📄 Acoustic Non-Stationarity Objective Assessment with Hard Label Criteria for Supervised Learning Models
#音频分类 #时频分析 #信号处理 #实时处理 #模型评估
✅ 7.0/10 | 前25% | #音频分类 | #时频分析 | #信号处理 #实时处理
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:未说明(论文作者列表无排序信息)
- 通讯作者:未说明
- 作者列表:Guilherme Zucatelli, Ricardo Barioni, Gabriela Dantas(SiDi - Intelligence & Innovation Center, S˜ao Paulo, Brazil)
💡 毒舌点评
亮点在于巧妙地将复杂、难以实时化的非平稳性统计指标(INS)“蒸馏”成易于学习的二进制标签,并训练出专用轻量模型(NANSA),实现了速度上近4000倍的飞跃。短板则在于,这套方法的“地基”——HLC标签的生成——本身仍然依赖那个被诟病“计算不友好”的原始INS算法,颇有“用更累的方法证明自己可以轻松”的悖论感,且任务场景相对狭窄。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文未提及公开模型权重。
- 数据集:论文使用了公开的AudioSet、DCASE和FSD50K数据集,但未说明其生成标签的具体数据划分或获取方式。
- Demo:未提及在线演示。
- 复现材料:论文给出了一些训练超参数(学习率、优化器、epoch数)和模型结构尺寸,但关于数据预处理、HLC算法具体实现代码、训练脚本等关键复现材料均未提供。
- 论文中引用的开源项目:论文引用了PANNs、AST、PaSST等开源模型作为基线,但未说明是否基于其官方代码进行微调。
📌 核心摘要
- 要解决什么问题? 传统的声学非平稳性客观评估方法(如INS)计算复杂度高,需要生成合成参考信号并进行多尺度频谱比较,难以应用于实时处理或资源受限的设备。
- 方法核心是什么? 提出硬标签准则(HLC)算法。该算法将INS在不同观测尺度下的值划分为几个区域,通过多数投票为整个信号生成一个二值(平稳/非平稳)标签。利用此标签作为监督信号,训练了专用的声学非平稳性评估网络(NANSA及其轻量版NANSALW)。
- 与已有方法相比新在哪里? 首次提出一种客观的、自动化的准则(HLC)将多尺度的INS连续值转化为可用于监督学习的全局标签。基于此,设计了专门针对非平稳性评估的轻量级Transformer模型(NANSA),避免了通用大模型的冗余计算。
- 主要实验结果如何? 在AudioSet、DCASE和FSD50K三个数据集上,NANSA模型的分类准确率最高达到94.25%(比最强基线AST高1.8个百分点),EER(等错误率)最低降至2.68%(比最强基线降低49.1%)。最关键的是,NANSA推理速度比传统INS算法快约466倍,NANSALW快约3957倍。
关键实验数据表格:
模型 参数量 (M) MMACs AudioSet Acc (%) AudioSet EER (%) AudioSet F1 DCASE Acc (%) DCASE EER (%) DCASE F1 FSD50K Acc (%) FSD50K EER (%) FSD50K F1 PANNs 81.04 1736 90.82 9.25 0.925 98.27 6.37 0.578 92.52 7.21 0.931 AST 94.04 16785 92.37 7.92 0.938 98.20 5.48 0.594 93.86 6.26 0.943 PaSST 83.35 15021 92.02 8.24 0.936 98.35 5.26 0.612 94.18 5.80 0.948 NANSA 5.50 585 94.25 5.87 0.954 99.01 2.68 0.801 95.41 4.59 0.958 NANSALW 0.66 88 93.27 6.73 0.946 98.89 2.91 0.780 94.93 4.95 0.955 - 实际意义是什么? 为声学信号非平稳性评估提供了一种高效、可部署的替代方案,使其能够应用于实时语音处理、边缘计算设备等场景,支撑基于非平稳性的下游音频任务。
- 主要局限性是什么? 1) HLC标签生成过程本身仍然依赖计算密集的传统INS方法,只是将计算压力转移到了离线标签生成阶段。2) 方法丢失了INS原本提供的多尺度、连续的平稳性信息,仅输出一个二值标签。3) 论文未提供开源代码或详细复现指南。
🏗️ 模型架构
NANSA模型是一个用于二分类的端到端神经网络,整体架构如图2所示,包含两个核心模块:
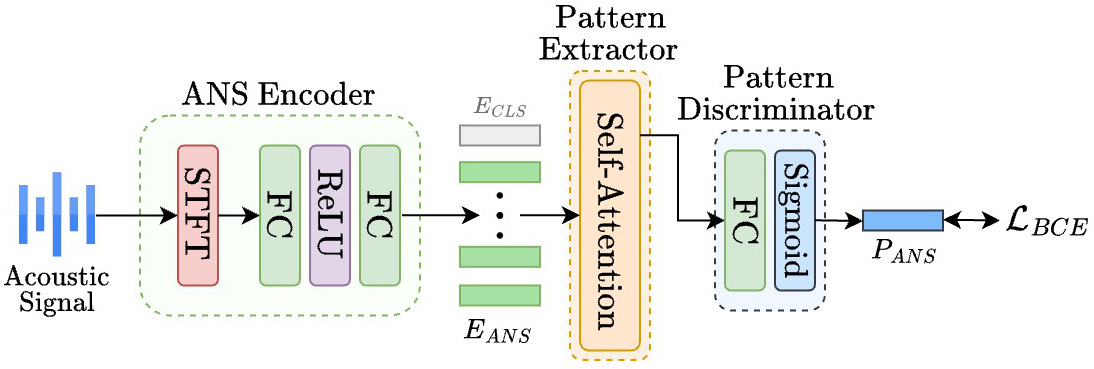
- ANS编码器:负责将原始音频频谱转换为紧凑的嵌入表示。
- 输入:对16kHz采样的音频进行STFT(20ms窗长,50%重叠),得到频谱图 S。
处理:频谱图依次通过两个全连接层(中间有ReLU激活)。第一个全连接层将维度从257扩展到
β_FC 257,第二个再映射回257维,起到缩放变换的作用。 - 输出:产生嵌入向量 E_ANS,并与一个可学习的分类嵌入 E_CLS 拼接,作为后续Transformer的输入。
- 动机:该模块是一个轻量的前馈网络,旨在从原始频谱中快速提取初步的特征表示,其消融实验表明它对最终性能有贡献。
- 输入:对16kHz采样的音频进行STFT(20ms窗长,50%重叠),得到频谱图 S。
处理:频谱图依次通过两个全连接层(中间有ReLU激活)。第一个全连接层将维度从257扩展到
- 基于Transformer的模式提取器:
- 输入:由ANS编码器输出的序列。
- 处理:采用标准Transformer编码器结构,通过多头自注意力机制建模序列中局部和长程的时序依赖关系。为了适配音频分段的特点,使用单位时间 patch 和位置编码。
- 输出:取第一个输出嵌入,通过一个分类头得到概率 P_ANS(属于非平稳的概率)。
- 设计:论文中提供了完整版(11层,3头,192维)和轻量版(4层,3头,64维)两种配置。
💡 核心创新点
- 提出硬标签准则(HLC)算法:
- 是什么:一个将INS的多尺度评估结果聚合为单一二值(平稳/非平稳)标签的自动化算法。
- 之前局限:传统INS方法输出的是一个随观测尺度变化的连续曲线,需要人工解释或设定阈值,无法直接用于监督学习。
- 如何起作用:将观测尺度K个区域,每个区域内采用更严格的自适应阈值γ_HLC判断非平稳性,最后通过区域投票决定全局标签。
- 收益:生成了可用于训练神经网络的大规模、客观的监督标签,将非平稳性评估任务转化为监督分类问题。
- 设计专用非平稳性评估网络(NANSA):
- 是什么:一个轻量级的、基于Transformer的二分类模型,专门用于基于HLC标签的非平稳性评估。
- 之前局限:通用大模型(如PANNs, AST, PaSST)虽能通过微调完成此任务,但模型庞大、计算冗余。
- 如何起作用:采用精简的编码器-Transformer结构,针对短时(1.5秒)音频片段进行优化设计。
- 收益:在保持高准确率的同时,极大减少了参数量和计算量(MMACs),实现毫秒级推理速度,适合实时和边缘部署。
- 验证通用音频模型的非平稳性感知能力:
- 是什么:证明了在AudioSet上预训练的通用音频模型(PANNs, AST, PaSST)能够捕捉到HLC定义的非平稳性信息。
- 之前局限:未知预训练模型是否隐含了对非平稳性的编码。
- 如何起作用:仅微调这些模型的分类头,在HLC生成的标签上进行训练。
- 收益:为非平稳性评估提供了更多可选模型,并揭示了预训练音频表征的一个有用特性。
🔬 细节详述
- 训练数据:使用HLC算法在AudioSet(未平衡子集)、DCASE和FSD50K数据集上生成二值标签。音频被切分为1.5秒的片段。
- 损失函数:二元交叉熵损失(LBCE)。
- 训练策略:所有模型训练20个epoch,学习率10^{-4},使用Adam优化器。论文未说明学习率调度、warmup、具体batch size和数据增强策略。
- 关键超参数:HLC算法配置:区域数K=3(分别对应短、中、长期动态);α_HLC=10(严格阈值)。NANSA(完整版):11层Transformer,3头,192维隐藏层。NANSALW(轻量版):4层Transformer,3头,64维隐藏层。ANS编码器中β_FC=4。
- 训练硬件:INS标签生成在IARA超级计算机上完成。模型训练在配备NVIDIA V100 GPU的x86 Linux机器上进行。训练时长未说明。
- 推理细节:输入1.5秒音频,输出二值概率。无特殊解码策略。
- 正则化技巧:论文未明确提及。
📊 实验结果
论文在三个主流音频数据集上,将提出的NANSA/NANSALW与三个SOTA通用音频模型(PANNs, AST, PaSST)进行了全面对比,主要指标为准确率、等错误率和F1分数。关键对比数据已总结于上述核心摘要的表格中。
消融实验:移除ANS编码器模块后,NANSA在三个数据集上的平均EER增加了10.5%,NANSALW增加了12.5%,证明该编码器对特征提取有积极作用。
速度对比:这是本文最亮眼的实验结果之一。
- 关键结论:传统INS算法处理一段音频需要约12.6秒。而所有基于HLC训练的模型都将时间缩短至毫秒级。其中,NANSA需要约27.3毫秒(比INS快466倍),轻量级的NANSALW仅需约3.2毫秒(比INS快3957倍)。这直接验证了本文解决“计算不友好”问题的有效性。
ROC曲线与AUC:
- 关键结论:在三个数据集上,NANSA和NANSALW的ROC曲线最靠近左上角,对应的AUC值也最高(在DCASE上达到0.996),表明其分类性能最优。
HLC算法自身验证: 论文使用RSG-10数据库中的五种典型声源验证HLC算法。结果显示,对于被认为平稳的办公室和沃尔沃车内噪音,正确率分别为95%和99%;对于被认为非平稳的嘈杂人声、工厂噪音和机枪声,正确率分别为100%、96%和99%。平均准确率98%,证明HLC标签的可靠性。
⚖️ 评分理由
- 学术质量:5.5/7:论文思路清晰,解决了明确的实际问题(计算效率)。提出了HLC标签算法和NANSA专用模型两个有形贡献。实验设计较为全面,包括了基线对比、消融研究、速度测试和标签验证。创新性属于将统计检验问题转化为学习问题的巧妙应用,技术正确性良好,证据充分。但方法深度上没有颠覆性突破,且对“生成标签依赖复杂计算”这一核心矛盾的解决不够彻底。
- 选题价值:1.5/2:非平稳性评估是音频分析的基础环节,其高效化对实时语音应用(如助听器、语音助手)有明确价值。选题聚焦且务实,对关注音频信号处理和实时系统的读者有较好参考意义。但问题领域相对具体���影响面可能不如通用语音生成或识别模型广泛。
- 开源与复现加成:0/1:论文未提及代码开源、模型权重发布或详细复现配置。训练细节(如数据增强、优化器超参数细节)信息不足,复现难度较高。