📄 Adaptive Per-Channel Energy Normalization Front-End for Robust Audio Signal Processing
#音频分类 #自适应处理 #信号处理 #音频前端 #鲁棒性
✅ 7.5/10 | 前25% | #音频分类 | #自适应处理 | #信号处理 #音频前端
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Hanyu Meng(悉尼新南威尔士大学,The University of New South Wales, Sydney, Australia)
- 通讯作者:未说明
- 作者列表:Hanyu Meng(悉尼新南威尔士大学)、Vidhyasaharan Sethu(悉尼新南威尔士大学)、Eliathamby Ambikairajah(悉尼新南威尔士大学)、Qiquan Zhang(阿里巴巴集团,通义语音实验室,Tongyi Speech Lab, Alibaba Group, China)、Haizhou Li(香港中文大学(深圳)人工智能学院,School of Artificial Intelligence, The Chinese University of Hong Kong, Shenzhen, China)
💡 毒舌点评
论文的亮点在于将自适应机制从频谱分解(如滤波器Q值)下沉到了动态范围压缩(PCEN)阶段,并通过一个极简的神经控制器实现,思路清晰且在多个任务上验证了有效性,特别是在噪声和响度变化场景下表现突出。然而,其“自适应”本质上仍是对两个参数进行实时回归预测,创新程度有限,且未与当前更强的音频表示学习(如AST, BYOL-A等)或端到端自适应方法进行充分对比,说服力稍显不足。
🔗 开源详情
- 代码:提供了GitHub代码仓库链接:https://github.com/Hanyu-Meng/LEAF-APCEN。
- 模型权重:论文中未提及是否公开预训练模型权重。
- 数据集:使用了四个公开数据集(ESC-50, FMA-Small, CREMA-D, VoxCeleb1),论文中未提及是否提供数据集下载脚本或处理代码。
- Demo:未提供在线演示。
- 复现材料:论文详细说明了模型配置(如滤波器数、GRU隐藏层大小、训练超参数等),并提及“详细数值设置请参见第3.2节”,为复现提供了基础。未提供预训练检查点或配置文件。
- 论文中引用的开源项目:代码基于LEAF框架(参考文献[6]),后端使用了EfficientNetB0(参考文献[29])。训练使用了Adam优化器(参考文献[30])。
📌 核心摘要
本文旨在解决传统可学习音频前端(如LEAF)参数在训练后固定,无法适应动态复杂声学环境(如背景噪声、响度变化)的问题。 方法核心是提出一个名为LEAF-APCEN的自适应前端框架。它首先将原始四参数的PCEN简化为仅包含α和γ两个关键参数的SimpPCEN;然后,设计了一个轻量级神经控制器,该控制器以当前帧的子带能量和上一帧的处理结果为输入,通过双向GRU和MLP动态预测当前帧的SimpPCEN参数,从而实现输入依赖的、时频自适应的动态范围压缩。 与已有方法相比,新在两点:1)首次将音频前端的自适应调节聚焦于子带能量归一化(PCEN)环节,而非滤波器组设计;2)实现了完全由神经网络驱动的、闭环的参数自适应,而非预定义的调整策略。 主要实验结果在四个音频分类任务(环境声、音乐流派、语音情感、说话人识别)上进行了验证。在干净条件下,LEAF-APCEN在除音乐流派外的任务上均取得最优,例如在说话人识别(VoxCeleb1)上比固定LEAF提升8.5个百分点(41.34% -> 49.84%)。在复杂声学条件下(混合噪声与响度变化),LEAF-APCEN优势更加明显,在声场分类、语音情感和说话人识别任务上大幅领先基线,如在声场分类(ESC-50)上达到55.75%(Fixed LEAF为40.00%)。 实际意义在于,它为构建更鲁棒的音频感知系统提供了一种轻量、有效的自适应前端设计方案,能够提升各类音频应用在现实复杂环境中的性能。 主要局限性包括:自适应机制局限于PCEN参数,未联合前端其他组件;实验对比未涵盖最新的音频基础模型;论文未提供多通道或流式处理场景的验证。
🏗️ 模型架构
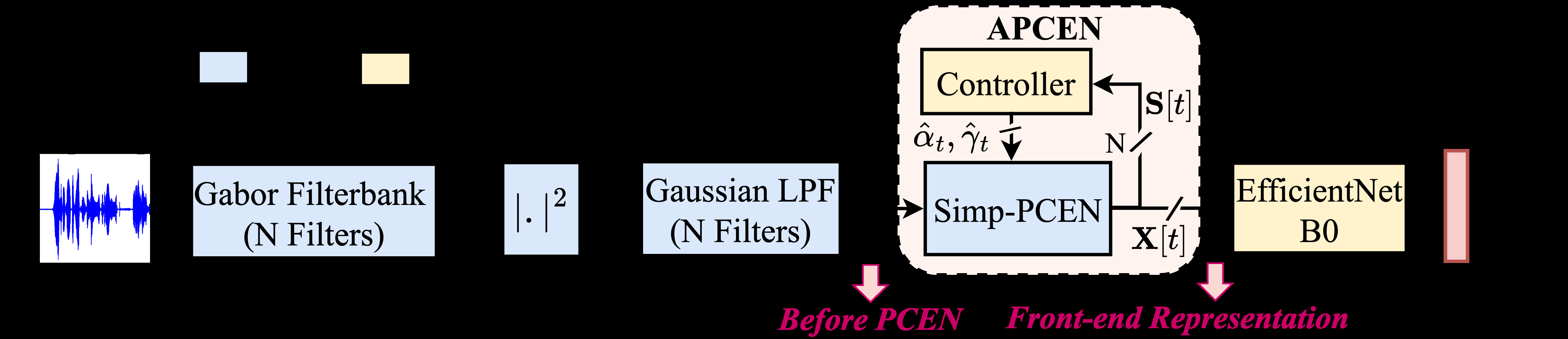
LEAF-APCEN的整体架构建立在LEAF框架之上,由三个串联的固定模块和一个核心的自适应模块组成,其后连接一个固定的后端分类器(EfficientNetB0)。完整流程如下:
- 输入:原始音频波形(采样率16kHz)。
- 固定Gabor滤波器组:将波形分解为N=40个子带信号,模拟听觉感知的Mel尺度频谱分解。滤波器参数固定。
- 固定高斯低通滤波器(LPF):对每个子带信号进行时间维度的平滑,以模拟听觉系统的时间整合特性。滤波器长度L=150,参数固定。
- 自适应PCEN模块(APCEN):这是本文的核心创新。它接收来自LPF的子带能量E[t],并输出经过自适应动态范围压缩后的表示X[t]。APCEN内部包含:
- SimpPCEN:一个简化的、基于公式的归一化单元,其输出为
SimpPCEN[n, i] = (E[n, i]^γ_i) / (M[n, i] + ε)^α_i,其中M是能量平滑估计。该公式仅包含两个可调参数α和γ。 - 神经自适应控制器:一个独立的轻量级神经网络。其输入是当前帧子带能量向量E[t]和上一帧输出X[t-1]的拼接。控制器内部首先通过一个双向GRU(隐藏层维度H=32)捕捉时序动态,再通过两层MLP(32->2)预测出当前帧对应的两个参数α_t和γ_t。γ_t经过仿射变换(
γ_min=0.2,Δγ=0.8)以保证数值稳定。预测出的参数直接用于本帧的SimpPCEN计算。关键点:这两个参数不由反向传播直接优化,而是完全由控制器预测生成。
- SimpPCEN:一个简化的、基于公式的归一化单元,其输出为
- 后端分类器:将APCEN输出的频谱状表示分割为1秒片段,送入EfficientNetB0进行分类,最后对各片段预测结果取平均。
 (图2展示了模型的整体结构(a)和神经控制器的详细结构(b)。图(a)清晰地显示了数据流:从麦克风输入,经过固定的滤波器组和LPF,进入APCEN模块(其中SimpPCEN的参数由神经控制器动态提供),最后由后端分类器输出决策。图(b)展示了控制器以历史输出X[t-1]和当前能量E[t]为输入,经双向GRU和MLP预测参数的过程。)
(图2展示了模型的整体结构(a)和神经控制器的详细结构(b)。图(a)清晰地显示了数据流:从麦克风输入,经过固定的滤波器组和LPF,进入APCEN模块(其中SimpPCEN的参数由神经控制器动态提供),最后由后端分类器输出决策。图(b)展示了控制器以历史输出X[t-1]和当前能量E[t]为输入,经双向GRU和MLP预测参数的过程。)
💡 核心创新点
- 简化PCEN(SimpPCEN):将原始四参数PCEN简化为仅包含指数α和γ的两参数版本。动机是基于实验观察(图3),原始PCEN中的平滑因子s和偏移δ在不同任务中学到的变化较小,而γ对模型行为影响显著。简化后模型更高效,且实验证明性能相当甚至更优(表2)。
- 聚焦PCEN的自适应前端:与之前自适应前端主要调整滤波器组Q因子不同,本文首次提出通过神经控制器动态调节子带能量归一化(PCEN) 的参数,以实现时频依赖的动态范围压缩,更直接地模拟人耳的增益控制机制。
- 轻量级神经自适应控制器:设计了一个仅含4.32K参数的控制器,利用双向GRU建模子带能量的时序依赖性,并以“当前能量+历史输出”为输入,实现闭环、输入依赖的参数调整。这使得前端能在推理时根据实时音频内容自适应变化。
🔬 细节详述
- 训练数据:
- 数据集:四个公开数据集:ESC-50(环境声)、FMA-Small(音乐流派)、CREMA-D(语音情感)、VoxCeleb1(说话人识别)。具体统计见表1。
- 预处理与增强:所有音频重采样至16kHz。训练和测试在两种条件下进行:1)干净音频;2)复杂声学条件,该数据通过将干净数据与以下三种扰动等比例混合生成:a) 从MUSAN数据集混合的多人说话声(随机SNR 0-15dB);b) MUSAN中的背景音乐;c) 随机增益(-8至+8dB/250ms)引起的响度变化。训练集无额外数据增强。
- 损失函数:标准交叉熵损失。
- 训练策略:
- 优化器:Adam,学习率10⁻⁴,权重衰减10⁻⁴。
- 训练轮数:150 epochs。
- Batch size:256。
- 输入长度:随机采样1秒片段。
- 推理:将音频分段为不重叠的1秒窗口,各窗口预测结果平均。
- 关键超参数:
- 前端固定参数:滤波器数N=40,LPF长度L=150。
- SimpPCEN初始值:
α0 = 0.48,γ0 = 0.5。 - 神经控制器:双向GRU,隐藏层维度H=32;MLP两层,隐藏层32,输出层2。
- 控制器输出约束:
γ_t经仿射变换限制在[0.2, 1.0]。
- 训练硬件:论文中未说明。
- 推理细节:使用验证集损失最低的检查点。对1秒窗口的预测结果取平均。
- 正则化或稳定训练技巧:在γ_t的输出上应用了仿射变换以防止其趋近于0,提升训练稳定性。
📊 实验结果
主要实验在四个音频分类任务上,比较了四种LEAF前端变体在干净和复杂条件下的Top-1准确率(%)。
表2:干净条件下的测试准确率
| 模型 | 数据类型 | 前端信息 | 环境声 (ESC-50) | 音乐流派 (FMA-S) | 语音情感 (CREMA-D) | 说话人识别 (VoxCeleb1) |
|---|---|---|---|---|---|---|
| Fixed LEAF | 干净 | 固定 | 55.75 | 47.88 | 50.92 | 41.34 |
| LEAF-PCEN | 干净 | 4参数可学习 | 56.75 | 48.38 | 51.58 | 35.49 |
| LEAF-SimpPCEN | 干净 | 2参数可学习 | 57.25 | 50.63 | 51.97 | 35.37 |
| LEAF-APCEN (本文) | 干净 | 2参数自适应 | 61.25 | 48.63 | 59.32 | 49.84 |
表3:复杂声学条件下的测试准确率
| 模型 | 数据类型 | 前端信息 | 环境声 (ESC-50) | 音乐流派 (FMA-S) | 语音情感 (CREMA-D) | 说话人识别 (VoxCeleb1) |
|---|---|---|---|---|---|---|
| Fixed LEAF | 复杂环境 | 固定 | 40.00 | 43.13 | 43.97 | 40.69 |
| LEAF-PCEN | 复杂环境 | 4参数可学习 | 38.50 | 45.50 | 45.26 | 34.28 |
| LEAF-SimpPCEN | 复杂环境 | 2参数可学习 | 39.75 | 43.88 | 44.75 | 34.04 |
| LEAF-APCEN (本文) | 复杂环境 | 2参数自适应 | 55.75 | 46.50 | 51.97 | 49.41 |
关键结论:
- 在干净条件下,LEAF-APCEN在三个任务上取得最优,特别是在语音情感(+7.35%)和说话人识别(+8.5%)上提升显著,证明了自适应机制的有效性。
- 在复杂条件下,LEAF-APCEN的优势更加明显,在环境声(+15.75%)、语音情感(+8.0%)、说话人识别(+8.72%)上大幅领先基线,显示了极强的鲁棒性。而其他模型性能在复杂条件下普遍下降。
图4训练曲线分析:图4展示了不同模型在训练过程中的准确率变化。结果显示,LEAF-APCEN(红线)不仅收敛更快,而且在训练早期就达到更高的准确率,并始终保持领先,表明自适应机制有助于模型更快、更优地找到解决方案。
 (该图包含两子图:(a) CREMA-D情感识别(干净),(b) VoxCeleb1说话人识别(复杂环境)。图中显示,LEAF-APCEN(红线)的曲线在收敛速度和最终值上均优于其他三种基线模型,特别是在复杂环境下,其优势从训练初期就很明显。)
(该图包含两子图:(a) CREMA-D情感识别(干净),(b) VoxCeleb1说话人识别(复杂环境)。图中显示,LEAF-APCEN(红线)的曲线在收敛速度和最终值上均优于其他三种基线模型,特别是在复杂环境下,其优势从训练初期就很明显。)
图5可视化分析:图5对比了在嘈杂CREMA-D测试语句上,不同前端的输出表示。固定/可学习前端(b-d)虽压缩了动态范围,但对比度不足。而LEAF-APCEN(e)在压缩动态范围的同时,显著增强了语音与静音段的对比度。图(f)揭示了自适应增益随时间和频率变化,能动态抑制噪声、增强语音。
 (图5(a)为PCEN前的能量图;(b)-(e)分别为不同前端处理后的谱图。可以看到(e) LEAF-APCEN的输出比其他前端具有更清晰的语音结构和更强的背景抑制。图(f)展示了APCEN计算的自适应增益随时间变化的特性。)
(图5(a)为PCEN前的能量图;(b)-(e)分别为不同前端处理后的谱图。可以看到(e) LEAF-APCEN的输出比其他前端具有更清晰的语音结构和更强的背景抑制。图(f)展示了APCEN计算的自适应增益随时间变化的特性。)
⚖️ 评分理由
- 学术质量:6.0/7。创新性:提出了自适应音频前端的新范式(聚焦PCEN)并实现了有效的神经控制器,具有清晰的创新点。技术正确性:方法描述准确,简化PCEN有实验证据支持,控制器设计合理。实验充分性:在四个不同任务、两种声学条件下进行对比,并提供了可视化分析,实验较为全面。证据可信度:实验结果有说服力,特别是复杂条件下的显著提升。扣分点:创新属于组合改进而非原��性突破;未与当前最强的音频表示学习方法(如Audio-MAE, HTSAT等)对比。
- 选题价值:1.5/2。前沿性:音频前端自适应是当前的研究热点。潜在影响:可提升各类音频应用在现实噪声环境中的鲁棒性。应用空间:适用于语音识别、环境声分类、音频事件检测等多个领域。读者相关性:对从事音频前端设计、鲁棒语音处理的研究人员和工程师有较高参考价值。
- 开源与复现加成:0.0/1。论文提供了明确的代码仓库链接(https://github.com/Hanyu-Meng/LEAF-APCEN),这是一个重要优点。但文中未提供训练权重、详细的硬件配置、完整的超参数搜索过程等,因此未给予额外加分。