📄 Adversarial Fine-Tuning on Speech Foundation Model with Vulnerable Attention Consistency Regularization for Robust Speech Recognition
#语音识别 #语音大模型 #预训练 #对抗样本 #鲁棒性
✅ 7.5/10 | 前25% | #语音识别 | #对抗样本 | #语音大模型 #预训练
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Yanyun Wang (The Hong Kong University of Science and Technology (Guangzhou))
- 通讯作者:Li Liu (The Hong Kong University of Science and Technology (Guangzhou), avrillliu@hkust-gz.edu.cn)
- 作者列表:Yanyun Wang (The Hong Kong University of Science and Technology (Guangzhou)), Baoyuan Wu (The Chinese University of Hong Kong, Shenzhen; Shenzhen Loop Area Institute), Li Liu (The Hong Kong University of Science and Technology (Guangzhou))
💡 毒舌点评
亮点:这篇工作敏锐地抓住了“防御SFM时,不能像对待传统模型那样容忍精度大幅下降”这一核心矛盾,通过CKA分析定位脆弱层并设计了针对性的双重正则化(注意力散度和特征相似性),思路清晰且可解释性强。短板:实验基本局限于Whisper模型在LibriSpeech一个数据集上的表现,对于SFM在多语言、多噪声环境下的泛化能力验证不足,使得“SOTA”的宣称在更大范围内略显底气不足。
🔗 开源详情
- 代码:论文提供了代码仓库链接:https://github.com/FlaAI/VAIR。
- 模型权重:论文中未提及公开微调后的模型权重。
- 数据集:实验使用了公开的LibriSpeech数据集,未提及VAIR是否发布新数据集。
- Demo:未提供在线演示。
- 复现材料:论文提及代码和训练细节可用,并给出了关键超参数(如λFS, λAD)的消融范围,但未提供完整的训练配置文件(如学习率具体值、batch size)或预训练检查点。
- 引用的开源项目:论文主要基于Whisper模型,因此依赖OpenAI的Whisper库。
📌 核心摘要
- 问题:语音基础模型(SFM)如Whisper易受对抗性攻击,而现有防御方法(检测、预处理、传统对抗训练)在应用于SFM时,要么无效,要么会严重损害其通过大规模预训练获得的核心实用性(Utility)。
- 方法核心:论文首次系统研究针对SFM的对抗性微调。通过CKA分析发现,SFM的对抗脆弱性集中在早期解码器层的编码器-交叉注意力中。基于此,提出VAIR(Vulnerable Attention Consistency Regularization) 方法,包含两个正则化项:注意力散度(约束对抗样本下的注意力模式与干净样本一致)和特征相似性(约束对抗样本在脆弱层(输出投影器)的特征与随机高斯噪声下的特征一致)。
- 新意:首次针对SFM的对抗鲁棒性进行微调研究;揭示了SFM脆弱层分布(早期解码器交叉注意力);创新性地结合了两种正则化,旨在同时保持SFM的实用性(借鉴随机平滑的特性)和获取对抗训练的鲁棒性增益。
- 实验结果:在Whisper的多个规模(tiny到medium)上进行实验。在标准对抗攻击(L∞ PGD, ϵ=0.002)下,VAIR将CER/WER从预训练模型的(如tiny.en: 37.78/63.20)大幅降低至(15.43/29.52),接近将鲁棒性提升一倍,同时仅引起1-2个百分点的清洁数据性能下降。VAIR在不同攻击类型(SNR-PGD)和更难的测试集(test-other)上也展现出良好的泛化能力。
- 实际意义:为安全、可靠地部署基于SFM的语音识别系统提供了一种有效且高效的微调防御方案,平衡了鲁棒性与实用性这一关键矛盾。
- 主要局限性:实验验证主要基于Whisper模型和LibriSpeech数据集,对于其他SFM架构和更广泛的真实世界数据(如多语言、远场、背景噪声)的泛化能力有待进一步研究。
| 模型 | 方法 | Clean CER↓ | Clean WER↓ | L∞PGD (ϵ=0.002) CER↓ | L∞PGD (ϵ=0.002) WER↓ |
|---|---|---|---|---|---|
| tiny.en (39M) | Pre-trained | 1.90 | 5.04 | 37.78 | 63.20 |
| + VAIR (Ours) | 2.84 | 6.80 | 15.43 | 29.52 | |
| base.en (74M) | Pre-trained | 1.56 | 3.94 | 25.09 | 42.71 |
| + VAIR (Ours) | 2.34 | 5.72 | 11.17 | 21.65 | |
| small.en (244M) | Pre-trained | 1.08 | 2.89 | 16.92 | 28.32 |
| + VAIR (Ours) | 1.43 | 3.77 | 8.40 | 16.42 |
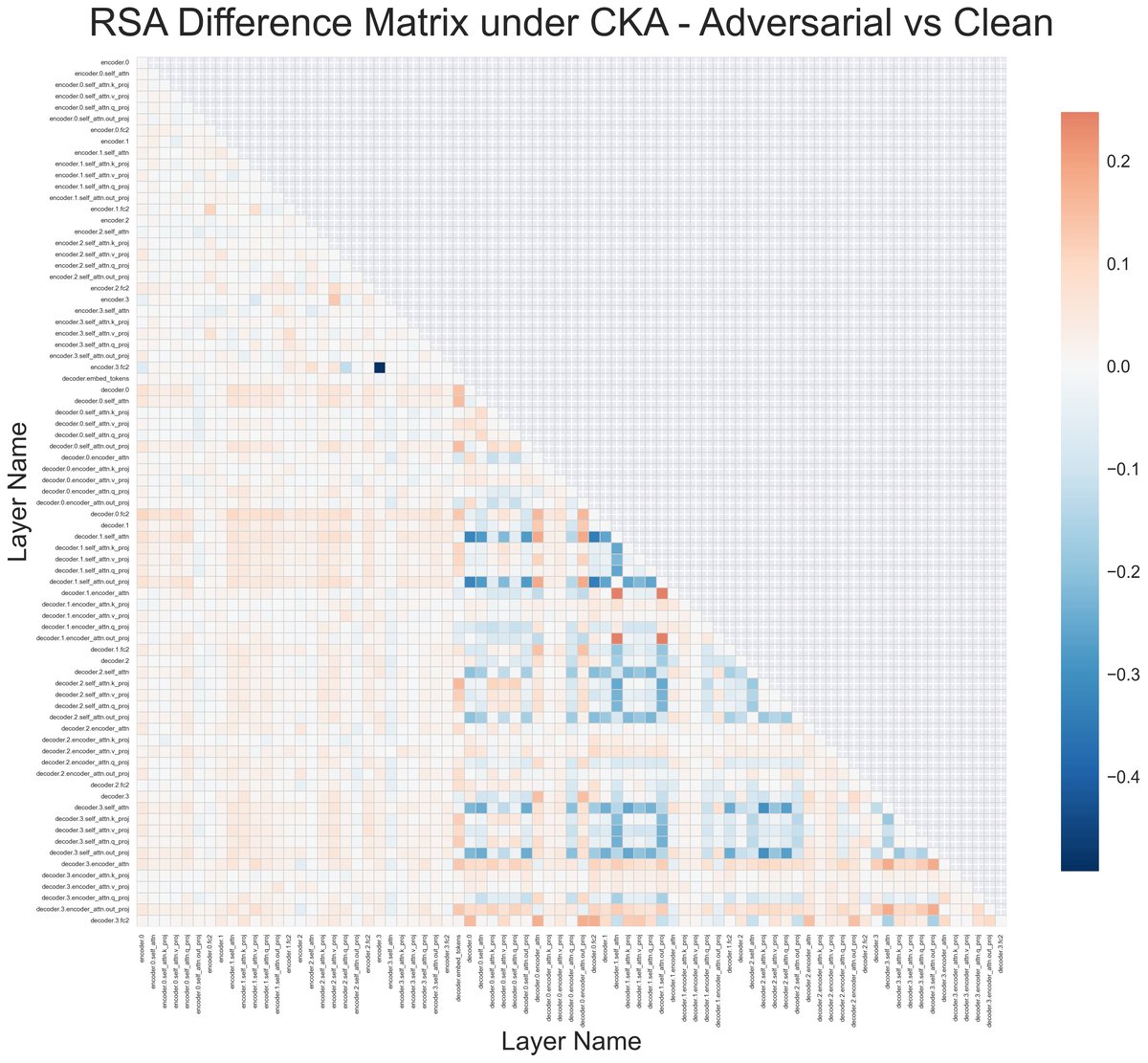 图1展示了VAIR的整体框架。模型同时处理干净波形、PGD对抗波形和高斯噪声波形。监督损失(黑色箭头)作用于干净样本,对抗损失(橙色箭头)作用于对抗样本。两个新的正则化项(蓝色箭头):① 特征相似性约束对抗样本与高斯噪声样本在脆弱层(输出投影器)的特征相似;② 注意力散度约束对抗样本与干净样本在脆弱层(早期解码器交叉注意力)的注意力分布相似。
图1展示了VAIR的整体框架。模型同时处理干净波形、PGD对抗波形和高斯噪声波形。监督损失(黑色箭头)作用于干净样本,对抗损失(橙色箭头)作用于对抗样本。两个新的正则化项(蓝色箭头):① 特征相似性约束对抗样本与高斯噪声样本在脆弱层(输出投影器)的特征相似;② 注意力散度约束对抗样本与干净样本在脆弱层(早期解码器交叉注意力)的注意力分布相似。
🏗️ 模型架构
VAIR方法并非提出一个新模型,而是一种微调策略,应用于现有的基于Transformer的语音基础模型(论文以Whisper为例)。其核心在于在标准微调和对抗训练的基础上,引入两个针对模型脆弱部分的正则化项。
整体流程与组件:
- 输入:一个干净的语音波形 \(x\)。
- 扰动生成:通过PGD方法生成对抗样本 \(x' = x + \delta\);同时生成随机高斯噪声样本 \(x'' = x + \eta\)。
- SFM前向传播:将 \(x, x', x''\) 分别输入预训练的SFM(如Whisper)。SFM包含编码器和解码器。
- 损失计算:
- 监督损失 \(L_{clean}\):基于干净样本 \(x\) 的输出和真实标签 \(y\) 计算(如负对数似然)。
- 对抗损失 \(L_{adv}\):基于对抗样本 \(x'\) 的输出和真实标签 \(y\) 计算,采用最小-最大优化框架。
- 特征相似性损失 \(L_{FS}\):约束 \(x'\) 和 \(x''\) 在脆弱层(解码器输出投影器)的特征表示的余弦相似度。
- 注意力散度损失 \(L_{AD}\):约束 \(x\) 和 \(x'\) 在脆弱层(早期解码器的编码器-交叉注意力)注意力权重的KL散度。
- 总损失:将以上四项损失加权求和进行反向传播,微调SFM参数。
脆弱层定位:论文通过CKA分析(图2)发现,对抗脆弱性主要集中在解码器第0-1层的编码器-交叉注意力和解码器第1-3层的自注意力。VAIR主要针对编码器-交叉注意力进行正则化,因为其脆弱性最先出现,且实践表明包含后续自注意力收益不大。
 图2展示了CKA分析结果。左/中图分别显示从干净数据到高斯/PGD噪声数据的CKA变化。右图显示两种变化的差异。结果清晰表明,无论是哪种噪声,解码器早期层的编码器-交叉注意力都是变化最剧烈的脆弱区域。
图2展示了CKA分析结果。左/中图分别显示从干净数据到高斯/PGD噪声数据的CKA变化。右图显示两种变化的差异。结果清晰表明,无论是哪种噪声,解码器早期层的编码器-交叉注意力都是变化最剧烈的脆弱区域。
💡 核心创新点
- 首次系统研究针对SFM的对抗性微调:明确指出在防御SFM时,保持其预训练获得的“实用性”与提升“鲁棒性”同等重要,这是一个新的研究范式。
- 揭示SFM特有的脆弱性分布:通过CKA分析,可视化并证实了在语音基础模型中,对抗扰动的影响首先体现在解码器早期的交叉注意力层,这与传统ASR模型可能不同,为设计针对性防御提供了关键洞察。
- 提出VAIR双重正则化框架:
- 注意力散度(Attention Divergence):直接约束最脆弱的注意力层,使其对干净和对抗输入的注意力模式保持一致。
- 特征相似性(Feature Similarity):巧妙地引入高斯噪声作为“锚点”,引导对抗样本在脆弱层的特征向随机化(RS)行为靠拢,旨在融合RS保持实用性的优点和AT提升鲁棒性的优点。
🔬 细节详述
- 训练数据:使用LibriSpeech的
train-clean-100子集(约100小时)进行微调。使用dev-clean进行早停。未提供数据增强细节。 - 损失函数:
- \(L_{clean}\) 和 \(L_{adv}\):标准的序列到序列损失(推测为负对数似然)。
- \(L_{FS}\):1减去特征向量的余弦相似度,平均脆弱层集合内的结果。脆弱层 \(\Gamma_{FS}\) 指定为解码器的输出投影器层。
- \(L_{AD}\):脆弱层注意力图的KL散度,对多头注意力平均后,再对脆弱层集合平均。脆弱层 \(\Gamma_{AD}\) 指定为解码器0-1层的编码器-交叉注意力。
- 总损失:\(L_{total} = L_{clean} + \lambda_{Adv} \cdot L_{adv} + \lambda_{FS} \cdot L_{FS} + \lambda_{AD} \cdot L_{AD}\)。
- 训练策略:论文提供了训练代码链接,但正文中未详细说明具体的优化器(如AdamW)、学习率、批次大小、训练轮数等。从消融图(图3d)看,学习率是关键超参数。
- 关键超参数:
- \(\lambda_{Adv}\):平衡对抗训练的强度(消融图3e)。
- \(\lambda_{FS}\) 和 \(\lambda_{AD}\):控制两个正则化项的强度(消融图3b, 3c)。论文未给出最终选定的具体数值。
- 对抗扰动预算 \(\epsilon\):L∞-PGD攻击使用 \(\epsilon=0.002\)(标准)和 \(0.005\)(极端)。
- 训练硬件与时间:论文中未说明。
- 推理细节:论文中未明确说明解码策略(如beam search的beam size)。使用标准的Whisper推理流程。
- 正则化技巧:除了VAIR,论文在图3f中展示了额外的数据增强(如时间掩码)可以进一步帮助保持实用性,但这不是VAIR的核心部分。
📊 实验结果
主要Benchmark与结果:所有实验在LibriSpeech test-clean 上进行,评估指标为CER和WER。表1为最核心的结果表。
| 模型 | 方法 | Clean CER↓ | Clean WER↓ | L∞PGD (ε=0.002) CER↓ | L∞PGD (ε=0.002) WER↓ | L∞PGD (ε=0.005) CER↓ | L∞PGD (ε=0.005) WER↓ | SNR-PGD (40dB) CER↓ | SNR-PGD (40dB) WER↓ | SNR-PGD (30dB) CER↓ | SNR-PGD (30dB) WER↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| tiny.en | Pre-trained | 1.90 | 5.04 | 37.78 | 63.20 | 58.54 | 91.46 | 22.26 | 37.76 | 35.19 | 57.66 |
| + VAIR | 2.84 | 6.80 | 15.43 | 29.52 | 35.96 | 60.01 | 10.51 | 20.23 | 20.34 | 35.11 | |
| base.en | Pre-trained | 1.56 | 3.94 | 25.09 | 42.71 | 51.09 | 81.15 | 15.23 | 27.18 | 28.91 | 48.29 |
| + VAIR | 2.34 | 5.72 | 11.17 | 21.65 | 25.97 | 44.65 | 8.52 | 15.88 | 14.49 | 25.96 | |
| small.en | Pre-trained | 1.08 | 2.89 | 16.92 | 28.32 | 31.53 | 52.25 | 7.48 | 13.82 | 14.11 | 24.69 |
| + VAIR | 1.43 | 3.77 | 8.40 | 16.42 | 21.61 | 37.53 | 5.27 | 10.90 | 10.85 | 19.91 |
与SOTA差距:论文指出,由于是首个针对SFM的微调防御工作,没有直接的先前工作可对比。因此,它自己实现了两个基线:RS(随机平滑)和PGD-AT(标准对抗训练)。结果显示,VAIR在标准攻击(L∞PGD, ε=0.002)下取得最佳(最低)的CER/WER,同时清洁性能损失远小于PGD-AT。
消融研究:
- 方法组件消融(图3a):单独使用FS或AD都有帮助,但组合使用(VAIR)效果最好。
- 超参数影响(图3b, c):λFS和λAD的强度对性能有显著影响,存在最优值。
- 学习率影响(图3d):适当的学习率至关重要。
- 对抗损失强度(图3e):λAdv需要平衡清洁性能和鲁棒性。
- 数据增强(图3f):额外的掩码增强可以进一步改善清洁性能。
泛化能力:
- 不同攻击:在SNR-PGD攻击下(采用自适应L2约束),VAIR同样展现出强大的鲁棒性。
- 不同数据:在更困难的
test-other子集上(包含口音、噪声等),VAIR依然能有效提升鲁棒性(表2)。
| 方法 | 数据集 | Clean CER↓ | Clean WER↓ | L∞PGD (ε=0.002) CER↓ | L∞PGD (ε=0.002) WER↓ |
|---|---|---|---|---|---|
| tiny.en Pre-trained | test-other | 7.30 | 14.23 | 61.65 | 93.49 |
| tiny.en + VAIR | test-other | 8.90 | 17.79 | 38.21 | 61.63 |
 图3为一系列消融研究图表,验证了VAIR各个组件(FS、AD)的有效性,以及关键超参数(λFS, λAD, 学习率, λAdv)对性能的影响,并展示了额外数据增强的效果。
图3为一系列消融研究图表,验证了VAIR各个组件(FS、AD)的有效性,以及关键超参数(λFS, λAD, 学习率, λAdv)对性能的影响,并展示了额外数据增强的效果。
⚖️ 评分理由
- 学术质量:6.5/7:论文动机明确,首次研究问题具有开创性;通过CKA分析定位脆弱层并设计针对性正则化,方法具有可解释性;实验设计全面,包含多模型规模、多攻击类型、充分消融和泛化测试,结果支持其论点。扣分点在于��创新本质上是两种现有正则化技术(约束注意力、约束特征)的组合与适配,理论深度有限;实验主要在单一模型家族(Whisper)和单一数据集(LibriSpeech)上验证,泛化性论证不够充分。
- 选题价值:1.5/2:选题高度前沿,直接针对大模型时代的核心安全挑战(鲁棒性),对推动安全、可靠的语音AI应用有重要价值。扣分点在于,目前仅解决了Whisper这一类模型的问题,能否扩展到其他SFM(如非自回归模型)尚不明确。
- 开源与复现加成:+0.5/1:论文明确提供了代码仓库链接(GitHub),并给出了训练设置的关键点和超参数范围,有利于复现。但未提供训练好的模型权重和完整的配置文件,增加了完全复现的难度。