📄 AFT: An Exemplar-Free Class Incremental Learning Method for Environmental Sound Classification
#音频分类 #知识蒸馏 #迁移学习 #低资源 #鲁棒性
✅ 7.0/10 | 前25% | #音频分类 | #知识蒸馏 | #迁移学习 #低资源
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Xinyi Chen(华南理工大学, 暨黄埔超级机器人研究院)
- 通讯作者:Yang Xiao(墨尔本大学)
- 作者列表:Xinyi Chen(华南理工大学, 暨黄埔超级机器人研究院)、Xi Chen(香港中文大学(深圳))、Zhenyu Weng(华南理工大学, 暨黄埔超级机器人研究院)、Yang Xiao(墨尔本大学)
💡 毒舌点评
本文巧妙地将特征空间变换的思想引入无样例增量学习,通过主动对齐新旧特征来缓解遗忘,比单纯的知识蒸馏更直接,实验结果也确实漂亮,在特定任务上带来了稳定的性能提升。然而,论文对AFT网络本身的参数量和计算开销避而不谈,对于一个旨在部署于“边缘设备”的方法而言,这种“选择性失明”有点像是在画饼时省略了面粉的成本。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用了公开数据集UrbanSound8K和DCASE 2019 Task 1,论文中未提供新的数据集。
- Demo:未提及。
- 复现材料:论文提供了骨干网络型号(TCResNet-8)、主要数据处理步骤(采样率、MFCC维数)、优化器(Adam)、学习率(1e-3)、batch size(128)、训练轮数(50)以及损失权重搜索范围。但AFT网络结构、具体超参数(如α, β, γ的最终选择值)和训练硬件未说明。
- 论文中引用的开源项目:引用了TCResNet-8 [27]、Adam优化器 [28]等基础方法和工具。
- 论文中未提及开源计划。
📌 核心摘要
- 要解决什么问题:在环境声分类的类增量学习中,模型学习新声音类别时会灾难性地遗忘旧类别知识。现有无样例方法(不存储历史数据)在处理声学特征相似的类别(如“电钻”和“手提钻”)时,由于特征空间发生漂移,会导致严重的识别混淆。
- 方法核心是什么:提出声学特征变换(AFT)框架,其核心是一个可训练的AFT网络(M),用于将上一阶段模型(旧模型)提取的特征映射到当前阶段(新模型)的特征空间中,从而直接对齐新旧特征,缓解特征漂移。同时,采用“选择性压缩”策略,通过筛选每个类别的高质量原型特征来构建更清晰、鲁棒的类边界。
- 与已有方法相比新在哪里:不同于传统知识蒸馏(LWF)仅约束模型输出或传统正则化方法(EWC, SI)约束参数,AFT主动地对特征表示空间进行变换和对齐,是一种更直接、更针对特征漂移问题的解决方案。同时,结合了选择性特征压缩来增强原型特征的代表性。
- 主要实验结果如何:在UrbanSound8K和DCASE 2019 Task 1两个数据集上,以TCResNet-8为骨干网络,AFT方法取得了最优性能。主要结果对比如下:
方法 UrbanSound8K ACC(%) UrbanSound8K BWT DCASE 2019 Task 1 ACC(%) DCASE 2019 Task 1 BWT Finetune (下界) 26.700 -0.368 22.900 -0.267 EWC 29.284 -0.358 23.472 -0.264 SI 42.267 -0.264 26.802 -0.233 LWF 52.285 -0.198 46.965 -0.097 LDC 56.703 -0.157 48.867 -0.104 AFT (本文) 60.464 -0.147 52.762 -0.077 Joint (上界) 93.204 - 66.725 - AFT相比最强基线LDC,在UrbanSound8K上提升了3.76个百分点,在DCASE 2019 Task 1上提升了3.90个百分点,同时BWT(衡量遗忘程度)也有改善。消融实验证明,AFT模块和选择性压缩(POS)模块都对最终性能有贡献。t-SNE可视化图(图1, 图5)直观展示了AFT如何纠正特征漂移,恢复清晰的类边界。 - 实际意义是什么:为需要在隐私敏感场景(如无法保存用户音频数据的边缘设备)下持续学习新环境声音的应用(如野生动物监测、智能家居)提供了一种有效的解决方案。
- 主要局限性是什么:1) 论文未提供AFT网络自身的详细结构、参数量及其带来的额外计算成本分析,这对于声称适用于“边缘设备”的方法是关键的缺失信息。2) 实验设置相对简单(固定5个任务),未探讨任务数量、类别相似度变化等更复杂场景下的性能。3) 未与最新的无样例增量学习方法进行对比。
🏗️ 模型架构
论文提出的AFT(声学特征变换)框架旨在解决无样例类增量学习中的特征漂移问题。其整体架构和数据流如下图所示:
 图2:AFT框架示意图
图2:AFT框架示意图
- 输入与骨干网络:输入为环境声音频(预处理为MFCC特征),送入TCResNet-8骨干网络。该网络是一个轻量级的时间卷积网络,包含三个残差块,适用于移动端实时处理。
- 双模型状态:框架涉及两个模型状态:
- 冻结的旧模型(Task τ_{t-1}):在上一任务训练完成后冻结,用于提取旧特征。
- 可训练的新模型(Task τ_t):当前任务下正在更新的模型,用于提取新特征和进行分类。
- 核心模块:
- 特征蒸馏(Feature Distillation):将同一输入
x分别输入旧模型和新模型,得到旧特征f_{t-1}(x)和新特征f_t(x)。通过损失L_kfd = ||f_t(x) - f_{t-1}(x)||^2约束新旧特征相似,这是基础的知识保留。 - 声学特征变换网络(AFT Network, M):这是本文的核心创新。它是一个额外的小型网络,其输入是旧特征
f_{t-1}(x),输出是变换后的特征M(f_{t-1}(x))。训练目标是让这个变换后的特征与新模型在当前数据上提取的特征f_t(x)对齐,即最小化损失L_trans = ||f_t(x) - M(f_{t-1}(x))||^2。这个网络的作用是主动学习一种映射关系,将旧模型的特征空间“翻译”到新模型的特征空间,从而在概念上连接了新旧知识。 - 选择性压缩特征空间(Selective Compression):在每个任务结束后,需要为每个已学类别保存一个原型特征(prototype)。简单取均值容易受噪声和异常值影响(见图3左)。AFT方法首先通过模型预测与真实标签的比较,剔除预测错误的“离群点”样本(见图3右),然后计算剩余高质量样本的特征均值作为该类别的原型。此外,在后续任务中,这些存储的旧类别原型也会通过AFT网络
M进行变换更新,以保持与当前特征空间的一致性。
- 特征蒸馏(Feature Distillation):将同一输入
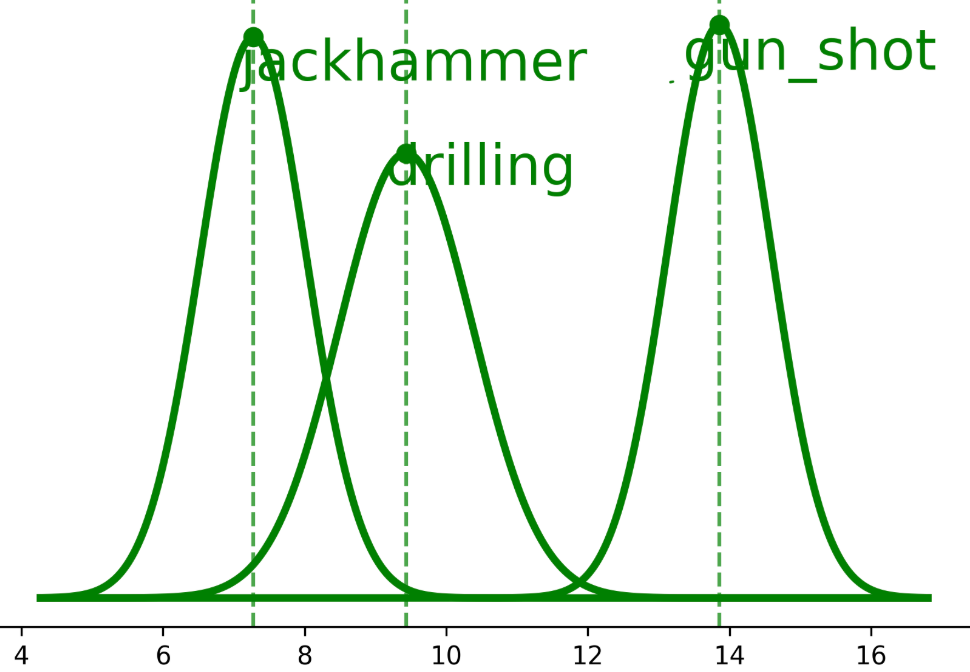 图3:选择性压缩特征空间示意
数据流总结:对于当前任务
图3:选择性压缩特征空间示意
数据流总结:对于当前任务t的数据,新模型通过L_ce学习分类,同时通过L_kfd和L_trans分别保留与旧模型输出特征和旧特征变换后的相似性。任务结束后,新类别原型(经选择性压缩)与旧类别原型(经AFT网络变换后)共同构成当前阶段的特征库,供下一个增量任务使用。
💡 核心创新点
- 主动特征空间对齐(AFT Network):这是最核心的创新。不同于传统方法被动地约束模型输出或参数,AFT引入一个显式的、可学习的变换网络来主动将旧特征映射到新特征空间。这直接瞄准了无样例学习中“特征漂移”这一根本问题,为维持特征表示的一致性提供了一种更灵活、更直接的机制。
- 选择性特征压缩原型构建:针对基于原型方法的弱点(原型易受数据质量影响),提出了通过模型预测一致性来筛选高质量样本构建类原型的方法。这增强了所保存知识的鲁棒性和代表性,有助于维持清晰的类间边界。
- 隐私友好的无样例设计:整个AFT框架严格遵循无样例设定,不需要存储任何历史原始数据,仅需存储和更新变换后的类原型特征。这使其非常适合数据隐私要求严格的应用场景,如智能家居、野生动物监测设备等。
🔬 细节详述
- 训练数据:
- 数据集:UrbanSound8K(8732条,10类,≤4秒)和DCASE 2019 Task 1(开发集,10类,10秒)。
- 预处理:音频重采样至16kHz单声道。UrbanSound8K取前3秒,DCASE使用完整10秒。提取40维MFCC特征。
- 增强:未明确说明。
- 损失函数:总损失为
Loss = L_ce + αL_kfd + βL_trans + γL_fs。L_ce:标准的交叉熵损失,用于新任务分类。L_kfd:特征蒸馏损失(L2范数),约束新模型输出特征与旧模型输出特征相似。L_trans:特征变换损失(L2范数),约束AFT网络变换后的旧特征与新模型输出特征相似。L_fs:特征空间分类损失。将变换后的旧类别原型特征M(F_{t-1})送入分类器g,计算其与旧标签的交叉熵损失,确保变换后的旧知识仍可被正确分类。- 权重:通过网格搜索确定,α ∈ {0.1, 1, 1.5, 2}, β ∈ {1, 5, 15, 18, 20}, γ ∈ {1, 5, 15, 18, 20}。
- 训练策略:
- 优化器:Adam。
- 学习率:1×10^{-3}。
- Batch Size:128。
- Epochs:50。
- 任务划分:先在5个类别上预训练,然后依次增量学习剩余5个类别(共5个任务)。
- 关键超参数:骨干网络为TCResNet-8,通道数设为16, 24, 32, 48。AFT网络
M的具体结构未说明。 - 训练硬件:未说明。
- 推理细节:未提及特殊解码策略,应为标准前向传播。
- 正则化/稳定技巧:使用了选择性压缩(POS)来稳定原型表示;通过多损失组合平衡新旧知识学习。
📊 实验结果
主要对比实验 论文在Table 1中给出了与多种基线方法的详细对比,数据如下:
| 方法 | UrbanSound8K ACC(%) | UrbanSound8K BWT | DCASE 2019 Task 1 ACC(%) | DCASE 2019 Task 1 BWT |
|---|---|---|---|---|
| Finetune | 26.700 | -0.368 | 22.900 | -0.267 |
| EWC | 29.284 | -0.358 | 23.472 | -0.264 |
| SI | 42.267 | -0.264 | 26.802 | -0.233 |
| LWF | 52.285 | -0.198 | 46.965 | -0.097 |
| LDC | 56.703 | -0.157 | 48.867 | -0.104 |
| AFT (ours) | 60.464 | -0.147 | 52.762 | -0.077 |
| Joint | 93.204 | - | 66.725 | - |
结论:AFT在两个数据集上均取得了最高的平均准确率(ACC)和最低的向后迁移(BWT,越接近0越好),表明其在平衡新知识学习和旧知识保留方面显著优于现有无样例方法。图4可视化了不同方法在各任务阶段的准确率曲线,AFT曲线在后期任务中保持最高且最平稳。
消融实验 论文在Table 2中验证了各组件的有效性:
| 方法 | UrbanSound8K ACC(%) | UrbanSound8K BWT | DCASE 2019 Task 1 ACC(%) | DCASE 2019 Task 1 BWT |
|---|---|---|---|---|
| Base | 57.474 | -0.15853 | 50.688 | -0.08508 |
| Base+AFT | 60.167 | -0.14783 | 52.396 | -0.07698 |
| Base+AFT+POS | 60.464 | -0.14726 | 52.762 | -0.07658 |
结论:单独加入AFT模块(Base+AFT)已带来显著提升。进一步加入选择性压缩(POS)在两个数据集上均获得额外的性能增益,尽管数值不大,但证实了其对稳定特征表示的贡献。
特征可视化
图1和图5通过t-SNE图提供了直观证据。
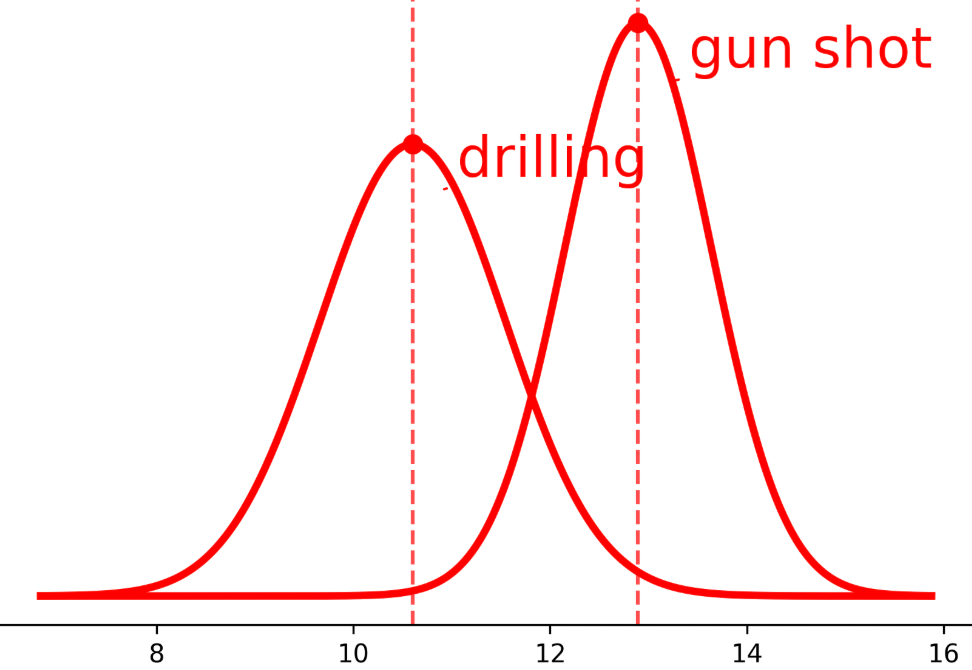 图1: 展示了在微调后,“手提钻”(jackhammer)的特征严重漂移,导致32%被误分类为“电钻”(drilling),而“街头音乐”(street_music)因特征差异大受影响小,直观说明了特征漂移问题是无样例增量学习的难点。
图1: 展示了在微调后,“手提钻”(jackhammer)的特征严重漂移,导致32%被误分类为“电钻”(drilling),而“街头音乐”(street_music)因特征差异大受影响小,直观说明了特征漂移问题是无样例增量学习的难点。
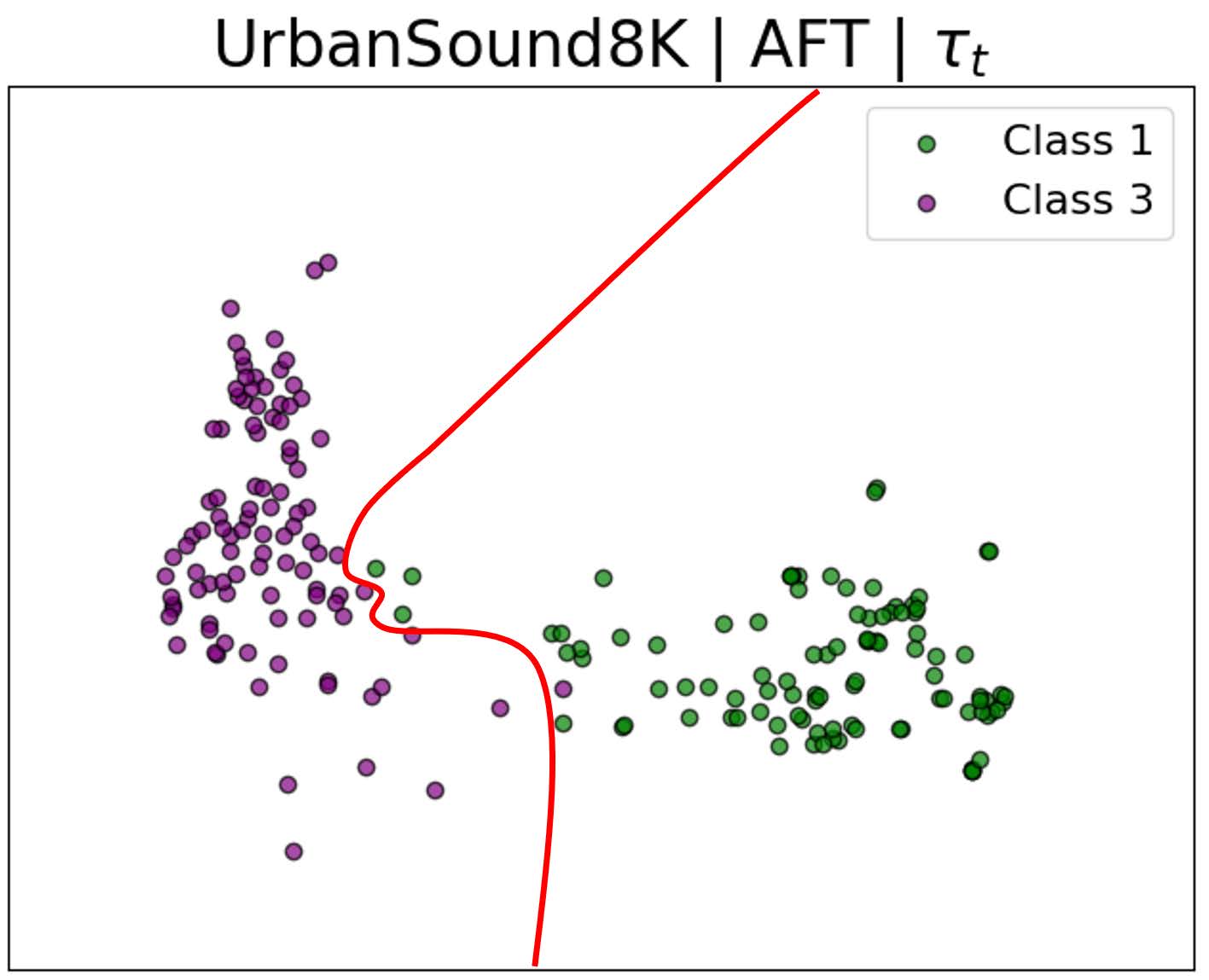 图5: 展示了两个类别特征分布的变化:(a)原始清晰边界;(b)微调后边界模糊;(c)应用AFT后,特征重新对齐,恢复了清晰的类间分离。
图5: 展示了两个类别特征分布的变化:(a)原始清晰边界;(b)微调后边界模糊;(c)应用AFT后,特征重新对齐,恢复了清晰的类间分离。
⚖️ 评分理由
- 学术质量:5.5/7:论文创新性明确,AFT网络的设计巧妙且有效解决了核心痛点(特征漂移)。技术路线正确,实验设计合理,包含对比实验、消融实验和可视化分析,证据链完整。扣分项在于对AFT网络自身的复杂性、泛化能力(如能否处理更复杂的任务序列或更相似的类别)探讨不足,且未与更多最新的无样例增量学习SOTA方法对比。
- 选题价值:1.5/2:环境声分类是音频领域的实用任务,增量学习是其必然需求。无样例设定贴合隐私和边缘计算的实际约束。选题有明确的应用价值和一定的前沿性。但该任务相对特定,影响力可能不如通用的语音或视觉任务广泛。
- 开源与复现加成:0.0/1:论文提供了主要的实验设置(数据集、骨干网络、关键超参数范围),但未公开代码、模型权重和AFT网络的具体实现细节,也未提及训练硬件。这使得完整复现存在较大不确定性,无法给予加成。