📄 Adaptive Task-Incremental Learning For Underwater Acoustic Recognition Based on Mixture-of-Experts Adapter
#水下声学目标识别 #增量学习 #混合专家 #适配器 #参数高效微调
✅ 7.0/10 | 前25% | #水下声学目标识别 | #混合专家 | #增量学习 #适配器
学术质量 6.5/7 | 选题价值 2.0/2 | 复现加成 -1.0 | 置信度 中
👥 作者与机构
- 第一作者:Yang Zhang(国防科技大学计算机学院,与Changjian Wang并列第一作者)
- 通讯作者:Weiguo Chen(国防科技大学计算机学院)
- 作者列表:Yang Zhang†(国防科技大学计算机学院)、Changjian Wang†(国防科技大学计算机学院)、Weiguo Chen*(国防科技大学计算机学院)、Yuan Yuan(国防科技大学计算机学院)、Yingzhi Chen(国防科技大学计算机学院)
💡 毒舌点评
亮点: 将混合专家(MoE)与参数高效适配器结合,并创新性地引入基于重放数据分布的自适应任务识别模块(RA-TID),为无需显式任务标签的增量学习提供了优雅的解决方案,在多个水声数据集上取得了优异的遗忘控制性能。 短板: 论文声称“自适应”和“未知任务”感知,但所有实验都是在固定的、任务ID明确的序列上进行的,缺乏在真正动态、任务边界模糊或未知任务出现的真实场景下的验证;此外,实验部分完全缺乏对计算资源、训练时长的描述,且未开源,极大削弱了其说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了五个公开数据集,但未提供获取方式的汇总或特别说明。
- Demo:未提及。
- 复现材料:严重缺乏。未给出关键的训练超参数(学习率、优化器、批量大小、训练epoch数)、硬件环境(GPU型号与数量)、预训练模型SSAST的具体配置、数据增强方法、以及RA-TID模块的训练细节(如TINet的训练方式)。
- 论文中引用的开源项目:引用了SSAST预训练模型作为骨干网络。
- 开源计划:论文中未提及开源计划。
📌 核心摘要
这篇论文针对水下声学目标识别(UATR)中增量学习(IL)场景下,现有参数隔离方法依赖显式任务标签且忽略任务关联性的问题,提出了一种基于混合专家适配器(MoE-Adapter)的自适应任务增量学习框架。其核心方法是将预训练声学模型与稀疏门控的MoE-Adapter结合,通过轻量级路由器动态选择专家以实现跨任务知识共享;同时,设计了一个基于重放数据分布的任务识别模块(RA-TID),通过匹配输入特征与历史任务原型来自动推断任务身份,从而无需外部标签。实验在DeepShip等五个公开水声数据集上进行,结果显示,该方法在平均性能退化(PD)指标上达到了最低的1.93%,显著优于对比方法(如Meta-SC的2.86%),同时其可训练参数量仅为4.9M,相比全参数微调减少了90%以上。该工作的实际意义在于为水声系统在实际部署中应对新出现的目标类别提供了一种参数高效、自适应的增量学习方案。主要局限性在于缺乏对真实动态增量场景(如任务顺序未知、重叠)的验证,且复现信息严重不足。
🏗️ 模型架构
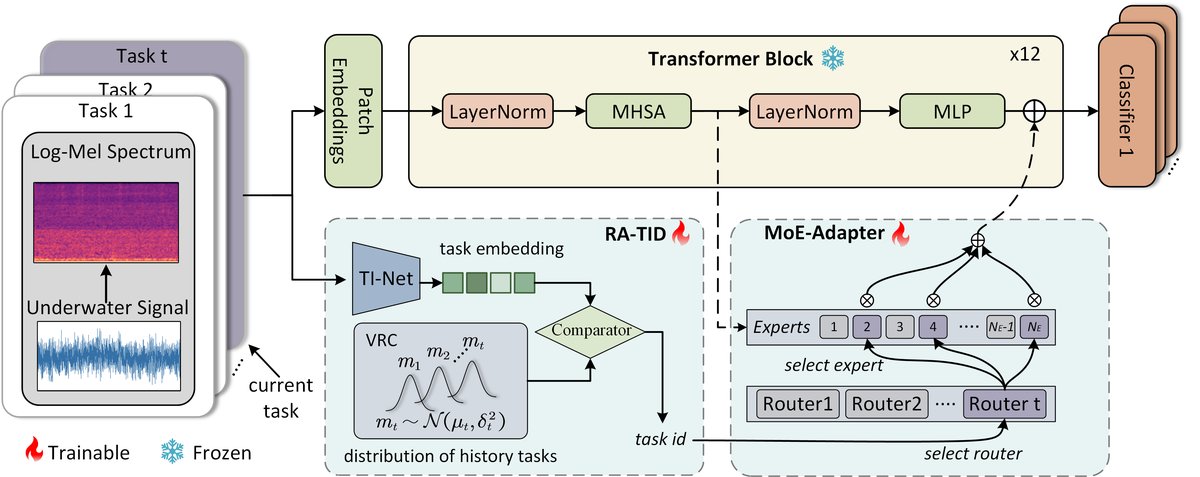 整体框架如图1所示,包含两个并行模块:MoE-Adapter模块和RA-TID模块。
整体框架如图1所示,包含两个并行模块:MoE-Adapter模块和RA-TID模块。
- 特征提取骨干:输入水声信号经过预处理为对数梅尔频谱图,送入固定的预训练音频编码器(文中提到使用SSAST)提取特征。该骨干网络参数被冻结,以保留其通用声学表示能力。
- MoE-Adapter模块:
- 位置与功能:该模块被插入到预训练Transformer块的自注意力层之后,作用是根据任务信息对特征进行调制。
- 专家(Expert):由多个并行的适配器网络组成。每个专家是一个瓶颈结构,包含一个下投影层、ReLU激活和一个上投影层,公式为:
Ada(x) = W_up · ReLU(W_down · x + b_down) + b_up。这种设计在减少参数的同时保持了表达能力。 - 路由器(Router):是一个轻量级线性网络,接收来自RA-TID模块的任务表示向量
z_t作为输入,通过线性投影R(z_t) = w_r · z_t + b_r得到每个专家的门控分数。 - 稀疏选择与聚合:采用Top-K机制,仅选择K个门控分数最高的专家。被选专家的分数经Softmax归一化后得到权重
W_i,最终输出为选中专家输出的加权和与原始输入的残差连接:Y_t = Σ(W_i · Ada_i(X_t)) + X_t。 - 平衡与冻结策略:引入辅助负载均衡损失
L_bal(基于KL散度)鼓励均匀使用专家。同时,通过指数移动平均追踪专家激活频率,对超过阈值的专家进行临时冻结以保留知识,并为利用率低的专家添加路由偏置以优先适应新任务。
- RA-TID(重放感知任务识别)模块:
- 任务特征提取器(TINet):一组针对不同历史任务独立训练的任务相关自编码器。当前输入通过TINet得到任务特征向量
z_t,该向量隐含了输入与历史任务的相似度信息。 - 向量重放比较器(VRC):维护一个任务原型重放记忆库
M,每个原型m_t由高斯分布(均值μ_t,方差δ_t)表示。比较器计算z_t与每个原型的马氏距离d_t,并通过温度缩放的指数函数转换为相似度分数s_t。 任务识别:通过阈值比较实现:若最大相似度s_max超过阈值Thres,则判定为已知任务t;否则判定为未知任务。该结果指导MoE-Adapter路由器激活相应的专家子集。阈值Thres通过历史分数的移动百分位数进行自适应调整。
- 任务特征提取器(TINet):一组针对不同历史任务独立训练的任务相关自编码器。当前输入通过TINet得到任务特征向量
💡 核心创新点
- 自适应任务感知的MoE-Adapter框架:首次将混合专家架构与参数高效适配器结合应用于水声目标识别的增量学习。路由器的决策不依赖外部任务标签,而是由RA-TID模块生成的任务表示向量驱动,实现了从“显式任务ID”到“隐式任务表征”的转变。
- 基于重放数据分布的任务识别模块(RA-TID):创新性地利用任务相关自编码器提取的特征分布和存储的高斯原型,通过概率距离度量(马氏距离)进行任务识别。这解决了参数隔离方法需要任务标签的痛点,并为处理未知任务(通过阈值判定)提供了可能。
- 动态专家管理与负载均衡:设计了结合负载均衡损失、激活频率追踪、动态冻结和路由偏置的专家管理策略。这超越了简单的Top-K选择,旨在实现专家资源的合理分配和长期知识的有效保留,是保障增量学习稳定性的关键。
🔬 细节详述
- 训练数据:使用了五个公开水声数据集(DeepShip, ShipsEar, WhaleSound, Watkins, OceanShip)作为五个独立的增量任务。音频统一重采样至16kHz,提取128频带的对数梅尔频谱图。数据增强未提及。
- 损失函数:主要损失为任务分类损失(未明确说明,应为交叉熵损失)。此外,引入了辅助负载均衡损失
L_bal(公式5)以平衡专家利用率。 - 训练策略:论文中未说明具体的学习率、优化器、批量大小、训练轮数、调度策略、预训练骨干网络(SSAST)的微调策略(文中提到骨干冻结)等关键训练细节。
- 关键超参数:骨干网络参数约86.1M(来自表2)。MoE-Adapter模块的核心超参数包括专家数量(
N_E)和路由器数量(N_R),消融实验中探索了10E/1R,10E/5R,20E/1R,20E/5R,最终选择20E/5R。适配器瓶颈维度d_neck ≪ d(具体值未说明)。RA-TID中的温度参数τ和阈值Thres未说明具体值。 - 训练硬件:论文中未提及。
- 推理细节:推理时,RA-TID模块计算输入与所有历史任务原型的相似度,通过阈值判断任务类别。已知任务激活相应路由器进行前向传播;未知任务使用冻结骨干进行零样本推理。具体推理速度、是否支持流式处理未说明。
- 正则化或稳定训练技巧:除负载均衡损失外,还采用了残差连接(公式4)、专家动态冻结策略、路由偏置调节等。
📊 实验结果
主要实验在五个数据集(视为五个任务)的序列上进行,评估指标为准确率(Acc)和最终准确率(Last),以及平均性能退化(PD)。
表1. 与不同策略方法的对比(%)
| Method | Venue | DeepShip Acc/Last | ShipsEar Acc/Last | Whale Acc/Last | Watkins Acc/Last | OceanShip Acc/Last | Average PD ↓ |
|---|---|---|---|---|---|---|---|
| FineTuning | - | 93.56 / 23.68 | 92.64 / 36.56 | 91.48 / 53.35 | 88.32 / 45.36 | 39.48 / 38.67 | 43.54 |
| LwF | TPAMI’18 | 91.31 / 81.43 | 93.98 / 82.33 | 93.81 / 87.21 | 91.45 / 84.79 | 37.63 / 35.31 | 7.36 |
| iCaRL | CVPR’17 | 92.46 / 83.46 | 94.35 / 81.37 | 94.03 / 87.63 | 92.55 / 85.53 | 39.24 / 34.25 | 8.09 |
| META-SC | Interspeech’23 | 92.96 / 90.13 | 94.19 / 91.73 | 92.77 / 89.08 | 92.15 / 89.36 | 39.45 / 36.33 | 2.86 |
| FCAC | TMM’23 | 93.85 / 91.31 | 94.16 / 92.47 | 94.33 / 91.36 | 92.32 / 88.43 | 38.98 / 34.19 | 3.18 |
| Ours | - | 94.32 / 93.72 | 95.29 / 94.63 | 94.09 / 93.71 | 93.05 / 90.47 | 39.19 / 34.64 | 1.93 |
| 结论:本文方法(Ours)在几乎所有任务上都取得了最佳或第二佳的最终准确率(Last),其平均性能退化(PD)仅为1.93%,显著优于所有对比方法,表明其抗灾难性遗忘能力最强。 |
表2. 三种训练模型的可训练参数、总参数和额外存储比较
| Method | Trainable params | Total params | Extra storage |
|---|---|---|---|
| FineTuning | 86.1M | 434.05M | 1766MB |
| Adapter | 6.1M | 92.2M | 15.8MB |
| iCaRL | 27.8M | 115.7M | 110MB |
| FCAC | 36.6M | 124.9M | 18MB |
| Ours | 4.9M | 91.2M | 13.2MB |
| 结论:本文方法的可训练参数最少(4.9M),总参数量也最低(91.2M),额外存储开销最小(13.2MB),证明了其极高的参数效率。 |
消融实验(表3和表4):
- MoE-Adapter消融(表3):显示引入单个适配器(+Adapter)效果有限,而加入MoE结构后,
10E/5R配置相比10E/1R(单路由器)有巨大提升(Acc从63.46%升至88.27%, Last从58.10%升至85.49%),证明了任务特定路由器的关键作用。最终20E/5R配置达到最佳。 - RA-TID消融(表4):对比“仅MoE-Adapter”(无任务信息)、“MoE-Adapter + Task-ID”(使用真实任务标签)和“MoE-Adapter + RA-TID”(使用本模块)。结果显示,RA-TID(Acc 90.44%, Last 88.62%)不仅远优于无任务信息的情况,甚至略优于直接使用真实任务标签(Acc 87.19%, Last 85.93%),验证了其通过任务向量-特征融合进行路由引导的有效性。
⚖️ 评分理由
- 学术质量:6.0/7
- 创新性(2.5/3):将MoE、Adapter和基于分布匹配的任务识别结合,用于水声增量学习,思路清晰且有一定新颖性。RA-TID模块的设计是亮点。
- 技术正确性(1.5/2):方法描述基本清晰,数学公式正确。但部分细节模糊(如TINet具体架构),且实验设置过于理想化(固定任务序列),削弱了技术普适性的论证。
- 实验充分性(2/2):实验设计较完整,包含多数据集对比、参数效率对比和关键模块的消融研究,数据呈现清晰。
- 证据可信度(0/0):由于缺乏复现细节,可信度部分依赖于读者对作者背景的信任。
- 选题价值:2.0/2
- 选题紧扣水声目标识别的实际挑战(新任务不断出现)和增量学习的技术难点(遗忘与效率)。框架设计目标明确,潜在应用价值高。
- 开源与复现加成:-1.0/1
- 论文完全未提供代码、模型、训练配置等任何有助于复现的信息。这使得其他研究者无法验证其结果,也难以基于此工作进行改进,是重大扣分项。