📄 AccLID: Accent-aware Language Identification for Robust Multilingual Speech Recognition
#语音识别 #多任务学习 #领域适应 #多语言 #鲁棒性
✅ 7.0/10 | 前25% | #语音识别 | #多任务学习 | #领域适应 #多语言
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 -1 | 置信度 中
👥 作者与机构
- 第一作者:Rishabh Singh(CERN, Switzerland)
- 通讯作者:未说明
- 作者列表:Rishabh Singh(CERN, Switzerland)
💡 毒舌点评
亮点: 论文提出了一种模块化、模型无关的多模态排序框架,通过整合声学、时间、语言和音素证据显著提升了口音场景下的语言识别鲁棒性,实验设计全面,提供了多维度的量化证据(如口音分级、语言族分析)。 短板: 论文在方法论的深度和新颖性上略显不足,所提框架(假设生成、打分、融合)在思路上并非颠覆性创新;更关键的是,论文完全未提供任何代码、模型或训练细节,极大地限制了其可复现性和实用价值的即时兑现。
🔗 开源详情
- 代码: 论文中未提及任何代码仓库链接。
- 模型权重: 未提及任何公开的模型权重。
- 数据集: 论文使用的评估数据集(FLEURS, ML-SUPERB, LRE17, VoxLingua107)是公开基准,但框架的训练数据未说明。
- Demo: 未提及在线演示。
- 复现材料: 论文未提供训练细节、配置、检查点或附录说明。
- 论文中引用的开源项目: 引用了多个开源模型和工具,如Whisper、MMS、wav2vec 2.0、SpeechBrain、NeMo等作为基线或组件。
- 开源计划: 论文中未提及任何开源计划。
📌 核心摘要
- 解决的问题: 在多语言自动语音识别(ASR)系统中,口音显著降低前端语言识别(LID)的准确性(高达50%),导致识别延迟和转录质量下降。现有LID模型主要依赖声学特征,易受口音引发的语音偏移影响。
- 方法核心: 提出AccLID,一个多模态排序框架。它首先根据基线LID的置信熵自适应生成语言假设;然后,为每个候选语言运行ASR以获取文本转录和时间对齐的音素序列;接着,从中提取声学、语言、时间和音素四类特征;最后,通过十个排序器打分,并利用一个轻量级神经网络根据输入上下文(如置信度熵、口音程度)自适应地学习排序器的权重,进行加权融合得到最终语言预测。
- 与已有方法相比的新颖性: 核心创新在于将一个通用的多模态排序框架集成到任意基线LID系统之上,无需修改底层模型架构。它系统地整合了四种互补的证据源(声学、时间、语言、音素),并通过上下文自适应权重学习动态融合,专门针对口音鲁棒性进行设计。
- 主要实验结果: 在四个基准数据集(FLEURS, ML-SUPERB, LRE17, VoxLingua107)上,AccLID+Whisper的LID准确率(例如在FLEURS上为82.5%)比工业基线(如MMS-1B的66.8%)高出15-27个百分点。在口音鲁棒性分析中,面对强口音语音,AccLID+Whisper的准确率下降幅度(35.9%)远小于Whisper-large(49.5%)。消融实验证明各组件(语言、时间、音素特征,上下文适应)均带来性能提升。
- 实际意义: 该框架可直接集成到现有的ASR流水线中,无需重新训练核心模型,即可显著提升对带口音多语言语音的识别能力,具有即插即用的实用价值。它在准确性和延迟之间取得了新的帕累托最优前沿(82.5%准确率,38ms延迟)。
- 主要局限性: 框架的整体性能最终依赖于所选的基线LID和ASR模型的质量;多语言ASR处理步骤可能引入额外的计算开销,尽管论文声称效率高;论文未公开代码、模型及详细的训练配置,可复现性差。
🏗️ 模型架构
AccLID是一个模块化的后处理框架,而非一个端到端的新模型。其完整流程如下:
- 输入与假设生成: 输入语音
S和基线LID系统L。系统根据基线预测的置信度熵H(c),自适应计算候选语言数量N_adaptive,生成假设集H。 - (可选)领域过滤: 根据先验知识(如会议语言、地理位置)过滤候选集
H_filtered,保留更可能的语言。 - 多语言ASR处理: 对
H_filtered中的每个候选语言l_i,调用ASR系统A并行运行,产出文本转录T_i和时间对齐的音素序列P_i。 - 多模态特征提取: 从ASR输出中,为每个候选语言
l_i提取四类特征:- 声学特征 (
ϕ_a):基于基线LID置信度和声学似然。 - 语言特征 (
ϕ_l):包含ASR置信度、语言模型困惑度(衡量转录的全局语言连贯性)、以及文本LID(WLID)分数。 - 时间特征 (
ϕ_t):建模音素持续时间与语言期望的一致性(Duration Consistency)以及语速(Speaking Rate)。 - 音素特征 (
ϕ_p):评估观测音素序列与候选语言标准音素序列的对齐质量(DTW距离)、口音偏差(KL散度)以及统一的ASR分数(UASR score)。
- 声学特征 (
- 多排序器打分: 十个互补的排序器对每个候选语言的特征进行评分,产生得分向量
S。所有分数进行z-score标准化。 - 上下文自适应权重学习: 从原始置信度分布和排序器分数中提取上下文向量
C(包含熵、方差等),通过一个轻量级全连接神经网络(n_w,结构为5->32->10)预测十个排序器的自适应权重w_j(C)。 - 最终预测: 加权求和所有排序器的标准化分数,得分最高的语言
l*即为最终预测。
关键设计动机: 自适应假设大小平衡了召回率与计算效率;多语言ASR处理提供了丰富的语言、时间和音素证据;上下文自适应权重使得融合策略能根据输入(尤其是口音程度)动态调整,提升鲁棒性。
图片说明: 论文中提供了两张图表(图1和图2),但未提供完整的模型架构图。因此,以下基于论文提供的图表描述相关结论。
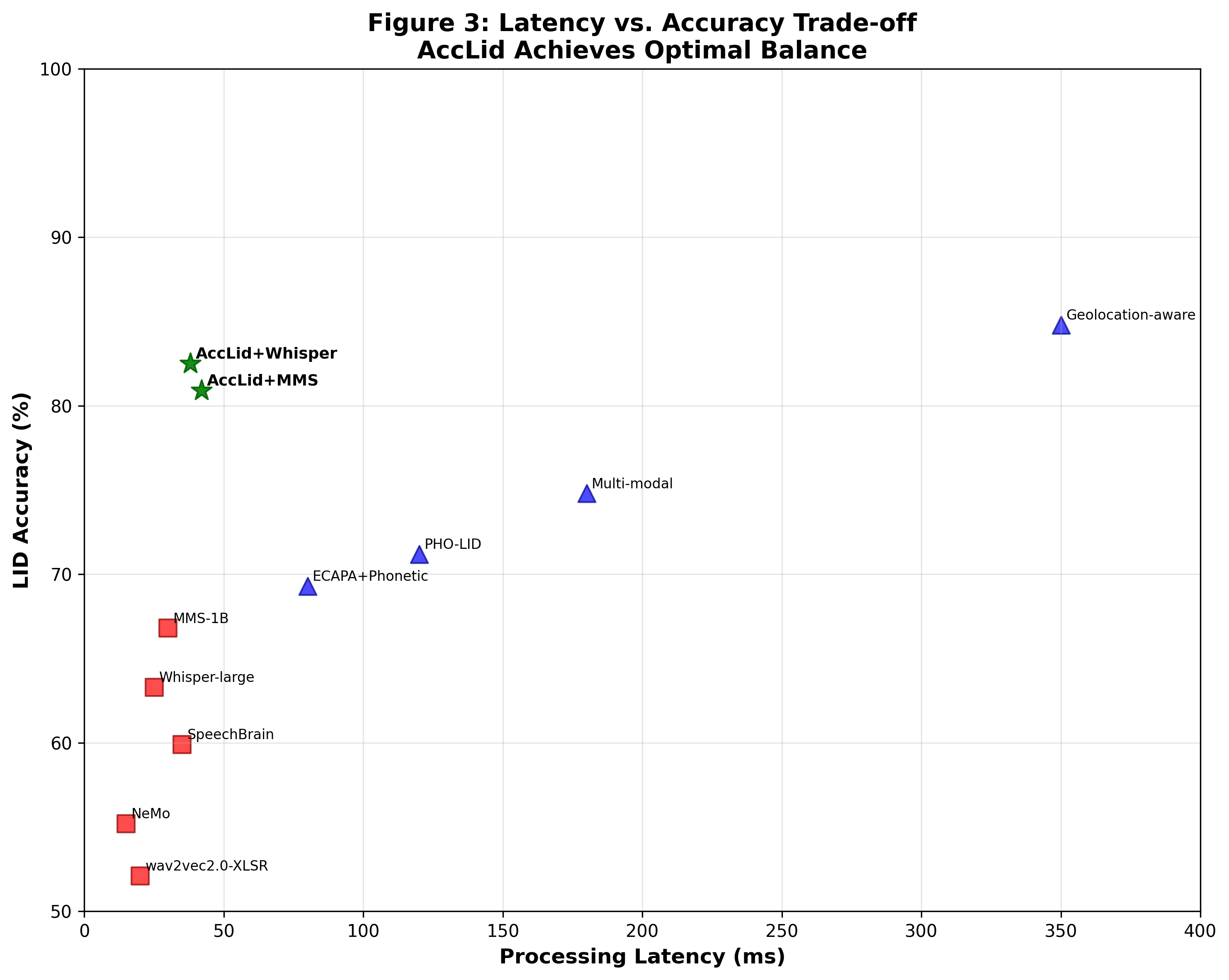 图1显示了不同方法在FLEURS数据集上的LID准确率(y轴)与处理延迟(x轴)的关系。AccLID的三个变体(+Whisper, +MMS, +SpeechBrain)位于图的右上区域,表明它们在保持高准确率的同时,延迟(约38ms)远低于学术方法(如Geolocation-aware LID,延迟在200ms以上),实现了更优的效率-准确率权衡。
图1显示了不同方法在FLEURS数据集上的LID准确率(y轴)与处理延迟(x轴)的关系。AccLID的三个变体(+Whisper, +MMS, +SpeechBrain)位于图的右上区域,表明它们在保持高准确率的同时,延迟(约38ms)远低于学术方法(如Geolocation-aware LID,延迟在200ms以上),实现了更优的效率-准确率权衡。
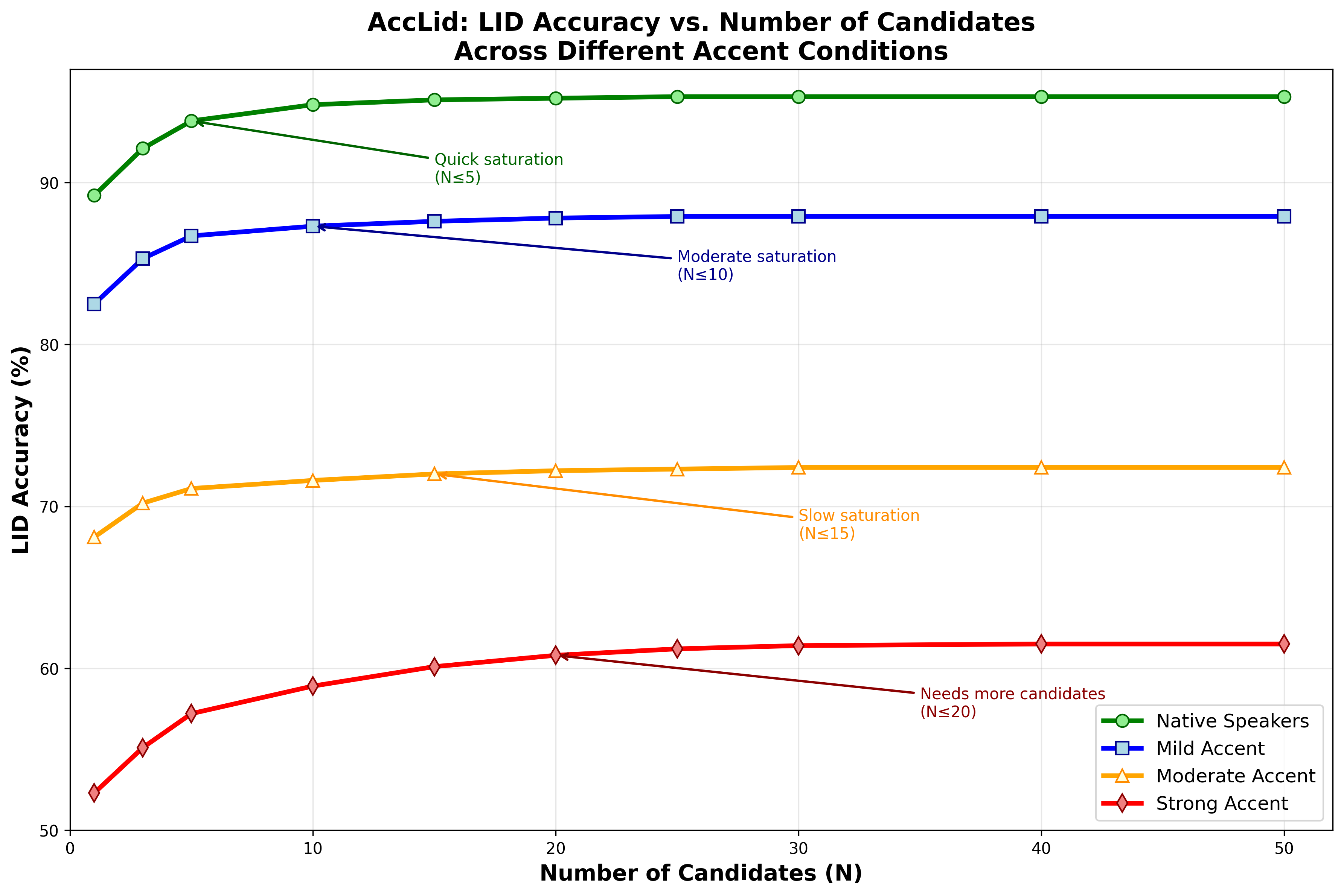 图2展示了AccLID在不同口音条件(Native, Mild, Moderate, Strong)下,LID准确率随候选语言假设大小N变化的趋势。强口音(Strong)条件下,准确率随N增加而显著提升,直到N≈20后趋于饱和;而母语者(Native)在N≈5时即达饱和。这验证了自适应调整N策略的必要性。
图2展示了AccLID在不同口音条件(Native, Mild, Moderate, Strong)下,LID准确率随候选语言假设大小N变化的趋势。强口音(Strong)条件下,准确率随N增加而显著提升,直到N≈20后趋于饱和;而母语者(Native)在N≈5时即达饱和。这验证了自适应调整N策略的必要性。
💡 核心创新点
- 通用多模态排序框架: 提出一个可插拔的框架,能在不修改任何底层模型架构的前提下,增强任何现有LID系统的口音鲁棒性。通过整合声学、语言、时间、音素四种互补证据,弥补了传统单模态(声学)LID在口音场景下的脆弱性。
- 子词级时间建模与跨语言音素分析: 引入了基于音素持续时间和语速的
时间特征,以及基于音素序列对齐和口音偏差的音素特征。这些特征在口音引起语音偏移时,比纯声学特征更稳定,提供了更可靠的判别依据。 - 上下文自适应权重学习: 设计了一个轻量级神经网络,能根据输入语音的具体特征(如置信度不确定性、口音强度)动态计算各排序器的重要性权重。这避免了静态融合的局限性,使框架能自适应地处理不同口音严重程度的输入。
🔬 细节详述
- 训练数据: 未明确说明训练AccLID框架(特别是上下文自适应权重学习网络
n_w)所使用的具体数据集。论文提到的FLEURS等是评估数据集。训练数据的来源、规模、预处理方法均未说明。 损失函数: 用于训练权重网络n_w的损失函数为L = λ1L_LID + λ2L_ASR + λ3L_reg,平衡LID交叉熵损失、ASR词错误率(WER)损失和L2正则化。权重λ1, λ2, λ3的具体值未说明。 - 训练策略: 学习率、优化器、批次大小、训练轮数、调度策略等均未说明。
- 关键超参数: 最小候选数
N_base通常为10,敏感性参数α,持续时间分数中的β,最小过滤数N_min通常为3。权重网络结构为5 -> 32 -> 10。其他排序器的具体设计未说明。 - 训练硬件: 论文未提供任何关于训练所用GPU/TPU型号、数量或时长的信息。
- 推理细节: 假设大小根据置信熵自适应调整。并行调用ASR系统处理候选语言。最终预测为加权求和后的
arg max。具体的ASR解码策略(如beam size)、温度设置等未说明。 - 正则化或稳定训练技巧: 损失函数中包含L2正则化项 (
L_reg)。此外,论文提到“z-score归一化”排序器分数以确保公平组合。
📊 实验结果
表一:标准基准测试LID准确率(%)对比
| 方法 | FLEURS | ML-SUPERB | LRE17 | VoxLingua107 |
|---|---|---|---|---|
| Whisper-large [24] | 63.3 | 58.7 | 67.8 | 71.4 |
| MMS-1B [25] | 66.8 | 61.2 | 69.1 | 74.2 |
| wav2vec2.0-XLSR [7] | 48.1 | 45.4 | 52.3 | 58.9 |
| SpeechBrain ECAPA [26] | 59.9 | 56.8 | 64.7 | 70.1 |
| NeMo TitaNet [27] | 55.2 | 52.1 | 61.4 | 67.3 |
| PHO-LID [4] | 71.2 | 68.4 | 76.8 | 78.1 |
| Geolocation-aware [6] | 79.7 | 72.3 | 71.9 | 79.4 |
| Multi-modal Fusion [1] | 74.8 | 70.1 | 73.6 | 76.9 |
| ECAPA+Phonetic [5] | 69.3 | 75.2 | 72.4 | 77.8 |
| AccLid + Whisper | 82.5 | 79.8 | 85.4 | 86.3 |
| AccLid + MMS | 80.9 | 78.1 | 83.7 | 85.1 |
| AccLid + SpeechBrain | 78.4 | 75.6 | 81.2 | 83.7 |
| AccLID结合不同基线模型后,在所有四个数据集上均取得了最佳性能,显著优于最强的工业基线(MMS-1B)和学术方法。 |
表二:口音鲁棒性分析(% 准确率)
| 方法 | 母语 | 轻度口音 | 中度口音 | 强口音 |
|---|---|---|---|---|
| Whisper-large [24] | 78.2 | 65.4 | 42.1 | 28.7 |
| MMS-1B [25] | 81.4 | 68.9 | 45.3 | 31.2 |
| PHO-LID [4] | 84.1 | 72.6 | 51.8 | 38.4 |
| Geolocation-aware [6] | 89.3 | 76.2 | 58.1 | 42.7 |
| AccLid + Whisper | 94.8 | 87.3 | 71.6 | 58.9 |
| AccLID在强口音条件下优势极为明显。例如,当Whisper-large从母语到强口音准确率下降49.5个百分点时,AccLID+Whisper仅下降35.9个百分点,且绝对准确率(58.9%)远超前者(28.7%)。 |
表三:按语言族的性能分析(% 准确率)
| 语言族 | 语言 | Whisper | MMS | PHO-LID | AccLid |
|---|---|---|---|---|---|
| 日耳曼语族 | 英、德、荷、瑞典 | 64.2 | 67.8 | 72.1 | 84.3 |
| 罗曼语族 | 西、法、意、葡 | 61.8 | 65.4 | 70.6 | 82.7 |
| 汉藏语系 | 中、缅、泰、越 | 58.9 | 62.1 | 68.2 | 80.9 |
| 闪含语系 | 阿、希伯来、阿姆哈拉、豪萨 | 55.3 | 59.7 | 66.8 | 78.4 |
| 尼日尔-刚果语系 | 斯瓦希里、约鲁巴、伊博、祖鲁 | 52.1 | 56.2 | 63.9 | 76.8 |
| 南岛语系 | 印尼、马来、他加禄、斐济 | 49.8 | 53.6 | 61.4 | 75.2 |
| 印度-伊朗语族 | 印地、乌尔都、波斯、孟加拉 | 57.4 | 61.9 | 69.1 | 81.6 |
| 日本语系 | 日语 | 60.3 | 64.7 | 71.2 | 83.1 |
| 平均值 | 57.5 | 61.4 | 67.9 | 80.4 | |
| 标准差 | 4.8 | 4.6 | 3.7 | 3.2 | |
| AccLID在所有语言族中均表现最佳,且标准差最小(3.2%),表明其性能稳定,不因语言族的不同而产生大幅波动。 |
表四:消融研究:排序器贡献分析(% 准确率)
| 配置 | 母语 | 轻度口音 | 强口音 | 总体 |
|---|---|---|---|---|
| 仅基线LID | 94.2 | 78.1 | 28.7 | 63.3 |
| + 语言特征 | 95.1 | 82.4 | 45.6 | 71.8 |
| + 时间特征 | 95.8 | 84.7 | 52.3 | 75.2 |
| + 音素特征 | 96.3 | 87.1 | 59.8 | 78.9 |
| + 上下文适应 | 96.8 | 89.4 | 65.2 | 82.5 |
| 每种特征和上下文适应模块都带来了持续的性能提升,尤其在强口音条件下,完整系统(65.2%)相比基线LID(28.7%)有巨大改善。 |
⚖️ 评分理由
- 学术质量:6.5/7 - 创新性良好,提出了一个清晰的、模块化的多模态融合框架来解决实际问题。技术路径正确,实验非常充分,在多个基准上进行了全面对比,包括口音分级、语言族分析和详细的消融实验,结果可信度高。主要失分点在于,作为一篇方法论文,其核心架构(假设生成、打分、加权融合)的组合并非突破性原创,更多是对现有思路的系统化整合和优化。
- 选题价值:1.5/2 - 口音鲁棒性是多语言语音识别落地中的真实痛点,选题具有很好的实际应用前沿性和影响力。提出的框架可直接集成,对工业界和学术界相关读者都有参考价值。
- 开源与复现加成:-1/1 - 论文完全没有提供代码、模型权重、训练细节或超参数配置。这意味着其他研究者无法复现其结果,极大地削弱了论文的实用价值和长期影响力,这是一个严重缺陷。