📄 Acoustic and Facial Markers of Perceived Conversational Success in Spontaneous Speech
#语音情感识别 #多模态模型 #面部动作单元 #协同说话 #对话系统
✅ 6.0/10 | 前50% | #语音情感识别 | #多模态模型 | #面部动作单元 #协同说话
学术质量 5.0/7 | 选题价值 1.0/2 | 复现加成 0 | 置信度 高
👥 作者与机构
- 第一作者:Thanushi Withanage(美国马里兰大学学院公园分校电气与计算机工程系)
- 通讯作者:Elizabeth Redcay(美国马里兰大学学院公园分校心理学系)
- 作者列表:Thanushi Withanage(美国马里兰大学学院公园分校电气与计算机工程系)、Elizabeth Redcay(美国马里兰大学学院公园分校心理学系)
💡 毒舌点评
亮点:论文的选题非常“接地气”且具有现实意义,专注于分析Zoom这种已成为主流的远程沟通场景中的自然对话,所使用的CANDOR语料规模庞大(1500+对话),使得统计结论具有较强的可信度。短板:研究停留在关联性分析层面,缺乏一个端到端的预测模型或机制性解释,结论显得“是什么”多于“为什么”,且对如何应用这些发现进行“针对性干预”只停留在呼吁层面,缺乏具体方案。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的CANDOR数据集(需申请获取),论文中未提供直接获取链接。
- Demo:未提及。
- 复现材料:未提供训练细节、配置或检查点。论文方法部分描述了分析流程,但缺乏可直接运行的脚本。
- 论文中引用的开源项目:明确提及并使用了OpenFace(用于面部行为分析)和PENN(用于基频估计)。
- 总结:论文中未提及开源计划,仅表明使用了部分开源工具。
📌 核心摘要
本文旨在探究在非任务导向的自发Zoom视频对话中,哪些声学和面部特征能够预测感知的对话成功(PCS)。核心方法是利用CANDOR大规模语料库,提取轮次时长、停顿、音高(F0)、语音强度以及面部动作单元(FAU)等多种特征,并通过因子分析构建PCS分数。与以往多聚焦于任务导向或短对话的研究不同,本文创新性地验证了在长时间的自然虚拟对话中同样存在显著的协同现象(entrainment),并建立了特征与对话质量的关联。主要实验结果包括:高成功对话(HSC)相较于低成功对话(LSC),具有更多的轮次(U=545, z=-5.71, p=1.18e-8)、更长的轮次总时长、更短的停顿、更强的音高和强度邻近性(proximity entrainment),以及更显著的微笑相关FAU(如AU10, AU14)的同步性。研究的实际意义在于为优化远程沟通、设计社交技能训练工具提供了可量化的多模态标志物。主要局限性是研究属于相关性分析,未能验证因果,也未构建一个能够实时预测对话质量的计算模型。
🏗️ 模型架构
本文未提出一个传统意义上的“模型”架构,其核心是一个多模态对话特征分析与关联性研究的框架。数据流与处理流程如下:
- 数据输入与预处理:输入为CANDOR数据集中的双通道Zoom对话音频与视频。音频被下采样至16kHz并转为单声道,视频用于面部表情分析。
- 特征提取:
- 对话动态特征:基于Backbiter转录文本,计算轮次时长(最小、最大、均值、总和)和轮次计数。同时,根据转录时间戳计算轮间停顿(静音>0.6秒)的时长统计。
- 声学特征:使用PENN工具从每个说话人轮次中提取基频(F0),并使用Praat计算语音强度。对F0进行归一化以减少性别差异。
- 面部特征:使用OpenFace工具包处理每个说话人的视频,提取17种面部动作单元(FAU)的强度值。
- 协同特征计算:
- 声学邻近性(Proximity Entrainment):为每个对话计算“相邻轮次距离”(当前轮特征值与对方下一轮特征值的绝对差)和“非相邻轮次距离”(与随机对方轮次的绝对差),通过配对t检验判断相邻距离是否显著更小。
- 面部同步性(Synchrony):在5秒非重叠窗口内,计算同一FAU在两个说话人之间的皮尔逊相关系数,经Fisher Z变换后取对话平均值。
- 感知对话成功(PCS)构建:对21项调查问卷进行主成分分析(PCA),选取PCA1对应的11个积极情感与互动指标,标准化后平均得到PCS分数。根据分布,选取PCS≤0.6(LSC)和≥0.9(HSC)的极端子集进行对比。
- 关联性分析:使用Mann-Whitney U检验(针对非正态数据)或Welch’s t检验,比较LSC和HSC组在各项特征上的差异。
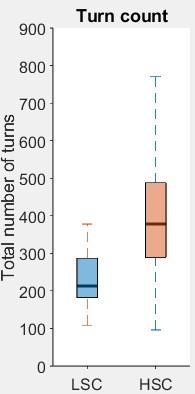 (图1:不同特征与PCS的关联箱线图。展示了在HSC(高成功)和LSC(低成功)对话中,轮次时长(a)、停顿时长(b)以及轮次计数(c)的分布差异。关键结论:HSC对话拥有更多轮次、更长的总轮次时长和更短的停顿。)
(图1:不同特征与PCS的关联箱线图。展示了在HSC(高成功)和LSC(低成功)对话中,轮次时长(a)、停顿时长(b)以及轮次计数(c)的分布差异。关键结论:HSC对话拥有更多轮次、更长的总轮次时长和更短的停顿。)
💡 核心创新点
- 场景的扩展与验证:首次在大规模(>1500)、长时间(30分钟)、非任务导向的成年人Zoom视频对话语料库上,系统验证了声学(音高、强度)和面部(FAU)协同现象的存在及其与对话质量的关联。这填补了以往研究多集中在任务导向或面对面短对话的空白。
- 多模态特征的整合分析:不同于多数仅关注声学特征或仅关注视觉特征的研究,本文将对话轮次/停顿动态、声学特征和面部表情同步性纳入统一的分析框架,全面考察了影响虚拟对话成功的多维度因素。
- 高对比度的标签构建方法:通过PCA从大量问卷指标中提炼出单一的、解释力强的PCS分数,并有意选取分布两端的极端样本(LSC vs. HSC)进行对比分析。这种设计增强了特征区分度,使得统计检验结果更为显著和可靠。
- 对停顿功能的重新审视:实验结果(图1b)显示HSC对话的停顿更短,这与部分先前研究(认为朋友间停顿更长)不同,提示在虚拟远程对话的特定语境下,停顿的意义可能发生变化,过长的停顿可能意味着连接不畅。
- 强调互动的动态过程:通过“邻近性”和“同步性”等指标,研究将焦点从静态特征转移到对话双方在时间上的互动与协调,这更符合对话成功的本质。
🔬 细节详述
- 训练数据:使用CANDOR数据集,包含1500+段由19-66岁成年人通过Zoom进行的30分钟自发视频对话。每段对话后,双方独立完成包含229项问题的问卷。数据预处理包括:选择无背景噪音/打断的会话,音频双声道转单声道并重采样至16kHz。
- 损失函数:未说明(本文为统计分析研究,不涉及模型训练)。
- 训练策略:未说明(无模型训练过程)。
- 关键超参数:未说明(无模型)。分析中使用的参数包括:停顿定义阈值(>0.6秒)、FAU同步性分析窗口(5秒)、Fisher Z变换。
- 训练硬件:未说明。
- 推理细节:未说明(无模型推理)。
- 正则化或稳定训练技巧:未说明。
📊 实验结果
主要对比了LSC(n=35)和HSC(n=91)两组对话在各项特征上的差异。关键结果如下:
表1. 轮次、停顿与声学特征的Mann-Whitney U检验结果
| 特征 (f) | 统计量 (U, z, p, q) | 显著性 (q<0.05?) | 结论 |
|---|---|---|---|
| 轮次总时长 | U=151, z=-5.365, p=8.32e-08, q=3.33e-07 | 是 | HSC显著更长 |
| 轮次计数 | U=545, z=-5.71, p=1.18e-8 | 是 | HSC显著更多 |
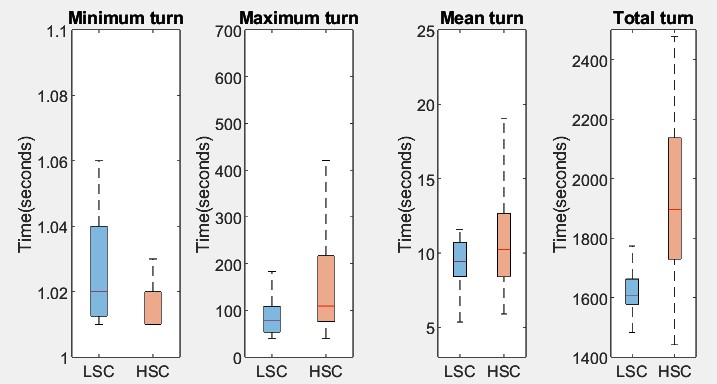
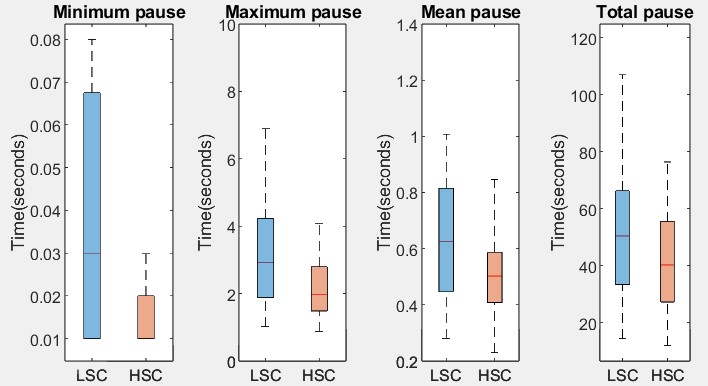
| 停顿最小值 | U=2272.5, z=3.704, p=1.52e-05, q=6.08e-05 | 是 | HSC显著更短 |
| 停顿最大值 | U=1224, z=2.845, p=4.49e-03, q=8.99e-03 | 是 | HSC显著更短 |
| 停顿均值 | U=2080, z=2.655, p=7.98e-03, q=0.0107 | 是 | HSC显著更短 |
| F0最小值 | U=1073, z=-2.826, p=4.70e-03, q=0.0141 | 是 | HSC显著更低(更强邻近性) |
| 强度均值 | U=700, z=-4.152, p=3.30e-05, q=9.89e-05 | 是 | HSC显著更低(更强邻近性) |
表2. 面部动作单元(FAU)同步性的Welch‘s t检验结果(部分)
| FAU ID:描述 | t | p | (µL, σL) | (µH, σH) | 显著性 (p<0.1?) | 结论 |
|---|---|---|---|---|---|---|
| 10: 上唇上提者 | -2.43 | 1.96e-02 | (0.35, 0.17) | (0.42, 0.12) | 是 | HSC同步性更高 |
| 14: 酒窝 | -2.01 | 5.02e-02 | (0.36, 0.14) | (0.41, 0.11) | 是 | HSC同步性更高 |
| 07: 眼睑紧绷者 | -1.74 | 8.80e-02 | (0.28, 0.17) | (0.33, 0.16) | 是 | HSC同步性更高 |
| 12: 唇角上提者 | -1.51 | 1.36e-01 | (0.37, 0.20) | (0.42, 0.20) | 否 | HSC略高 |
| 04: 眉头下压者 | 0.37 | 7.14e-01 | (0.37, 0.16) | (0.34, 0.18) | 否 | LSC略高(负相关FAU) |
注:µL/µH分别为LSC/HSC组的平均Fisher Z相关系数。
 (此图未在论文图片列表中提供,但根据描述,论文中应有类似图1的图表展示声学邻近性结果。)
(此图未在论文图片列表中提供,但根据描述,论文中应有类似图1的图表展示声学邻近性结果。)
 (此图未在论文图片列表中提供,但根据描述,论文中应有展示FAU同步性结果的图表。)
(此图未在论文图片列表中提供,但根据描述,论文中应有展示FAU同步性结果的图表。)
主要结论:高成功对话在行为动态(更多轮次、更长话语、更短停顿)、声学特征(更强的音高和强度协同)以及面部表情(微笑相关动作单元更强的同步性)三个层面均展现出与低成功对话的显著差异。
⚖️ 评分理由
- 学术质量:5.0/7 - 论文研究设计合理,数据可靠,统计方法正确,结论有据。但其核心贡献是验证性的关联分析,而非提出新的理论、算法或模型。研究停留在“发现标志物”层面,对于“这些标志物如何导致成功”或“如何利用它们提升成功”缺乏深入探讨,这在一定程度上限制了其学术深度和影响力。
- 选题价值:1.0/2 - 选题实用,关注远程沟通优化,具有应用潜力。但该方向已属成熟领域,本文未引入颠覆性的新视角或解决一个紧迫的新问题。
- 开源与复现加成:0/1 - 论文使用了公开数据集和开源工具,这为部分复现提供了基础。但未提供任何代码、预处理脚本或详细的分析流程说明,使得他人完全复现其研究结果存在较大困难。