📄 Advancing LLM-Based Multi-Channel Multi-Speaker Speech Recognition with Global Cross-Channel Attention and Sentence-Ordered First-In First-Out Serialized Output Training
#语音识别 #语音大模型 #多通道 #预训练 #端到端
✅ 7.5/10 | 前25% | #语音识别 | #语音大模型 | #多通道 #预训练
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Genshun Wan(中国科学技术大学 & 科大讯飞研究院)
- 通讯作者:Jia Pan(科大讯飞研究院)
- 作者列表:Genshun Wan (中国科学技术大学 & 科大讯飞研究院),Lijuan Liu (中国科学技术大学 & 科大讯飞研究院),Changfeng Xi (科大讯飞研究院),Hang Chen (中国科学技术大学),Xindi Yu (科大讯飞研究院),Jia Pan (科大讯飞研究院),Jun Du (中国科学技术大学),Zhongfu Ye (中国科学技术大学)
💡 毒舌点评
亮点: 论文首次将大语言模型(LLM)系统性地引入多通道多说话人语音识别,并针对该任务的独特性(如说话人顺序、多通道输入)设计了“句子有序FIFO SOT”和“全局跨通道注意力(GCCA)”两个关键组件,实现了从基线到最终系统CER超过55%(重叠)的大幅性能飞跃。 短板: 整个评估完全基于未公开的内部会议数据集,缺乏在学术界公认的公开多通道基准上的验证,这使得其宣称的“强泛化性”说服力大打折扣,也让其他研究者难以复现和比较,显著降低了论文的公共价值。
🔗 开源详情
- 代码:论文中未提及代码链接或开源计划。
- 模型权重:未提及公开模型权重。
- 数据集:使用的是内部数据集,仅提及“一个子集已发布用于MISP 2025挑战赛”,但未说明如何获取本文实验所用的完整数据集。
- Demo:未提供在线演示。
- 复现材料:提供了一些训练细节(如优化器、学习率、epoch数),但缺少关键信息(如完整的训练超参数、硬件规格、数据预处理脚本)。
- 论文中引用的开源项目:仅在方法部分引用了LoRA(Low-Rank Adaptation)作为微调技术,未提及依赖其他特定的开源工具或模型库。
📌 核心摘要
本文旨在解决多通道多说话人语音识别中面临的数据稀缺、复杂声学环境和跨通道依赖建模难题。其方法核心是首次构建一个整合了大语言模型(LLM)的端到端框架,并提出了三项关键创新:1)采用“单通道预训练-多通道微调”的两阶段策略以缓解数据稀缺;2)设计了句子有序的FIFO序列化输出训练(SOT)方法,以保持自然的对话时间顺序;3)提出了支持可变通道数输入的全局跨通道注意力(GCCA)机制。与以往的波束成形或多通道MFCCA模型相比,本方法在LAKT策略、输出排序逻辑和特征融合方式上均实现了创新。在内部的MISP-Meeting数据集上,最终系统将基线ASR的字错误率(CER)在单人测试集和重叠测试集上分别降低了78.5%和55.4%,并展示了对不同输入通道配置的良好泛化能力。该工作的实际意义在于为会议转写等真实场景提供了更准确、健壮的识别框架。其主要局限性在于实验评估完全依赖未公开的内部数据,缺乏在公开基准上的公平比较,且未开源任何代码或数据,限制了其可复现性和影响力。
🏗️ 模型架构
本文提出的框架分为两个训练阶段,整体架构如图1所示。
第一阶段:单通道单说话人预训练(Stage 1)
- 流程:单通道音频输入(X)经过一个基于Conformer的编码器提取声学特征,随后通过一个投影器(Projector)调整维度以匹配LLM的输入要求,最终送入大语言模型(LLM)解码器生成文本输出。
- 组件与功能:
- 编码器:采用与MFCCA相同的架构,包含11个Conformer块,每块有4头多头自注意力和256维度的头维度,用于提取高级声学特征。
- LLM解码器:使用预训练的Spark 2.6B大语言模型。为适应语音任务,采用LoRA(Low-Rank Adaptation)对LLM的注意力机制进行参数高效微调,LoRA的秩和缩放因子均设为16。
- 投影器:连接编码器和LLM,进行特征维度映射。
- 动机:通过在大规模(10,000小时)单通道语音数据上预训练,让模型习得基础的声学-语言模型能力,为后续的多通道多说话人任务提供强初始化。
第二阶段:多通道多说话人微调(Stage 2)
- 流程:多通道音频输入(每个通道独立通过共享的编码器)产生多组通道特征(X1, X2, …, XC)。这些特征首先送入全局跨通道注意力(GCCA)模块进行融合,得到一个全局的跨通道融合特征。该融合特征再经过投影器,送入(第一阶段预训练并初始化的)LLM解码器,最终生成包含说话人变化符号(
)的序列化输出。 - 关键创新组件:全局跨通道注意力(GCCA)
- 动机:传统平均或卷积融合方法难以捕获全局跨通道关系,且对输入通道数量敏感。GCCA旨在以一种灵活、全局的方式融合任意数量的通道特征。
- 机制(如图1右侧所示):对于每一帧的C个通道特征,增加一个可学习的全局令牌(global token),形成C+1个令牌。加入位置编码后,通过一个3层的Transformer进行跨通道的自注意力计算。最终,取对应全局令牌位置的输出作为该帧的融合表示。
- 优势:1)通过自注意力机制建模了所有通道间的全局依赖关系;2)由于全局令牌不依赖于具体通道数,因此支持可变数量的输入通道,无需填充;3)训练时随机丢弃部分通道(通道丢弃策略),进一步增强了模型对不同通道配置的鲁棒性。
- 输出与解码:LLM解码器在微调阶段采用本文提出的“句子有序FIFO SOT”策略,其输出序列按照对话中句子的绝对开始时间排序,并在说话人变化时插入
符号。
 图1 展示了本文提出的两阶段训练框架。Stage1为单通道数据预训练架构,Stage2为本文提出的多通道训练框架,其中包含了GCCA模块。
图1 展示了本文提出的两阶段训练框架。Stage1为单通道数据预训练架构,Stage2为本文提出的多通道训练框架,其中包含了GCCA模块。
💡 核心创新点
首次系统引入LLM至多通道多说话人ASR(LLM-LAKT):
- 之前局限:传统ASR解码器(如RNN-T)在长程语义和上下文建模能力上弱于LLM,难以充分处理复杂的多人对话。
- 如何起作用:采用预训练LLM作为解码器,并通过LoRA进行适配。更重要的是,提出了“单通道预训练-多通道微调”的两阶段策略,将LLM强大的语言知识和从大规模单通道数据中学到的声学先验,迁移到数据稀缺的多通道多说话人任务中。
- 收益:在Table 1中,无论输入是单通道还是多通道,使用LLM解码的MCMS-LLM模型在单人和重叠测试集上均显著优于MFCCA模型(例如,8通道输入下,单人CER从20.76%降至17.73%)。预训练策略进一步带来了超过50%的相对CER降低。
句子有序FIFO序列化输出训练(Sentence-Ordered FIFO SOT):
- 之前局限:主流的Speaker-Ordered FIFO SOT根据说话人启动时间排序,但在推理时必须实时检测端点并保持说话人关联,导致训练-推理不匹配。更重要的是,它打乱了对话的自然时间顺序(即“先说后回应”的因果逻辑),这与LLM对时序信息的敏感性不符。
- 如何起作用:提出按句子的绝对起始时间对所有说话人的话语进行全局排序,形成输出序列。在训练和推理时,都严格遵循这一时间顺序。
- 收益:如图3所示,在重叠测试集上,当输入8通道时,该方法相比Speaker-Ordered SOT将CER从25.84%进一步降低至24.41%,证明了其在多说话人场景下对保持语义连贯性和时间一致性的有效性。
全局跨通道注意力机制(GCCA):
- 之前局限:早期的平均或拼接方法无法建模通道间的复杂关系。近期的卷积融合方法(如MFCCA)依赖局部感受野,难以捕捉远距离麦克风之间的全局依赖,且对输入通道数固定不友好,需要填充。
- 如何起作用:引入可学习的全局令牌,与所有通道特征一起进行自注意力计算,使每个通道都能与其他所有通道交互。该令牌的输出作为全局融合表示。
- 收益:如图4所示,在8通道输入下,GCCA相比通道平均、CCA等方法,将单人和重叠测试集的CER进一步分别降至4.47%和22.75%。更重要的是,该方法在不同输入通道数(1,2,4,8)下均表现优越,展现了强大的泛化能力。
🔬 细节详述
- 训练数据:
- 预训练:内部构建的10,000小时单通道数据,涵盖会议、客服、影视等场景。预处理使用了CDDMA波束成形增强音频质量。
- 微调:内部8通道音频-视觉Mandarin会议语料库(仅使用音频)。训练集包含885场会议,约1039.57小时(清洗后);测试集包含49场会议,约30.82小时。对训练/测试集进行了VAD处理,每段最长30秒,包含单说话人和多说话人场景。训练集重叠语音比例为14.53%,测试集为27.4%。
- 损失函数:
- 第一阶段(预训练):标准的交叉熵损失(公式1),预测目标为参考文本。
- 第二阶段(微调):序列化输出训练(SOT)的交叉熵损失(公式2),预测目标为按句子起始时间排序后的、包含
符号的文本序列。
- 训练策略:
- 优化器:SGD(随机梯度下降)。
- 学习率调度:
- 第一阶段:初始学习率0.005,衰减至1e-4。
- 第二阶段:初始学习率5e-4,衰减至1e-5。
- 训练轮次:预训练50 epochs,微调10 epochs。
- 硬件:使用8块GPU进行训练。
- Batch size:未说明。
- 关键超参数:
- 编码器:11层Conformer,4头注意力,头维度256。
- LLM:Spark 2.6B。
- GCCA模块:3层Transformer,维度512,内部维度1024,8头注意力。
- LoRA:秩=16,缩放因子=16。
- GCCA训练:通道丢弃概率20%,随机保留1到C-1个通道。
- 推理细节:未明确说明解码策略(如beam search的大小)。
- 评估指标:字符错误率(CER)。注意,CER是基于“句子有序FIFO”的真实标签计算的。
📊 实验结果
主要对比实验(Table 1):在内部MISP-Meeting测试集上,与Beamformer和MFCCA基线进行对比。
| Model | Input-Channel | Mono Pretraining | LLM decoding | Single-speaker CER (%) | Overlap CER (%) |
|---|---|---|---|---|---|
| Beamformer | 1 | × | × | 24.08 | 53.72 |
| MFCCA | 8 | × | × | 20.76 | 50.99 |
| Single channel pretraining | 1 | ✓ | ✓ | 11.99 | - |
| MCMS-LLM | 8 | × | ✓ | 17.73 | 47.41 |
| MCMS-LLM | 8 | ✓ | ✓ | 5.12 | 25.84 |
| MCMS-LLM+Sentence-ordered SOT+GCCA | 8 | ✓ | ✓ | 4.47 | 22.75 |
关键发现:
- LLM与预训练有效性:仅使用LLM解码(MCMS-LLM w/o pretrain)已优于MFCCA。加入单通道预训练后(MCMS-LLM w/ pretrain),性能大幅提升(例如,8通道输入下单人CER从17.73%降至5.12%)。
- 最终系统性能:整合所有创新(Sentence-ordered SOT + GCCA)后,系统取得最佳性能。相比最强基线MFCCA,在单人测试集上CER相对降低约 78.5% (20.76% → 4.47%),在重叠测试集上相对降低约 55.4% (50.99% → 22.75%)。
- 通道鲁棒性:预训练模型在输入降为单通道时,性能依然良好(单人CER为6.37%,接近8通道的5.12%),解决了以往多通道模型处理单通道输入时的鲁棒性问题。
消融实验:
- Sentence-Ordered SOT:如图3所示,在重叠测试集(b)上,Sentence-Ordered SOT在所有通道配置下均优于Speaker-Ordered SOT,证明了保持时间顺序对多说话人场景的益处。
- GCCA模块:如图4所示,GCCA在单人(a)和重叠(b)测试集上,在所有通道数(1,2,4,8)下均取得了最低的CER。它显著优于通道平均、通道拼接+注意力(CCA)等方法。例如,在8通道重叠测试集上,GCCA将CER从24.41%(平均)降至22.75%。
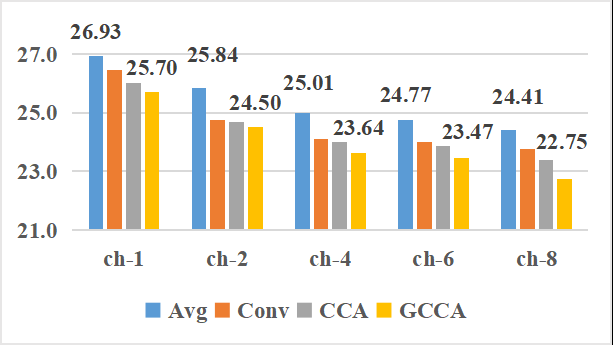 图3 比较了两种SOT方法在不同输入通道数下的CER。在单说话人测试集(a)上二者接近,在重叠测试集(b)上,句子有序SOT(橙色线)一致优于说话人有序SOT(蓝色线)。
图3 比较了两种SOT方法在不同输入通道数下的CER。在单说话人测试集(a)上二者接近,在重叠测试集(b)上,句子有序SOT(橙色线)一致优于说话人有序SOT(蓝色线)。
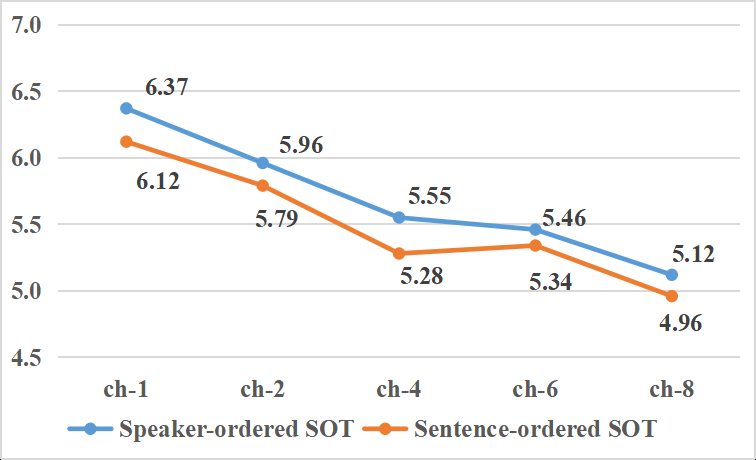 图4 比较了四种通道融合方法在不同输入通道数下��CER。GCCA(红色线)在所有情况下均取得最低的错误率,展现了优越性和泛化能力。
图4 比较了四种通道融合方法在不同输入通道数下��CER。GCCA(红色线)在所有情况下均取得最低的错误率,展现了优越性和泛化能力。
⚖️ 评分理由
- 学术质量:6.5/7
- 创新性:将LLM引入特定任务并针对其特点设计新SOT和通道融合方法,具有明确的创新性。
- 技术正确性:方法设计合理,消融实验充分证明了各组件的有效性。
- 实验充分性:对比了多种基线,进行了详细的消融实验,数据充足。
- 证据可信度:实验结果提升显著。主要扣分点:评估完全在未公开的内部数据集上进行,缺乏在公开标准基准上的验证,使得结论的普适性和可比较性存疑。
- 选题价值:1.5/2
- 前沿性:多通道多说话人识别是活跃的研究领域,集成LLM是当前热点,选题具有时效性。
- 潜在影响与应用:直接应用于会议记录、在线协作等场景,具有明确的工业应用价值。
- 读者相关性:对从事语音识别、尤其是会议转写系统研究的读者有较高价值。
- 开源与复现加成:-0.5/1
- 论文未提供代码、模型权重、训练数据或详细的复现配置(如完整的超参数列表)。
- 这严重影响了该工作的可复现性和社区价值,应予以扣分。