📄 Addressing Gradient Misalignment in Data-Augmented Training for Robust Speech Deepfake Detection
#语音伪造检测 #数据增强 #鲁棒性 #梯度优化
✅ 7.0/10 | 前25% | #语音伪造检测 | #数据增强 | #鲁棒性 #梯度优化
学术质量 7.0/7 | 选题价值 2.0/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Duc-Tuan Truong(南洋理工大学,新加坡)
- 通讯作者:Ruijie Tao(新加坡国立大学)、Kong Aik Lee(香港理工大学)(论文中标注为共同通讯作者)
- 作者列表:Duc-Tuan Truong(南洋理工大学)、Tianchi Liu(新加坡国立大学)、Junjie Li(香港理工大学)、Ruijie Tao(新加坡国立大学)、Kong Aik Lee(香港理工大学)、Eng Siong Chng(南洋理工大学)
💡 毒舌点评
亮点:论文首次敏锐地指出了“数据增强双路径训练中同一语句的原始与增强版本梯度冲突”这一被忽视却普遍存在的现象,并设计了优雅的DPDA框架加以解决,理论分析(损失曲面可视化)与实验证据结合得很有说服力。短板:核心的“梯度对齐”技术(PCGrad等)是直接“借用”自多任务学习领域,本文的创新更多在于问题发现和技术迁移应用,而非算法本身的原创性突破。
🔗 开源详情
- 代码:论文明确提供了代码仓库链接:
github.com/ductuantruong/dpda_ga。 - 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:论文使用的ASVspoof2019 LA、ASVspoof2021 DF、In-the-Wild、FoR均为公开数据集,但未说明具体获取方式。
- Demo:未提供在线演示。
- 复现材料:提供了代码仓库,是核心复现材料。论文描述了模型架构、数据增强方法(RawBoost配置4)、训练策略(如早停、批大小)等关键细节,但缺少如学习率、优化器、具体硬件等训练超参数。
- 引用的开源项目:论文依赖并提及了XLSR模型(来自Hugging Face)、RawBoost增强工具、以及作为对比的多种SDD模型代码。
📌 核心摘要
本文针对语音深度伪造检测(SDD)模型在使用数据增强(DA)训练时,原始输入与增强输入反向传播梯度方向不一致(冲突)导致优化矛盾、影响模型泛化的问题,提出了一种双路径数据增强训练框架与梯度对齐方法。该框架将每个训练语句同时通过原始路径和增强路径输入共享模型,计算损失后,在梯度更新前使用PCGrad等梯度对齐技术处理冲突。主要创新在于首次在SDD领域系统研究并量化了DA训练中的梯度冲突(约25%的迭代存在冲突),并通过损失曲面可视化证明冲突源于不同的损失景观。实验表明,该方法在XLSR-AASIST、XLSR-Conformer-TCM、XLSR-Mamba三种架构上,配合RawBoost等多种增强方法,在ASVspoof2021-DF、In-the-Wild、FoR等挑战性测试集上均能稳定提升性能。例如,在XLSR-Conformer-TCM上,使用PCGrad在ITW数据集上将EER从7.97%降至6.48%,相对降低约18.69%。该方法能加速收敛(提前至第4个epoch达到最低验证损失)。其实际意义在于提供了一种即插即用、与模型和增强技术无关的训练优化策略,以提升SDD的鲁棒性。局限性在于主要从经验层面分析,缺乏对梯度冲突产生理论条件的深层探究,且梯度对齐技术本身非本文原创。
🏗️ 模型架构
本文的核心并非提出一个新的SDD检测模型,而是提出一个训练框架(DPDA),该框架可应用于各种现有的SDD模型架构。
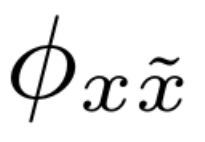 架构流程说明:
架构流程说明:
- 双路径输入:对于一个训练语句,同时生成其原始波形
x和增强波形˜x(如通过RawBoost处理)。 - 共享模型:两个输入分别或以mini-batch形式送入同一个待训练的SDD模型
f(θ)(如XLSR-Conformer-TCM),计算各自的损失L(x)和L(˜x)。 - 梯度计算与对齐:分别计算损失对模型参数
θ的梯度gx和g˜x。在梯度对齐模块中,根据预设准则(如PCGrad、GradVac或CAGrad)判断两个梯度是否存在冲突,并进行调整,得到对齐后的梯度g'x和g'˜x。 - 参数更新:将对齐后的梯度聚合(如平均),用于更新模型参数
θ。 关键组件:梯度对齐方法是框架的核心。论文对比了三种:
- PCGrad:当两个梯度内积为负(方向冲突)时,将每个梯度投影到另一个梯度的法平面上,移除冲突分量。
- GradVac:不仅消除冲突,还主动通过线性组合将梯度间的余弦相似度提升至一个自适应目标值。
- CAGrad:求解一个凸优化问题,寻找一个靠近原始聚合梯度
g0,同时能同时改善两个损失(即与gx和g˜x的内积均为正)的更新方向g。 该框架是模型无关的,旨在解决因DA引入的优化不稳定性。
💡 核心创新点
- 问题发现与量化:首次在语音深度伪造检测领域,系统性地发现并量化了“原始输入与增强输入梯度冲突”这一训练中的普遍现象(约25%的迭代发生冲突),并通过损失曲面可视化揭示了冲突的几何根源。
- 提出DPDA训练框架:设计了一个简洁有效的双路径训练框架,将同一语句的原始和增强版本并行处理,为研究和解决梯度冲突提供了标准化的设置。
- 技术迁移与验证:将多任务学习中成熟的梯度对齐技术(PCGrad等)成功迁移到SDD的数据增强训练场景,���验证了其有效性和普适性(跨模型、跨增强方法)。
- 性能与效率双重收益:应用梯度对齐后,不仅模型在多个挑战性数据集上的检测性能(EER)获得稳定提升,训练的收敛速度也显著加快(例如,XLSR-Conformer-TCM的收敛epoch从14提前至4)。
🔬 细节详述
- 训练数据:在ASVspoof2019 Logical Access (LA)数据集上训练和验证。该数据集包含真实(bona fide)和多种TTS/VC系统生成的伪造语音。
- 数据增强:主要使用RawBoost(配置4)对原始波形进行信号级失真。也验证了与MUSAN噪声、RIR(房间脉冲响应)增强方法的组合。
- 损失函数:论文未明确说明使用的具体损失函数,但根据任务性质(二分类)和对比方法(XLSR-AASIST等),推测使用标准的二元交叉熵损失(BCE Loss)。
L(x)和L(˜x)均为该损失。 - 训练策略:
- 优化器:论文未明确说明,可能沿用各基线模型的设置。
- 学习率、Warmup:论文未明确说明。
- Batch Size:由于双路径需存储两份梯度,为适应GPU内存,将单路径训练的batch size从20减半至10(包含5个原始样本和5个增强样本)。
- 训练轮数:采用早停策略,当验证损失连续7个epoch未改善时停止训练。
- 模型架构:验证了三种不同架构:XLSR-AASIST(自监督特征+注意力统计池化+时序卷积网络)、XLSR-Conformer-TCM(自监督特征+Conformer+时序通道建模)、XLSR-Mamba(自监督特征+双向状态空间模型)。
- 关键超参数:梯度对齐方法PCGrad无额外超参数。CAGrad中的
c在论文中未指定具体值。 - 训练硬件:未说明。
- 推理细节:未说明。推理时仅使用原始语音输入。
- 正则化/稳定训练技巧:核心稳定技巧即为梯度对齐。
📊 实验结果
主要基准与结果:在三个挑战性测试集上评估:ASVspoof2021-DF(模拟真实条件)、In-the-Wild (ITW)(真实媒体音频)、Fake-or-Real (FoR)(播客音频)。主要指标为等错误率(EER)。
表1:不同梯度对齐方法比较(XLSR-Conformer-TCM)
| 系统 | EER (%) | ||
|---|---|---|---|
| 21DF | ITW | FoR | |
| DPDA训练基线 | 2.11 | 7.97 | 5.31 |
| + PCGrad [15] | 1.81 | 6.48 | 4.47 |
| + GradVac [16] | 1.83 | 7.09 | 4.81 |
| + CAGrad [17] | 1.92 | 7.45 | 4.23 |
| 结论:三种梯度对齐方法均优于无对齐的基线。PCGrad在大多数情况下表现最佳。 |
表2:跨模型架构验证(使用PCGrad)
| 系统 | EER (%) | ||
|---|---|---|---|
| 21DF | ITW | FoR | |
| XLSR-AASIST [23] | 3.69 | 10.46 | 7.46* |
| w/ DPDA训练 | 1.87 | 6.20 | 4.60 |
| + PCGrad | 2.13 | 5.42 | 3.04 |
| XLSR-Conformer-TCM [24] | 2.06 | 7.79 | 10.68* |
| w/ DPDA训练 | 2.11 | 7.97 | 5.31 |
| + PCGrad | 1.81 | 6.48 | 4.47 |
| XLSR-Mamba [25] | 1.88 | 6.70 | 6.71* |
| w/ DPDA训练 | 2.31 | 7.62 | 5.39 |
| + PCGrad | 1.74 | 6.43 | 4.86 |
| 结论:梯度对齐在三个模型上均能克服DPDA基线可能带来的性能下降,并进一步提升性能,证明了方法的普适性。*表示其他论文报告的结果。 |
表3:不同数据增强方法下的效果(XLSR-Conformer-TCM)
| DA类型 | 系统 | EER (%) | ||
|---|---|---|---|---|
| 21DF | ITW | FoR | ||
| RawBoost | DPDA训练 | 2.11 | 7.97 | 5.31 |
| + PCGrad | 1.81 | 6.48 | 4.47 | |
| MUSAN & RIR | DPDA训练 | 5.45 | 23.04 | 12.02 |
| + PCGrad | 3.81 | 19.43 | 8.05 | |
| MUSAN & RIR + RawBoost | DPDA训练 | 1.78 | 8.10 | 2.83 |
| + PCGrad | 1.63 | 7.19 | 2.91 | |
| 结论:梯度对齐在多种增强策略下均有效。RawBoost增强本身效果最强。 |
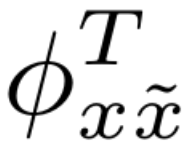 图2说明:展示了训练过程中原始输入和增强输入的损失(log10尺度)和梯度范数的平均值。可以清晰看到,增强输入的损失和梯度范数始终高于原始输入,这种不平衡可能导致模型更新被增强输入主导。这为梯度冲突提供了直观证据。
图2说明:展示了训练过程中原始输入和增强输入的损失(log10尺度)和梯度范数的平均值。可以清晰看到,增强输入的损失和梯度范数始终高于原始输入,这种不平衡可能导致模型更新被增强输入主导。这为梯度冲突提供了直观证据。
关键消融与分析:
- 梯度冲突频率:在未使用PCGrad的DPDA训练中,约25%的迭代存在梯度冲突;使用PCGrad后,冲突频率大幅降低并持续下降(图4a)。
- 收敛速度:使用PCGrad后,模型达到最低验证损失的epoch从第14个提前到第4个,收敛速度提升约43%(图4b),验证了缓解冲突对优化效率的提升。
- 损失曲面可视化(图3):显示原始输入的损失曲面相对平滑,而增强输入的曲面更复杂、有多个尖锐的谷底。两个曲面上对应最小值的方向不一致,直观证明了优化轨迹的冲突。
⚖️ 评分理由
- 学术质量:6.5/7:论文问题定义清晰,实验设计严谨(跨模型、跨增强、多数据集验证),数据分析详实(冲突频率、损失曲面、收敛曲线),技术实现正确。创新点在于问题发现和在新场景的成功应用,而非算法原创。
- 选题价值:2.0/2:直击SDD领域模型泛化的核心难题,提出的训练框架实用、有效、易集成,对提升语音安全系统鲁棒性有直接价值。
- 开源与复现加成:-0.5/1:提供了代码仓库链接,是重大加分项。但未公开预训练模型、完整的超参数配置(如学习率)和训练脚本细节,可能影响部分复现体验。