📄 A Unsupervised Domain Adaptation Framework For Semi-Supervised Melody Extraction Using Confidence Matrix Replace and Nearest Neighbour Supervision
#音乐信息检索 #领域适应 #对比学习 #半监督学习 #数据增强
🔥 8.0/10 | 前25% | #音乐信息检索 | #领域适应 | #对比学习 #半监督学习
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Shengqi Wang(东华大学计算机科学与技术学院)
- 通讯作者:Shuai Yu(大连理工大学信息与通信工程学院),Wei Li(复旦大学计算机科学与技术学院)
- 作者列表:Shengqi Wang(东华大学计算机科学与技术学院)、Shuai Yu(大连理工大学信息与通信工程学院)、Wei Li(复旦大学计算机科学与技术学院)
💡 毒舌点评
本文将“被动适应”重新定义为“主动修复”并设计了相应的CMR和NNS模块,技术故事讲得通顺且实验验证充分,在跨域旋律提取上取得了稳健提升,是个不错的应用导向型工作。但CMR模块中使用KL散度进行“最兼容”补丁选择的设计动机和计算开销分析稍显薄弱,部分核心机制(如patch-wise操作的具体实现)在文中描述不够细致,图表(图2)的可视化对比冲击力也有提升空间。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:实验使用了MIR-1K、MedleyDB、MIREX05等公开数据集,但论文未提供具体获取方式或处理脚本。
- Demo:未提及。
- 复现材料:给出了部分实现细节(如使用
pysndfx进行增强,Adam优化器,学习率0.0005,λ1=0.1, λ2=0.2, CFP特征参数),但未提供完整的训练配置、代码或附录。 - 论文中引用的开源项目:引用了
pysndfx用于音频增强,mir_eval用于评估指标计算。 - 开源计划:论文中未提及开源计划。
📌 核心摘要
- 问题:旋律提取任务面临标注数据稀缺和跨域偏移(如不同音乐风格)两大挑战。现有半监督域适应方法多采用“被动适应”范式,易受伪标签噪声和域差异限制。
- 方法核心:提出一种“主动修复”范式的无监督域适应框架,包含两个核心模块:置信度矩阵替换(CMR)和最近邻监督(NNS)。CMR通过分析模型预测的置信度,主动用高置信度区域(来自增强版本)替换低置信度区域,生成更强的训练样本。NNS利用最近邻对比学习,在语义特征空间对齐源域和目标域。
- 创新点:首次将“主动修复”思想引入该领域;CMR实现了像素级(patch-wise)的语义修复;NNS实现了样本级的特征空间对齐;两者结合共同提升了模型对无标签目标域数据的利用率。
- 实验结果:在六个跨流行(P)、古典(C)、爵士(J)风格的旋律提取任务上,所提方法(CMR-NNS)在整体准确率(OA)上均优于基线模型(MSNet, FTANet, LcMLP, MCSSME)。关键数据见下表。
表3:与基线方法的总体准确率(OA)对比
| 方法 | P→C | C→P | J→C | C→J | J→P | P→J |
|---|---|---|---|---|---|---|
| MSNet | 42.34 | 62.69 | 35.06 | 61.31 | 58.40 | 44.21 |
| FTANet | 42.78 | 63.84 | 37.37 | 62.81 | 53.63 | 44.64 |
| LcMLP | 40.38 | 63.15 | 32.41 | 62.64 | 47.07 | 44.01 |
| MCSSME | 43.51 | 65.28 | 37.96 | 63.26 | 59.72 | 45.21 |
| Ours | 44.75 | 69.13 | 43.40 | 67.86 | 63.99 | 48.50 |
- 实际意义:为音乐信息检索中跨风格的旋律提取提供了新的有效框架,有助于降低对目标域标注数据的依赖。
- 主要局限性:实验仅在特定三种音乐风格的交叉任务上验证,任务规模相对有限;未讨论计算复杂度;CMR的补丁大小、置信度计算等关键超参数的选择依据未充分阐述。
🏗️ 模型架构
本文提出的CMR-NNS框架是一个面向半监督域适应的端到端深度学习模型,旨在利用带标签的源域数据和无标签的目标域数据训练旋律提取模型。
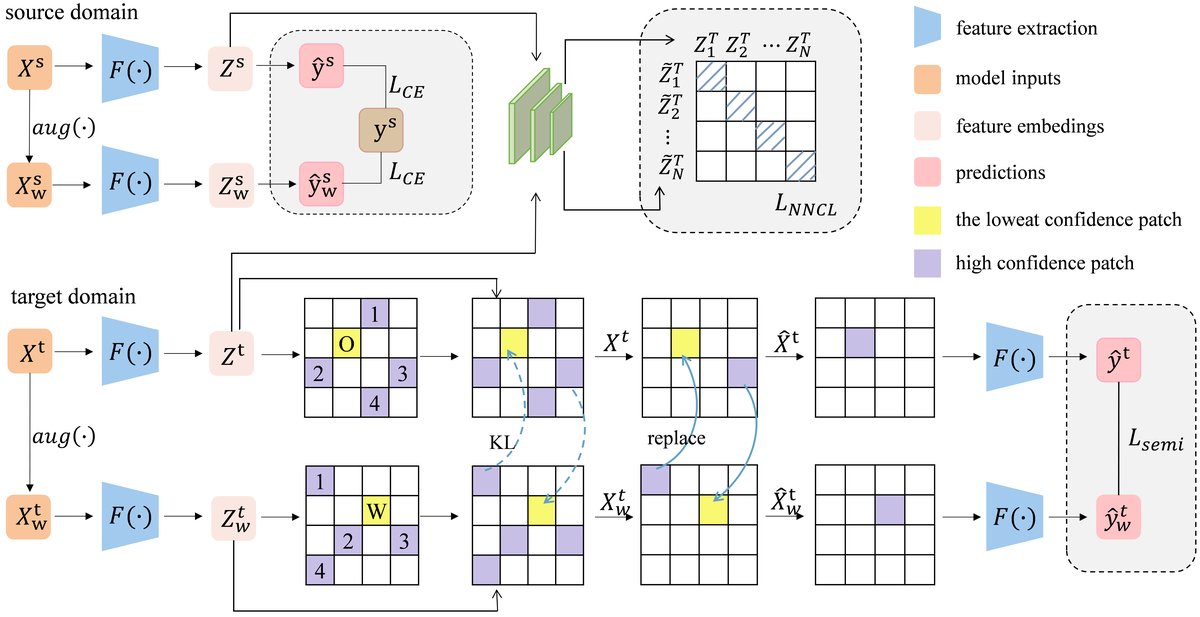 (图1:CMR-NNS框架示意图。左侧展示了NNS模块如何通过最近邻搜索对齐源域和目标域的特征分布。右侧展示了CMR模块如何生成新的增强样本:从两个视图(原始和弱增强)的预测图中提取高置信度和低置信度的patch,并通过特征匹配进行交换,最后强制模型对新样本的预测保持一致。)
(图1:CMR-NNS框架示意图。左侧展示了NNS模块如何通过最近邻搜索对齐源域和目标域的特征分布。右侧展示了CMR模块如何生成新的增强样本:从两个视图(原始和弱增强)的预测图中提取高置信度和低置信度的patch,并通过特征匹配进行交换,最后强制模型对新样本的预测保持一致。)
- 输入与增强:模型输入为源域带标签数据对
{(xi, yi)}和目标域无标签数据{xi}。对所有数据应用增强xi' = A(xi; θ),生成一致性训练所需的多个视图。输入特征采用Combined Frequency and Periodicity (CFP)表示,融合了频谱和周期性信息。 - 骨干网络:采用旋律提取骨干网络(如MSNet、FTANet等)处理输入,输出预测图
Pt ∈ R^{(F+1)×T}和深度特征图Zt ∈ R^{C×F×T}。F是频率bin数,T是时间帧数,C是通道数。 - 最近邻监督(NNS)模块:
- 特征聚合与归一化:对源域和目标域的深度特征图分别进行空间感知池化(全局平均池化与全局最大池化拼接),然后L2归一化,得到
Zs_norm和Zt_norm。 - 最近邻搜索:计算目标域每个样本与所有源域样本的余弦相似度矩阵
S。为目标域每个样本zt_i找到其在源域中的最近邻zs_{n(i)}作为正样本。 - 对比学习损失:计算
L_NNCL损失(公式12),鼓励每个目标域样本的特征靠近其源域最近邻,从而对齐两个域的特征分布。
- 特征聚合与归一化:对源域和目标域的深度特征图分别进行空间感知池化(全局平均池化与全局最大池化拼接),然后L2归一化,得到
- 置信度矩阵替换(CMR)模块:
- 双视图生成:对每个无标签目标域样本,生成原始和弱增强两个视图
Xt和Xw_t,分别输入网络得到预测图Pt、Pw_t和特征图Zt、Zw_t。 - 分块与置信度计算:将预测图在时间-频率平面划分为不重叠的patch。每个patch的置信度
ci定义为patch内所有值的平均值。 - 双向替换:从两个视图中,分别找出置信度最高的top-k个patch集合
H和置信度最低的单个patchpℓ。对于pℓ,从对方视图的H中选择一个patch(通过比较其特征ϕ(p)与pℓ特征的KL散度,选择最小者)进行替换,生成新的增强样本X̃t和X̃w_t。 - 一致性损失:计算
L_semi损失(公式11),强制模型对这对经过“修复”的新样本的预测保持一致(以原始视图的argmax为伪标签,训练增强视图的预测)。
- 双视图生成:对每个无标签目标域样本,生成原始和弱增强两个视图
- 训练损失:总损失
L_total = L_CE + λ1L_semi + λ2L_NNCL。L_CE是源域数据的交叉熵监督损失;L_semi和L_NNCL分别对应上述两个模块的无监督/自监督损失。
💡 核心创新点
- “主动修复”范式的提出:针对现有“被动适应”范式(依赖模型自身去拟合噪声和域差异)的局限,本文首次在旋律提取的域适应问题中明确提出并实现了“主动修复”范式,即主动诊断模型弱点并修复训练样本,这是方法论上的核心转变。
- 置信度矩阵替换(CMR)模块:这是实现“主动修复”的关键技术。与以往依赖全局或简单扰动的伪标签策略不同,CMR在像素(patch)级别操作,通过高置信度区域替换低置信度区域,实现了对训练样本的定向增强和修复,提高了无标签数据的利用质量。
- 最近邻监督(NNS)模块:不同于传统的域对抗或全局分布对齐方法,NNS通过最近邻对比学习,在特征空间建立目标域样本与源域样本之间更细粒度的语义对应关系,实现了更精确的跨域特征对齐。
- CMR与NNS的协同设计:两个模块从不同层面协同工作——CMR在样本/数据层面修复输入,NNS在特征/表示层面对齐分布。这种组合产生了“1+1>2”的效果,在消融实验(表1)和最终对比实验(表3)中均得到验证,尤其在域差异较大的任务(J→C, C→J)上提升显著。
🔬 细节详述
- 训练数据:
- 源域(带标签):MIR-1K数据集中的1000条流行音乐人声音轨。
- 目标域(无标签):MedleyDB数据集中的12首古典音乐和2首爵士音乐。
- 测试集:MIREX05中的9首流行音乐;MedleyDB(与训练集无重叠)中的9首古典音乐和9首爵士音乐。
- 数据增强:对输入应用随机音频增强(使用
pysndfx库),强度由ratio∈[0,1]控制。
- 损失函数:
L_CE:源域标签数据的交叉熵损失(公式10)。L_semi:目标域CMR生成的新样本对之间的一致性损失,采用交叉熵形式(公式11)。L_NNCL:基于InfoNCE的最近邻对比学习损失(公式12),温度参数τ未说明具体值。- 权重:
λ1=0.1,λ2=0.2。
- 训练策略:
- 优化器:Adam。
- 学习率:0.0005。
- 批大小:未说明。
- 训练步数/轮数:未说明。
- Warmup/调度策略:未说明。
- 关键超参数:
- CFP特征参数:每八度60个频率bin,共320个频率单位,频率范围31Hz (B0) 至 1250Hz (D#6)。
- CMR Patch大小
pf × pt:未说明。 - CMR置信度Top-k中的k值:未说明。
- NNS中特征池化方式:全局平均池化+全局最大池化拼接。
- 对比学习温度参数τ:未说明。
- 训练硬件:未说明。
- 推理细节:未说明。
- 正则化技巧:CMR模块本身可视为一种正则化,通过生成更具挑战性的样本来提升泛化能力。NNS的对比学习也有正则化效果。
📊 实验结果
本文在六个跨域旋律提取任务上进行了实验,评估指标为整体准确率(OA)。关键结果汇总如下:
表1:消融实验结果(OA,基于MSNet骨干)
| 方法 | P–C | C–P | J–C | C–J | J–P | P–J |
|---|---|---|---|---|---|---|
| MSNet | 42.34 | 62.69 | 35.06 | 61.31 | 58.40 | 44.21 |
| MS+NNS | 43.39 | 63.58 | 39.95 | 66.97 | 61.51 | 47.82 |
| MS+CMR | 43.51 | 67.52 | 41.48 | 67.12 | 61.83 | 47.05 |
| NNS+CMR | 44.75 | 69.13 | 43.40 | 67.86 | 63.99 | 48.50 |
分析:单独添加NNS或CMR模块均能提升性能。两者结合(CMR-NNS)在所有任务上均取得最优结果,尤其在域偏移大的任务(如C→P提升6.44%,J→C提升8.34%)上优势明显。
表2:NNS模块在不同骨干网络上的泛化性验证
| 方法 | P–C | C–P | J–C | C–J | J–P | P–J |
|---|---|---|---|---|---|---|
| MSNet | 42.34 | 62.69 | 35.06 | 61.31 | 58.40 | 44.21 |
| MS+NNS | 43.39 | 63.58 | 39.95 | 66.97 | 61.51 | 47.82 |
| FTANet | 42.78 | 63.84 | 37.37 | 62.81 | 53.63 | 44.64 |
| FTA+NNS | 45.02 | 68.39 | 39.71 | 68.28 | 64.30 | 46.37 |
| LcMLP | 40.38 | 63.15 | 32.41 | 62.64 | 47.07 | 44.01 |
| LcMLP+NNS | 42.29 | 65.68 | 34.70 | 64.39 | 50.87 | 48.08 |
分析:NNS模块在三个不同的骨干网络(MSNet, FTANet, LcMLP)上均带来了性能提升,证明了其通用性和有效性。
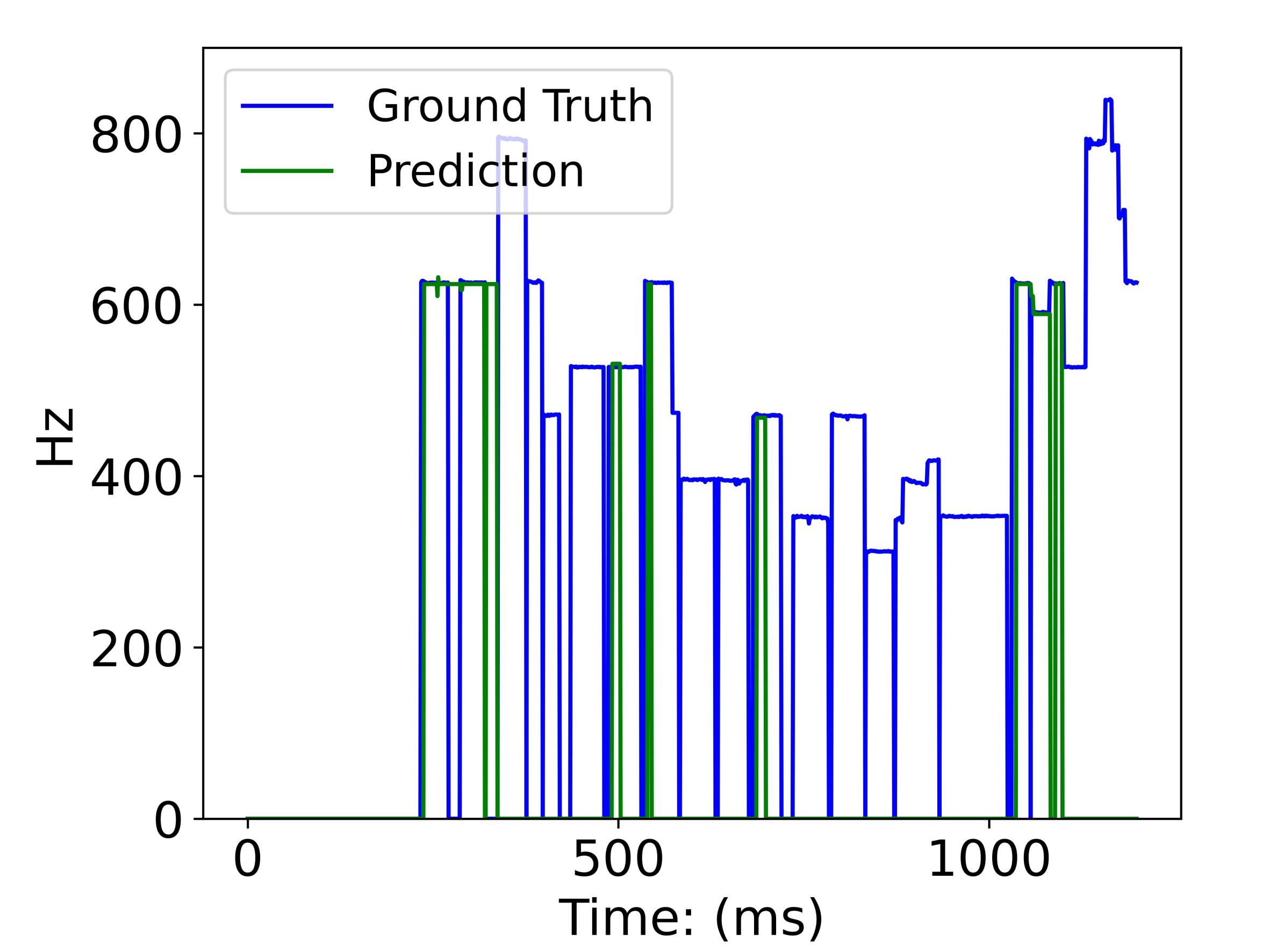
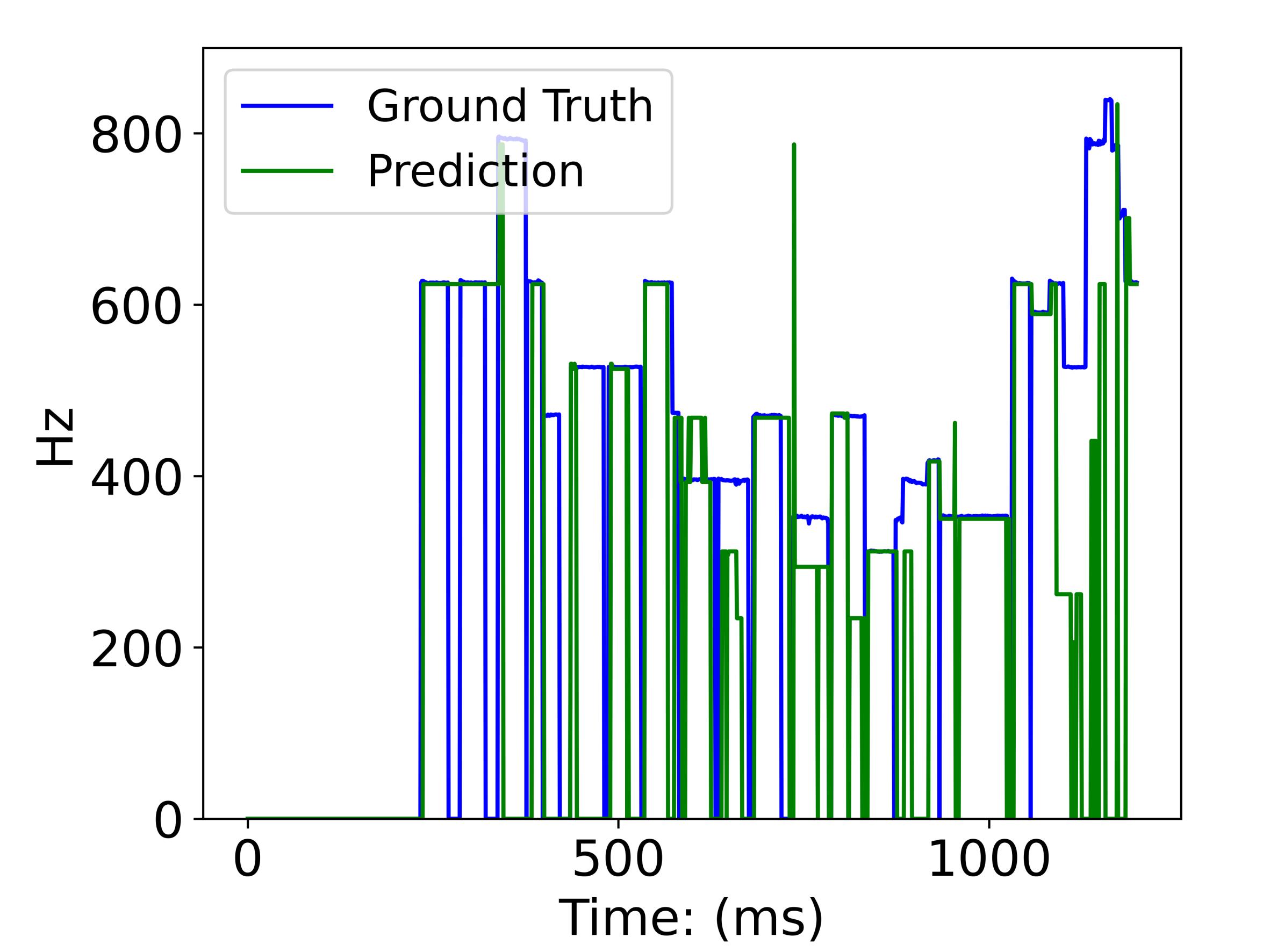 (图2:在J→C任务(爵士到古典)上的旋律提取可视化对比。左图(a)是基线MSNet的结果,显示了严重的片段化问题,许多有效旋律段被错误分类为无声段(值为0)。右图(b)是本文CMR-NNS的结果,生成了连续完整的旋律轨迹,与地面真相(GT)紧密对齐。)
(图2:在J→C任务(爵士到古典)上的旋律提取可视化对比。左图(a)是基线MSNet的结果,显示了严重的片段化问题,许多有效旋律段被错误分类为无声段(值为0)。右图(b)是本文CMR-NNS的结果,生成了连续完整的旋律轨迹,与地面真相(GT)紧密对齐。)
图2分析:该可视化直观地展示了CMR-NNS方法在解决域适应导致的旋律断裂问题上的优势,证明了其在改善发声检测鲁棒性方面的有效性。
⚖️ 评分理由
- 学术质量:6.2/7:论文提出了一个完整且逻辑自洽的框架,创新点明确(CMR, NNS, 主动修复范式),技术细节在框架层面描述清晰。实验设计合理,包含了充分的消融实验和与SOTA方法的对比,并在多个任务上验证了有效性。主要扣分点在于:1)部分关键实现细节(如patch划分、KL散度选择具体标准)描述不够深入;2)实验规模(数据集大小、音乐种类)相对有限;3)未进行更深入的模型分析或可视化(如特征对齐效果的t-SNE图)来进一步支撑论点。
- 选题价值:1.5/2:旋律提取是音乐信息检索的基础任务,跨域适应是其实际应用中的真实痛点。本文工作直接针对此痛点,提出的方法对相关领域的研究者和从��者有参考价值。但该任务本身在AI领域相对垂直,受众和影响力不及语音、图像等主流任务。
- 开源与复现加成:0.0/1:论文未提供代码仓库、预训练模型、数据集下载链接或详细的复现配置文件。虽然给出了部分超参数和实现库名称(如pysndfx),但复现门槛仍然较高,因此无加分。