📄 Adaptive Embedding Fusion with Contrastive Learning for Robust Fully Few-Shot Class-Incremental Audio Classification
#音频分类 #对比学习 #少样本学习 #增量学习 #自适应特征融合
✅ 7.5/10 | 前25% | #音频分类 | #对比学习 | #少样本学习 #增量学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Kai Guo(北京理工大学)
- 通讯作者:Xiang Xie†*(北京理工大学, †北京理工大学珠海校区)
- 作者列表:Kai Guo(北京理工大学), Xiang Xie(北京理工大学, 北京理工大学珠海校区), Shangkai Zhao(北京理工大学)
💡 毒舌点评
该论文精准地“手术”解决了EDE模型膨胀的痛点,并通过引入对比学习“补血”提升性能,实验结果亮眼,工程改进思路清晰。但理论分析稍显薄弱,为何自适应融合后对比学习效果更佳,未给出更深层次的解释;且对比学习的应用较为常规,未探索更前沿的对比策略。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:未提及公开预训练或微调的模型权重。
- 数据集:论文提供了三个数据集(FSC-89, LS-100, NSynth-100)在ModelScope上的链接,表明数据集是可获取的。
- Demo:未提及在线演示。
- 复现材料:论文详细描述了实验设置(骨干模型、超参数、训练轮数、硬件等),提供了足够信息以尝试复现,但未提供完整的代码或训练脚本。
- 论文中引用的开源项目:依赖的核心开源项目是AST(Audio Spectrogram Transformer),论文使用了其在AudioSet上预训练的版本。其他引用的基准方法(如iCaRL, FACT, PAN)来自先前工作,论文未说明是否使用其官方实现。
📌 核心摘要
- 问题:论文针对“全少样本类增量音频分类”(FFCAC)任务,即每个新类音频样本极少且需持续学习新类别的场景。现有基线方法EDE通过拼接多个特征提取器的输出来保留旧知识,但导致模型输入维度随学习进程无限膨胀,影响效率与性能。
- 方法核心:提出“自适应嵌入融合EDE(AEF-EDE)”。核心是引入一个可学习的加权融合模块,将不同时期(会话)的特征提取器输出进行加权求和,而非简单拼接,从而固定模型输入维度。同时,在增量学习阶段引入监督对比学习损失(LCL),以增强特征的判别性。
- 创新点:(1) 设计AEF模块,通过可学习参数自适应融合多会话嵌入,避免模型膨胀;(2) 将对比学习策略从基类会话(样本少)调整至增量会话(样本相对多),并证明其在AEF结构下能有效提升性能;(3) AEF与对比学习的结合在多个数据集上超越了原始EDE。
- 主要实验结果:在三个数据集上,AEF-EDE的平均准确率(AA)均优于EDE和其他方法。例如,在FSC-89上AA为43.39%(EDE为38.74%),在LS-100上为61.15%(EDE为56.65%),在NSynth-100上为56.44%(EDE为51.19%)。消融实验证实了AEF模块与对比学习损失(LCL)的协同有效性。
- 实际意义:为资源受限的音频持续学习场景(如野外声音监测)提供了一种更高效、可扩展的解决方案。
- 主要局限性:对比学习在基类会话中因样本过少而失效,作者承认这是未来工作方向;论文未讨论AEF模块的计算复杂度与EDE的具体对比;可学习参数θ的初始化和收敛性未深入分析。
🏗️ 模型架构
论文提出的AEF-EDE模型架构是对基线EDE的改进,其整体流程和核心模块如图1、图2所示。
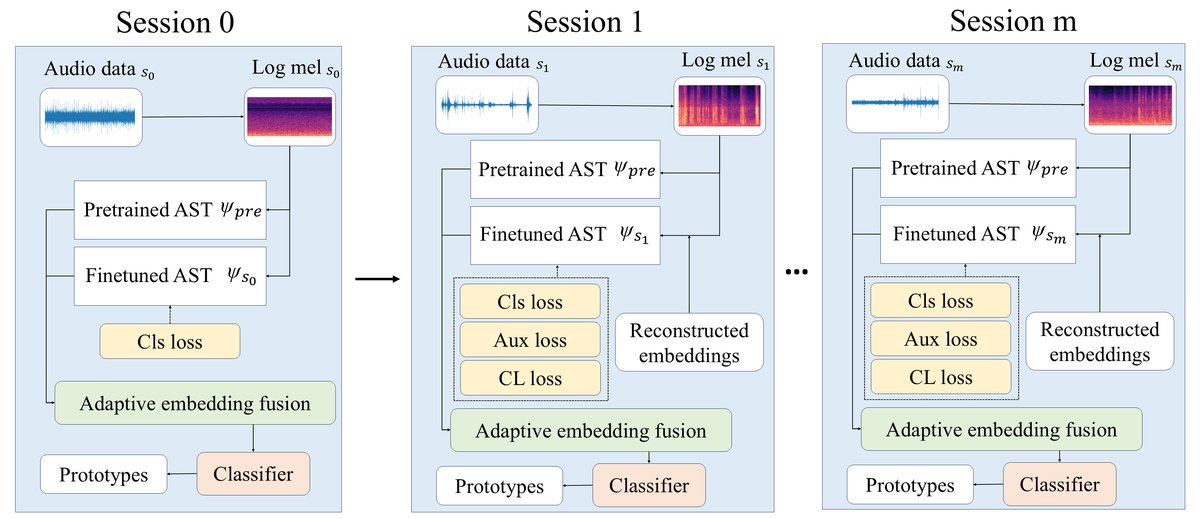 图1:论文整体方法概览。图中展示了模型在多个增量学习会话(Session)中的工作流程。在每个新会话
图1:论文整体方法概览。图中展示了模型在多个增量学习会话(Session)中的工作流程。在每个新会话si中,会引入一个新的特征提取器ψsi(蓝色框)。与原始EDE(左)的直接拼接不同,本方法(右)在拼接预训练特征ψpre(粉色框)后,使用“自适应嵌入融合(AEF)”模块对所有任务特定特征ψsi进行加权融合,输出固定大小的最终特征ψ。同时,在所有增量会话中引入对比学习损失LCL。
完整输入输出流程:
- 输入:原始音频信号。
- 特征提取:使用预训练的AST模型作为
ψpre提取全局特征。对于每个增量学习会话si,会微调一个新的AST模型作为该会话的特征提取器ψsi。 - 自适应嵌入融合:核心改进。模型不会无限拼接新的特征向量。而是将
ψpre的输出,与所有历史及当前会话特征提取器ψs0...ψsM-1的输出,通过一个可学习的加权和进行融合,得到一个固定大小的融合特征向量。这避免了原始EDE中拼接导致的维度增长。 - 分类器:融合后的特征被送入主分类器和辅助分类器,输出类别预测。
主要组件与功能:
- 预训练特征提取器
ψpre:在整个生命周期中冻结,用于提取通用的音频特征,缓解灾难性遗忘。 - 任务特定特征提取器
ψsi:每个新会话引入一个,用于学习该会话新类别的特征。 - 自适应嵌入融合模块(AEF):这是核心创新。它执行的操作是:
ψ_AEF-EDE(x) = concat( ψpre(x), Σ_{i=0}^{M-1} α_i · ψsi(x) )其中,α_i是可学习参数θ_i通过Softmax归一化得到的权重。这个模块将无限增长的特征拼接,转化为一个固定维度的加权融合,使得模型输入大小稳定在2 × H × W(H×W为单个AST输出特征维度)。 - 分类器:包含主分类器和辅助分类器,均使用交叉熵损失进行训练。
关键设计选择与动机:
- 保留
concat(ψpre(...), ...)结构:保留原始EDE中预训练特征与任务特征并行的核心思想,以平衡通用性与特异性。 - 使用可学习加权和替代拼接:直接动机是解决EDE的嵌入膨胀问题。更深层动机是,不同会话的特征提取器重要性可能不同,可学习的
α_i允许模型自适应地分配权重,理论上能更智能地融合信息。
💡 核心创新点
提出自适应嵌入融合(AEF)模块:
- 局限:原始EDE通过拼接嵌入来保留记忆,导致分类器输入维度随学习会话数线性增长,使模型变得臃肿、低效,且不利于迁移学习。
- 如何起作用:AEF模块引入一组可学习的Softmax权重,对各会话特征提取器的输出进行加权求和,将特征融合为固定维度,彻底避免了嵌入尺寸的扩张。
- 收益:显著提升了模型效率和扩展性,为在更多会话或更多类别上持续学习提供了可能。
将对比学习策略应用于增量会话(非基类会话):
- 局限:先前工作(如参考文献[9])在基类会话就使用对比学习,但FFCAC任务中基类样本同样极少,对比学习难以有效展开。
- 如何起作用:论文发现在增量会话(每个会话有N*K个样本)中引入对比学习损失
LCL,能有效提升特征的判别性,特别是在AEF模块因融合可能损失部分信息的情况下。 - 收益:消融实验表明,
LCL的引入(即使仅在增量会话)为AEF-EDE带来了显著的性能提升(如在FSC-89上AA从37.63%提升至43.39%),并能帮助聚类更紧凑(如t-SNE可视化图3所示)。
AEF模块与对比学习的协同效应:
- 局限:单一的AEF模块可能因信息融合导致性能略低于原始EDE(如消融表所示,EDE+AEF的AA低于原始EDE)。
- 如何起作用:论文提出,原始EDE的性能已接近交叉熵损失下的上限。AEF模块改变了特征空间结构,使得对比学习能够更有效地挖掘特征潜力,二者结合突破了原有性能瓶颈。
- 收益:最终AEF-EDE模型在所有数据集上都超越了原始EDE,验证了这一协同假设。
🔬 细节详述
- 训练数据:
- 数据集:FSC-89(声音事件)、LS-100(说话人识别)、NSynth-100(乐器音符)。均来源于公开数据集(FSD-MIX-CLIPS, Librispeech, NSynth)并调整为FCAC格式。
- 规模:每个数据集的训练/测试类数、每类样本数、总时长详见表1。
- 预处理/增强:论文未说明具体预处理步骤。实验设置中提到使用AudioSet预训练的AST作为骨干。
- 损失函数:
LInc = LBase + λ1 · LAux + λ2 · LCL(式5)LBase:主分类器的交叉熵损失。LAux:辅助分类器的交叉熵损失,权重λ1=1。LCL:监督对比学习损失(式4),用于拉近同类样本、推远异类样本的嵌入。温度参数τ=0.07。关键区别:仅在增量会话中使用。λ2:对比学习损失的权重。在FSC-89上设为40,在LS-100和NSynth-100上设为20。
- 训练策略:
- 会话设置:每个实验包含5个会话。基础会话(Session 0)包含5类,后续每个增量会话(Session 1-4)引入5个新类。共25类。
- 每个会话训练:100个epoch。
- 优化器与学习率:初始学习率0.001,采用余弦退火(cosine annealing)策略进行衰减。
- Batch size:256。
- 重复实验:每个实验设置重复100次,报告平均结果。
- 关键超参数:
- 记忆库:大小为5(总样本),每个类1个样本。
- 特征维度:未具体说明H×W数值,但明确指出融合后特征固定为2倍H×W。
- 温度参数τ:0.07。
- 训练硬件:单块NVIDIA RTX 3090 GPU。
- 推理细节:论文未提及特殊推理策略,应为标准的前向传播分类。
- 正则化:未提及除损失函数外的特定正则化技巧。
📊 实验结果
主要对比实验: 论文在三个数据集上与多种基线方法(Finetune, iCaRL, FACT, PAN)及强基线EDE进行了对比,结果如下表所示。AEF-EDE(Ours)在所有三个数据集的平均准确率(AA)指标上均达到最优。
表2:FSC-89数据集性能对比
| 方法 | Session 0 | Session 1 | Session 2 | Session 3 | Session 4 | AA |
|---|---|---|---|---|---|---|
| Finetune | 30.66 | 21.56 | 12.55 | 11.45 | 8.49 | 16.94 |
| iCaRL | 31.27 | 20.79 | 16.86 | 15.44 | 12.60 | 19.39 |
| FACT | 46.35 | 26.18 | 22.87 | 20.13 | 16.53 | 26.41 |
| PAN | 41.48 | 23.72 | 18.08 | 15.27 | 12.25 | 22.16 |
| EDE | 59.08±4.47 | 38.93±2.66 | 36.47±2.49 | 31.67±1.46 | 27.56±1.37 | 38.74 |
| Ours | 59.65±3.68 | 46.36±2.99 | 40.09±2.50 | 37.81±2.38 | 33.04±1.72 | 43.39 |
表3:LS-100数据集性能对比
| 方法 | Session 0 | Session 1 | Session 2 | Session 3 | Session 4 | AA |
|---|---|---|---|---|---|---|
| Finetune | 73.56 | 29.71 | 13.82 | 10.49 | 10.07 | 27.53 |
| iCaRL | 73.15 | 34.40 | 21.75 | 18.30 | 17.77 | 33.07 |
| FACT | 88.41 | 55.59 | 41.34 | 33.83 | 29.65 | 49.76 |
| PAN | 85.70 | 52.20 | 39.17 | 32.95 | 29.88 | 47.98 |
| EDE | 92.08±3.72 | 63.37±4.15 | 49.79±2.58 | 39.10±3.00 | 38.92±3.21 | 56.65 |
| Ours | 91.36±3.69 | 68.40±3.07 | 55.39±3.07 | 44.12±3.17 | 46.48±2.72 | 61.15 |
表4:NSynth-100数据集性能对比
| 方法 | Session 0 | Session 1 | Session 2 | Session 3 | Session 4 | AA |
|---|---|---|---|---|---|---|
| Finetune | 71.88 | 52.60 | 34.74 | 27.11 | 24.18 | 42.10 |
| iCaRL | 71.70 | 53.51 | 53.66 | 49.07 | 49.48 | 55.48 |
| FACT | 74.97 | 51.94 | 51.43 | 46.54 | 43.45 | 53.27 |
| PAN | 76.71 | 58.38 | 53.92 | 48.44 | 44.48 | 56.39 |
| EDE | 64.90±7.75 | 54.06±4.63 | 48.89±2.78 | 44.77±2.80 | 43.31±2.05 | 51.19 |
| Ours | 60.91±7.00 | 59.28±5.25 | 57.03±4.32 | 53.82±3.86 | 51.18±3.65 | 56.44 |
与最强基线差距:
- 在FSC-89上,AA领先EDE 4.65个百分点。
- 在LS-100上,AA领先EDE 4.50个百分点。
- 在NSynth-100上,AA领先EDE 5.25个百分点。
消融实验(在FSC-89数据集): 表5的消融实验清晰地展示了各模块的贡献:
- 仅加入AEF(无LCL)性能略低于原始EDE(37.63 vs 38.74),说明简单的融合可能损失信息。
- 仅在原始EDE上加入LCL(无AEF)能小幅提升性能(39.57)。
- AEF与LCL结合后,性能(43.39)显著优于其他所有变体,证明了二者的协同效应。
- 对比实验也表明,可学习的AEF优于固定的等权融合(Embedding Fusion)。
图3:t-SNE可视化分析
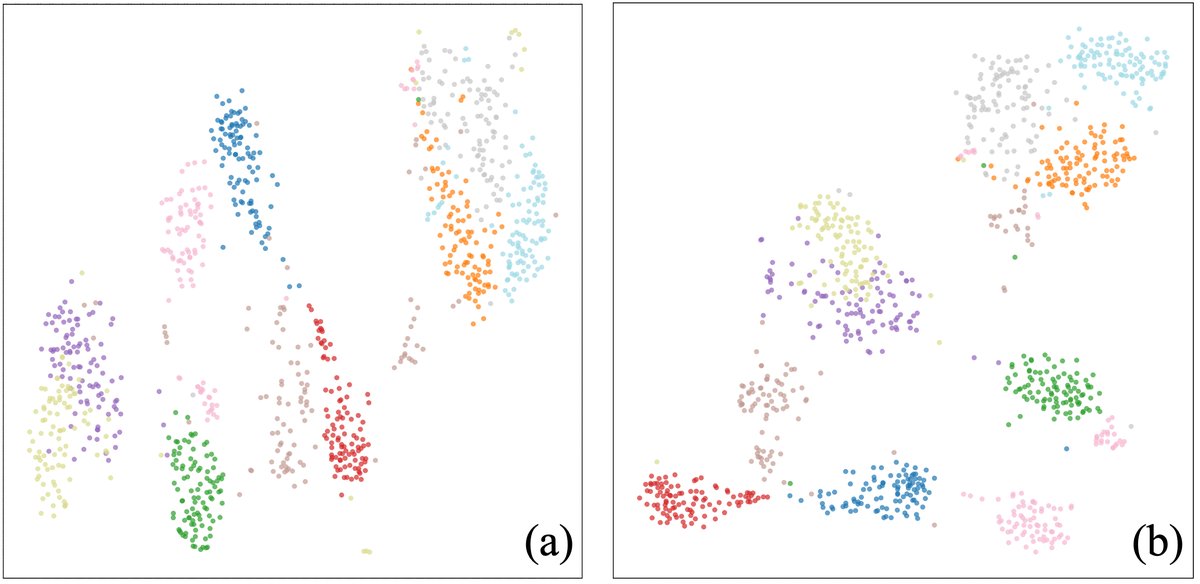 图3:LS-100数据集上的t-SNE可视化。图(a)为不使用对比学习损失的结果,图(b)为使用对比学习损失的结果。对比可见,引入对比学习后,同类别的特征聚类(不同颜色)变得更加紧凑、清晰,类间分离度也更高。这直观地验证了对比学习损失对于提升特征判别性、缓解混淆的有效作用,是性能提升的重要原因。
图3:LS-100数据集上的t-SNE可视化。图(a)为不使用对比学习损失的结果,图(b)为使用对比学习损失的结果。对比可见,引入对比学习后,同类别的特征聚类(不同颜色)变得更加紧凑、清晰,类间分离度也更高。这直观地验证了对比学习损失对于提升特征判别性、缓解混淆的有效作用,是性能提升的重要原因。
其他细分结果: 论文未提供不同会话数、不同样本数(K值)或不同数据增强策略下的细分结果。
⚖️ 评分理由
- 学术质量:6.0/7:创新性(3.5/4):AEF模块设计目标明确,解决实际问题;对比学习的应用时机调整有巧思,且结合AEF产生了1+1>2的效果。技术正确性(1/1.5):方法描述清晰,公式推导正确,实验设置合理,对比公平(复现了EDE基线)。实验充分性(1.5/1.5):在三个不同性质的数据集上验证了方法的有效性,消融实验完整,支持了核心主张。
- 选题价值:1.5/2:前沿性(0.75/1):全少样本类增量学习是当前机器学习领域一个活跃且具有挑战性的前沿方向,在音频领域具有重要应用价值。潜在影响(0.75/1):该工作为解决实际场景中数据稀缺且类别持续增长的问题提供了新的有效方案,对资源受限的音频监测系统有直接参考价值。
- 开源与复现加成:0.0/1:论文未提供代码、模型权重或详细的复现实验配置文件。数据集链接已给出,但核心模型实现未开源,复现依赖性高。