📄 Adversarial Rivalry Learning for Music Classification
#音乐分类 #音乐信息检索 #对抗学习 #注意力机制 #音频分类
✅ 6.5/10 | 前25% | #音乐分类 | #对抗学习 | #音乐信息检索 #注意力机制
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Yi-Xing Lin(中央研究院 资讯科学研究所)
- 通讯作者:未说明
- 作者列表:Yi-Xing Lin(中央研究院 资讯科学研究所)、Wen-Li Wei(中央研究院 资讯科学研究所)、Jen-Chun Lin(中央研究院 资讯科学研究所)
💡 毒舌点评
本文巧妙地将复杂的“反事实推理”优化问题,转化为两个注意力分支之间更直观的“对抗赛跑”,有效简化了超参调优,是LCA方法的一次有价值的工程化精简。然而,论文仅在几个标准音乐数据集上进行了验证,未能在更具挑战性的多模态或跨领域任务中展示其通用性,且完全未开源代码,使得这一“简单有效”的范式难以被社区快速接纳和验证。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及公开权重。
- 数据集:使用了公开数据集(Artist20, EMOPIA, FMA, GTZAN),但未说明是否提供处理后的版本或获取指南。
- Demo:未提及在线演示。
- 复现材料:论文给出了算法伪代码(Algorithm 1)和部分训练超参数(如学习率、早停步数),但未提供完整的训练配置、环境依赖、检查点或附录的详细说明。核心复现材料(代码)缺失。
- 引用的开源项目:论文提到了作为骨干模型的MERT,以及用于对比的genreMERT、Short-chunk ResNet、M2D、AST-Fusion等模型,但未明确说明是否依赖或整合了这些模型的开源实现。
📌 核心摘要
要解决什么问题:现有的Learnable Counterfactual Attention (LCA)机制为引导注意力学习,依赖于多个损失项来满足复杂的反事实标准,导致超参数调优负担重、优化不稳定,且因标准模糊而难以跨数据集/任务迁移。
方法核心是什么:提出Adversarial Rivalry Learning (ARL)范式。该范式摒弃了模糊的反事实标准,让模型的主注意力分支与一个辅助注意力分支构成动态竞争对手。在训练中,表现较差的分支通过模仿其优势对手机制(保留两个核心损失:分类损失和效应损失)进行更新,并在超越对手后交换角色。训练结束后,仅保留胜出分支用于推理。
与已有方法相比新在哪里:核心创新在于用结构化的动态竞争机制取代了LCA中基于多损失项的反事实推理。ARL将优化目标从“满足多个模糊的反事实约束”简化为“在分类任务上超越对手”,并实现了训练时参数平均和角色动态交换的机制。
主要实验结果如何:在四个音乐分类基准(Artist20, EMOPIA, FMA, GTZAN)和多种骨干模型(genreMERT, Short-chunk ResNet, M2D, AST-Fusion)上,ARL在几乎所有评估指标上均优于LCA基线,同时声称无需调优损失权重。关键结果如下:
表1:歌手识别(Artist20)任务F1分数
模型 帧级-平均 帧级-最佳 歌曲级-平均 歌曲级-最佳 genreMERT [1] 0.64 0.65 0.83 0.86 genreMERT (w/ LCA) [1] 0.66 0.68 0.84 0.89 genreMERT (w/ ARL) Ours 0.67 0.70 0.86 0.91 表2:音乐情感识别(EMOPIA)任务准确率与四象限准确率
模型 4Q准确率 Arousal准确率 Valence准确率 genreMERT (w/ LCA) [1] 0.76 0.90 0.81 genreMERT (w/ ARL) Ours 0.78 0.89 0.84 Short-chunk ResNet (w/ LCA) [1] 0.76 0.92 0.82 Short-chunk ResNet (w/ ARL) Ours 0.77 0.93 0.83 表3:流派分类(GTZAN)任务准确率
模型 准确率 M2D (w/ LCA) [1] 0.91 M2D (w/ ARL) Ours 0.93 genreMERT (w/ LCA) [1] 0.92 genreMERT (w/ ARL) Ours 0.93 实际意义是什么:提出了一种更简单、更稳定、超参数更少的注意力学习训练范式。它在不增加推理开销的前提下,提升了音乐分类性能,为改进基于注意力的音频理解模型提供了一种新的训练思路。
主要局限性是什么:1)验证范围局限于四个中等规模音乐数据集,其在更复杂场景(如长音频、多标签分类、多模态)下的有效性未明。2)动态竞争过程的内部机制(如两分支学到了什么不同的特征)缺乏深入分析。3)论文未提供任何代码或模型,严重阻碍了结果验证与方法复现。
🏗️ 模型架构
本文的ARL主要是一种训练范式,而非一个全新的、包含新组件的网络架构。它应用于已有的基于注意力的音乐分类模型(如genreMERT)之上。
整体流程与组件:
- 基础模型:采用预训练的音频模型(如MERT)作为特征提取器,后面接分类注意力分支。ARL在此基础上引入第二个结构相同的辅助注意力分支。
- ARL训练流程(见算法1):
- 初始化:将两个分支的参数初始化为对方参数的平均值,以提供一个较好的起点。
- 动态竞争循环:
- 训练阶段:一个分支被设置为“可训练”(underperforming branch),另一个被冻结(outperforming branch)。可训练分支使用两个损失进行优化:1)标准的分类交叉熵损失 \(L_{ce}(y, y_g)\),鼓励其正确分类;2)效应损失 \(L_{ce}(y_{effect}, y_g)\),其中 \(y_{effect} = y - y'\) 是可训练分支预测与冻结分支预测的差值,鼓励其超越对手。
- 角色交换:在验证集上,如果可训练分支的性能超过冻结分支,则交换它们的角色(冻结原可训练分支,解冻原冻结分支)。
- 循环终止:当可训练分支在验证集上的性能长时间(Estop步)不再提升时,循环结束。
- 最终训练:将胜出的分支(θ_win)作为最终模型,使用纯分类损失 \(L_{ce}(y, y_g)\) 进行微调,直到收敛。
- 推理:丢弃另一个分支,仅使用胜出的分支进行预测,因此无额外推理成本。
架构图说明:
论文提供了两张关键图片。
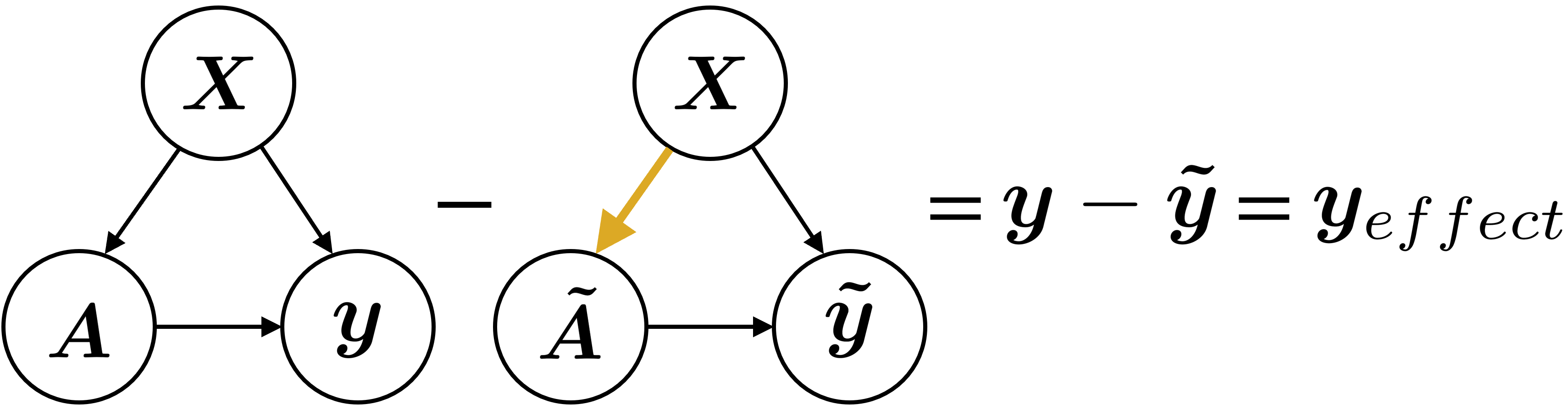 图1:LCA的因果图。它展示了特征图X如何分别生成主注意力图A和反事实注意力图Ã,两者与X共同决定预测y和反事实预测ỹ。效应yeffect定义为y与ỹ之差。ARL正是用基于分支性能对比的竞争,取代了这种通过显式定义yeffect和多个损失来满足的反事实约束。
图1:LCA的因果图。它展示了特征图X如何分别生成主注意力图A和反事实注意力图Ã,两者与X共同决定预测y和反事实预测ỹ。效应yeffect定义为y与ỹ之差。ARL正是用基于分支性能对比的竞争,取代了这种通过显式定义yeffect和多个损失来满足的反事实约束。
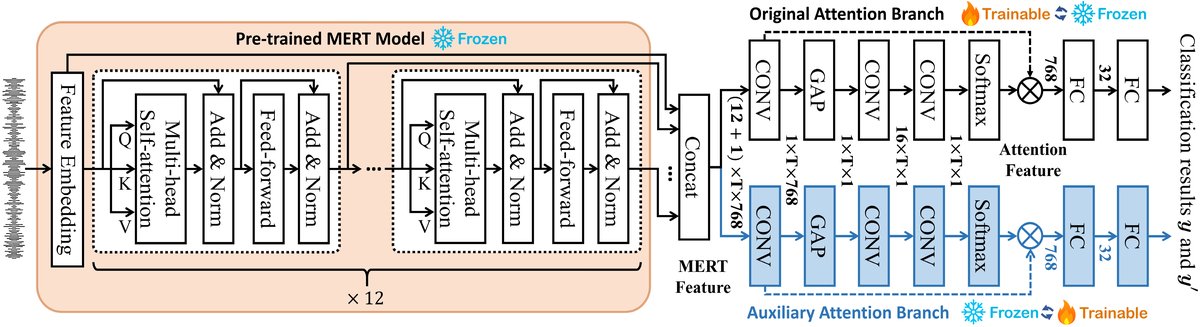 图2:集成了ARL的genreMERT架构。图示了两个并行的注意力分支(Original Branch 和 Auxiliary Branch)在训练期间的动态交互:它们竞争决定“训练者”和“冻结者”的角色,表现差的分支通过学习来超越对手。⊗表示矩阵乘法。T是序列长度。此图清晰地展示了ARL作为训练时添加的并行分支的架构关系。
图2:集成了ARL的genreMERT架构。图示了两个并行的注意力分支(Original Branch 和 Auxiliary Branch)在训练期间的动态交互:它们竞争决定“训练者”和“冻结者”的角色,表现差的分支通过学习来超越对手。⊗表示矩阵乘法。T是序列长度。此图清晰地展示了ARL作为训练时添加的并行分支的架构关系。
💡 核心创新点
用结构化竞争取代反事实推理:
- 局限:LCA依赖定义“反事实标准”(如有意义、聚焦偏置区域、与主分支不同),并通过多个损失项(分类损失、熵损失、L1距离等)来约束反事实分支,这导致目标模糊且优化冲突。
- 创新:ARL完全移除了对反事实分支的显式约束。转而构建一个简单的动态对抗环境:两个分支竞争分类准确率,失败者模仿成功者。学习目标从“满足多个抽象标准”变为“在具体任务上赢过对手”,标准清晰且无歧义。
- 收益:显著减少了损失项数量(从6个减至2个),消除了损失权重调优的负担,并避免了梯度方向的冲突,提升了训练稳定性。
动态竞争与角色交换机制:
- 局限:传统对抗学习(如GAN)中,生成器和判别器角色固定,目标相反。ARL的分支目标相同(都是分类),但角色动态互换。
- 创新:在算法1中引入“训练者”和“冻结者”的动态交换。当“训练者”性能超过“冻结者”时,角色互换,确保始终由较弱的分支向较强的分支学习,并从更强的初始化点(参数平均)重新开始挑战。这形成了一个持续的“追赶-超越”循环。
- 收益:这种机制可能促使两个分支探索特征空间的不同区域,最终使胜出的分支获得更鲁棒的注意力表示。
极简的损失设计与零推理开销:
- 局限:LCA复杂的训练设置和多个超参数限制了其通用性和易用性。
- 创新:ARL在训练循环中仅使用两个对齐的损失(分类损失和效应损失),两者都指向正确分类真标签,优化方向一致。训练结束后丢弃一个分支。
- 收益:极大简化了超参数搜索(论文声称权重为0),并保证了部署时与原始模型结构完全相同,无额外计算成本。
🔬 细节详述
- 训练数据:
- 数据集:Artist20(歌手识别), EMOPIA(情感识别), FMA-medium(流派分类), GTZAN(流派分类)。
- 预处理与数据增强:论文中未说明具体预处理步骤和数据增强策略,仅提及遵循LCA [1]的实验设置。
- 损失函数:
- 核心损失只有两个:标准分类交叉熵损失 \(L_{ce}(y, y_g)\) 和 效应损失 \(L_{ce}(y_{effect}, y_g)\),其中 \(y_{effect} = y - y'\)。在最终微调阶段,只使用 \(L_{ce}(y, y_g)\)。
- 论文明确指出,ARL移除了LCA中所有损失项的权重(λ),即默认为1,无需调优。
- 训练策略:
- Warm-up:在ARL动态竞争开始前,进行一个简短的warm-up阶段以稳定优化。
- 学习率:针对不同数据集设置不同学习率:Artist20 (10^-4), EMOPIA (10^-3), FMA (4×10^-4), GTZAN (3×10^-4)。
- 优化器:Adam优化器。
- 早停:平均耐心值 Estop = 40。
- 其他:使用Dropout防止过拟合。预训练的特征提取器(如MERT)参数被冻结。
- 关键超参数:
- 模型参数量:在多个任务中,ARL的引入不增加模型参数量(例如genreMERT with ARL仍为94.40M参数,与无ARL版本相同)。
- 其他如层数、隐藏维度等由骨干模型(MERT)决定,论文未在ARL部分单独说明。
- 训练硬件:论文中未提及。
- 推理细节:直接使用训练后胜出的单个分支进行前向传播,解码策略、温度等未说明,因为本任务是分类,非生成任务。
- 正则化/稳定技巧:
- 参数平均:在每次角色交换后,将两个分支的参数取平均,作为新“训练者”的初始化,这有助于稳定训练并加速收敛(消融实验证明了其有效性)。
- Dropout:用于防止过拟合。
📊 实验结果
论文在三个音乐分类任务(歌手识别SID、情感识别MER、流派分类MGC)的四个基准数据集上进行了充分的验证。
表1:在Artist20数据集上的歌手识别性能对比(F1 Score)
| 模型 | 帧级平均F1 | 帧级最佳F1 | 歌曲级平均F1 | 歌曲级最佳F1 | 参数量(M) |
|---|---|---|---|---|---|
| MERT [9] | 0.64 | 0.65 | 0.81 | 0.82 | 94.78 |
| genreMERT [1] | 0.64 | 0.65 | 0.83 | 0.86 | 94.40 |
| genreMERT (w/ CAL) [10] | 0.64 | 0.65 | 0.83 | 0.86 | 94.40 |
| genreMERT (w/ LCA) [1] | 0.66 | 0.68 | 0.84 | 0.89 | 94.40 |
| genreMERT (w/ ARL) Ours† | 0.67 | 0.69 | 0.86 | 0.89 | 94.40 |
| genreMERT (w/ ARL) Ours | 0.67 | 0.70 | 0.86 | 0.91 | 94.40 |
| †表示未使用分支参数平均的结果。 | |||||
| 关键结论:ARL在所有指标上优于LCA,尤其在歌曲级最佳F1上提升了2个百分点。参数平均策略带来了额外增益。 |
表2:在EMOPIA数据集上的音乐情感识别性能对比
| 模型 | 4Q准确率 | Arousal准确率 | Valence准确率 |
|---|---|---|---|
| genreMERT [1] | 0.72 | 0.89 | 0.76 |
| genreMERT (w/ LCA) [1] | 0.76 | 0.90 | 0.81 |
| genreMERT (w/ ARL) Ours | 0.78 | 0.89 | 0.84 |
| Short-chunk ResNet [3] | 0.68 | 0.89 | 0.70 |
| Short-chunk ResNet (w/ LCA) [1] | 0.76 | 0.92 | 0.82 |
| Short-chunk ResNet (w/ ARL) Ours | 0.77 | 0.93 | 0.83 |
| 关键结论:ARL在两种不同骨干网络上均超越LCA,尤其在Valence维度和整体4Q准确率上提升明显。 |
表3:在FMA-medium数据集上的流派分类性能对比
| 模型 | 准确率 | ROC-AUC | PR-AUC |
|---|---|---|---|
| Inception-ResNet-V2 [23] | 0.59 | 0.83 | 0.41 |
| KGenre [23] | 0.68 | 0.88 | 0.47 |
| genreMERT [1] | 0.68 | 0.90 | 0.51 |
| genreMERT (w/ LCA) [1] | 0.69 | 0.90 | 0.54 |
| genreMERT (w/ ARL) Ours | 0.69 | 0.91 | 0.55 |
| 关键结论:在不平衡数据集FMA上,ARL在ROC-AUC和PR-AUC这两个更鲁棒的指标上均优于LCA,显示出更好的泛化能力。 |
表4:在GTZAN数据集上的流派分类性能对比(歌曲级)
| 模型 | 准确率 | 参数量(M) |
|---|---|---|
| M2D [7] | 0.88 | 85.44 |
| M2D (w/ LCA) [1] | 0.91 | 85.44 |
| M2D (w/ ARL) Ours | 0.93 | 85.44 |
| AST-Fusion [8] | 0.87 | 89.57 |
| AST-Fusion (w/ LCA) [1] | 0.90 | 89.57 |
| AST-Fusion (w/ ARL) Ours | 0.92 | 89.57 |
| genreMERT (w/ LCA) [1] | 0.92 | 94.40 |
| genreMERT (w/ ARL) Ours | 0.93 | 94.40 |
| 关键结论:在经典的GTZAN数据集上,ARL对M2D、AST-Fusion和genreMERT三种不同架构的模型均带来稳定的1-2个百分点的准确率提升。 |
消融实验:论文在表1中通过†标记进行了一个关键消融,证明了“分支参数平均”策略的有效性(不使用时,歌曲级最佳F1从0.91降至0.89)。
⚖️ 评分理由
- 学术质量:5.5/7:论文提出了一个逻辑自洽、目标明确的新训练范式(ARL),以解决前作(LCA)的公认问题。技术实现合理,实验设计充分,在四个数据集和多种骨干模型上一致地展示了优越性。然而,创新本质上是对现有复杂机制(反事实注意力)的一种工程化简化与替代,而非提出一种全新的模型结构或理论。对ARL内部动态(如两分支差异性)的分析有待深入。
- 选题价值:1.5/2:音乐分类是MIR的基础且重要的任务,直接影响音乐推荐、检索等应用。ARL作为一种通用的训练思路,有潜力应用于其他需要注意力机制的音频任务(如语音识别、声纹识别),因此具有一定的应用价值和迁移潜力。但领域相对垂直,对整个AI社区的广泛影响力有限。
- 开源与复现加成:-0.5/1:这是本文最大的短板。论文未提供代码、模型权重、具体训练脚本或超参数配置的任何信息。这使得其他研究者无法直接验证其声称的“无损失权重调优”优势,也无法在相关工作中公平地复现和比较,极大地限制了工作的可接受度和后续价值。