作用与收益:使模型在输入存在严重串音的情况下,仍能做出合理的增益决策,这是现场混音的关键能力。
🔬 细节详述
- 训练数据:使用MedleyDB数据集中的隔离乐器轨道。为模拟现场串音,利用pyroomacoustics库随机参数化地模拟房间响应,将音轨相互串入彼此麦克风。训练时随机化模拟参数(房间尺寸、混响等)以及所有轨道的输入电平(在串音前后均进行),以生成海量多样化的训练样本。验证集为MedleyDB中8首歌(<=8轨)。
- 损失函数:多分辨率STFT损失(Multi-Resolution STFT Loss)。使用440、884、3528三种窗长(约0.01、0.02、0.08秒),25%的跳跃大小,对应FFT大小为512、1024、4196。该损失函数通过比较生成音频与目标音频在多个时频分辨率下的频谱差异,综合优化波形的时域和频域质量。论文使用了
auraloss库计算。 - 训练策略:
- 优化器:AdamW。
- 学习率:初始0.001,使用多阶段调度:在第100、1000、2500个epoch时衰减10倍。
- 训练轮数:5000个epoch。每个epoch完整遍历训练集歌曲,并随机采样20秒片段。
- 微调策略:VGGish嵌入模型先冻结权重训练100个epoch,之后解冻,与其余部分使用相同学习率联合微调。
- 关键超参数:
- F1帧长:975 ms(对应VGGish输入)。
- F2帧长:MR模式为50 ms,SR模式为975 ms。
- F1帧滑动步长:MR模式下为300 ms(6个F2帧)。
- GRU:单层,隐藏维度128。
- Transformer-Encoder:每个均为单层,2头。
- 增益预测MLP:隐藏层尺寸为128 -> 64 -> 32,输出层1维。使用PReLU激活(除输出层用ReLU)。
- 训练硬件:论文中未说明。
- 推理细节:模型输出为0-1的增益值,直接乘以对应通道的波形,然后所有通道求和得到单声道混音输出。MR模式下,模型每50ms输出一个新增益;SR模式下,每975ms输出一个。
- 正则化技巧:论文未提及使用Dropout等显式正则化。主要依靠数据增强和模型本身的约束(如小规模Transformer和MLP)来控制过拟合。
📊 实验结果
主观听音测试设计:
- 参与者:15名具有批判性听力能力的音频专业人士(包括音乐人、混音师)。
- 测试音频:来自内部现场表演数据集的8个片段(20-30秒),涵盖不同音乐风格。
- 对比系统:5种混音结果:ALM-MR, ALM-SR, DMC-B-0L(DMC架构+串音训练+零延迟), DMC-OG(原版DMC), RAW(原始轨道直接求和)。
- 测试工具:Web Audio Evaluation Tool,采用APE测试设计。
- 评分方式:绝对评分(图3)和按歌曲/参与者归一化的相对评分(图4)。
核心结果(基于图3和图4):
- 绝对评分分布(图3):ALM-MR的评分高度集中在高分区域(~0.75),表明其混音质量感知最佳且一致性高。ALM-SR评分也较高但分布更散。DMC模型和RAW的评分则集中在较低区域(<0.5)。
- 相对排名(图4):归一化后的排序为:ALM-MR > ALM-SR > DMC-B-0L > DMC-OG > RAW。
- 统计显著性:Kruskal-Wallis H检验显示模型间存在显著差异(H=156.485, p≈8.3e-33)。配对检验(Conover’s test)表明:
- ALM-MR和ALM-SR与其它所有模型(DMC-B-0L, DMC-OG, RAW)均有极显著差异(p值量级为1e-15到1e-24)。
- DMC-B-0L与RAW存在显著差异。
- ALM-MR与ALM-SR、DMC-OG与DMC-B-0L、DMC-OG与RAW之间无显著差异的证据。
- 定性观察:
- 增益稳定性:ALM-MR几乎无增益突变,ALM-SR较少,DMC模型频繁出现。这是ALM-MR得分更集中、更高分的关键原因。
- 削波避免:ALM-MR最一致地避免了输出削波。
- 瞬态处理:ALM-MR对打击乐(如贝斯)的混音更好,可能得益于其对短时RMS的敏感性。
结论:所有结果均为主观评分,论文未提供任何客观指标(如频谱距离、增益曲线统计量)的定量对比。消融实验验证了多速率处理(ALM-MR vs ALM-SR)、以及ALM架构(ALM-SR vs DMC-B-0L)的有效性。
⚖️ 评分理由
- 学术质量:5.5/7:创新性明确,技术方案(多速率、零延迟训练、分布式Transformer)设计合理且动机充分。实验上,消融研究设计得当,能验证各模块贡献。主要扣分点在于:1)实验规模小(仅8首验证歌曲);2)评估完全依赖主观听音,缺乏客观可量化的证据;3)模型输出仅限增益预测,功能维度单一;4)训练依赖模拟串音,其泛化能力未经严格验证。
- 选题价值:1.0/2:选题切入了一个明确的工程痛点(现场自动混音),具有实际应用潜力,特别是在与硬件厂商(如Shure)结合的场景下。但作为学术研究,其问题���较为垂直,在更广泛的AI音频社区中的影响力和关注度有限。
- 开源与复现加成:0.5/1:论文详细描述了架构、训练流程和超参数,复现指引清晰。但未开源代码、模型或数据,这大大增加了其他研究者跟进和验证的难度,因此加分有限。