📄 A State-Dependent Markov Diffusion Process for Generative Speech Enhancement
#语音增强 #扩散模型 #图注意力 #混合损失
✅ 6.5/10 | 前25% | #语音增强 | #扩散模型 | #图注意力 #混合损失
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 中
👥 作者与机构
- 第一作者:Yasir Iqbal(天津大学电气与信息工程学院)
- 通讯作者:Yanzhang Geng(天津大学电气与信息工程学院)
- 作者列表:Yasir Iqbal(天津大学电气与信息工程学院)、Tao Zhang(天津大学电气与信息工程学院)、Anjum Iqbal(大连理工大学软件学院)、Xin Zhao(天津大学电气与信息工程学院)、Yanzhang Geng†(天津大学电气与信息工程学院)
💡 毒舌点评
亮点在于将“状态依赖”的自适应理念引入扩散模型的前向过程,并设计了一套兼顾多目标(时域、频域、感知指标)的混合损失,实验结果在多个指标上确实超越了近期强基线。短板在于,核心创新更像是精巧的“模块拼装”(自适应SDE + GUGA网络 + 混合损失),对于“为何这些组合有效”背后的机理探讨略显不足,且54M参数的模型在实时性上相比轻量模型(如SEMamba)并无优势。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及是否公开。
- 数据集:使用公开的VB-DMD数据集,但论文未说明具体获取方式或预处理脚本。
- Demo:未提及在线演示。
- 复现材料:论文给出了详细的架构描述、损失函数公式、训练超参数(如学习率、优化器、EMA参数、STFT设置)和关键实验设置,具备一定的理论复现基础。但缺少完整的配置文件、环境依赖、检查点等实操信息。
- 论文中引用的开源项目:论文引用了NCSN++[30]作为基线,但未说明是否使用了其开源实现作为代码基础。其他基线(Conv-TasNet, MetricGAN+, SEMamba, SGMSE+等)的引用也未表明代码依赖关系。
📌 核心摘要
这篇论文旨在解决传统扩散模型因使用固定噪声调度而难以适应现实世界动态非平稳噪声的问题。其核心是提出一种状态依赖的马尔可夫扩散过程(SDMDP),该过程的扩散转移率可根据当前含噪状态与目标观测之间的偏差进行动态调整。与之配套的,是名为门控U-Net与图注意力(GUGA)的骨干网络架构,以及结合时域、频域和感知指标(PESQ, STOI)的混合损失函数。实验在VB-DMD数据集上进行,结果显示,采用数据预测范式的“SDMDP (Predict)”方法取得了当前最佳性能,其PESQ、SI-SDR和POLQA分别达到3.84、20.1 dB和4.34,显著优于包括SGMSE+、M8在内的多个竞争基线。该方法的实际意义在于提升了生成式语音增强在复杂噪声下的语音质量和可懂度。其主要局限性在于计算开销较高,论文也承认了加速推理以用于实时应用是未来工作的重点。
🏗️ 模型架构
本文的模型架构由两大部分构成:核心的扩散过程框架(SDMDP)和骨干生成网络(GUGA)。
- 扩散过程框架(SDMDP):
- 整体流程:遵循扩散模型的前向加噪与反向去噪范式。前向过程(公式1)将干净语音$x_0$逐步“加噪”至观测到的含噪语音$y$;反向过程(公式6)则从$y$出发,通过学习到的分数函数$\nabla_{x_t} \log p_t(x_t|y)$逐步恢复出$x_0$。
- 核心创新点:与固定转移率的传统SDE不同,SDMDP的前向SDE中引入了一个状态依赖的转移率$\gamma(x_t, y) = \theta(1 + \alpha \cdot mean(|x_t - y|))$(公式2)。这意味着在扩散的每一步,过程的“前进速度”会根据当前状态$x_t$与目标状态$y$之间的平均绝对偏差自适应调整。偏差越大,转移率越高,从而理论上可以更高效地将状态推向目标分布。
- 概率分布:论文推导了在该自适应SDE下,$x_t$条件于$x_0$和$y$的边际分布为复高斯分布(公式3,4),并给出了训练时的采样公式(公式5)。
- 骨干生成网络(GUGA):
- 功能:作为反向扩散过程中的参数化模型$F_\theta(x_t, y, t)$,负责估计分数、去噪信号或直接预测干净频谱图。最终映射为$F_\theta: (x_t, y, t) \rightarrow \hat{x}_0$。
- 整体结构:一个对称的U-Net编码器-解码器架构。输入是4通道特征图,由含噪状态$x_t$和观测$y$的复数频谱(实部、虚部)堆叠而成:$Input = [Re(x_t), Im(x_t), Re(y), Im(y)]$。
- 核心组件:
- 时间步嵌入:使用多尺度余弦嵌入(公式10)为扩散时间步$t$生成密集表示
temb。 - 门控残差块:网络的核心构建模块。其核心是门控卷积(公式11),通过两个并行卷积分支(一个生成特征,一个生成门控掩码)进行逐元素乘法,能更灵活地控制信息流。结合了GroupNorm和Mish激活。
- 图滤波注意力:在U-Net的不同下采样层级(16x16, 32x32, 64x64分辨率)引入。它使用Network-in-Network(NIN)生成查询(Q)、键(K)、值(V),并计算注意力权重$W$。其关键在于引入了可学习的偏置$b$(公式12),使注意力机制能够进行自适应的图滤波,从而更好地捕捉语音信号中的长程依赖关系。
- 时间步嵌入:使用多尺度余弦嵌入(公式10)为扩散时间步$t$生成密集表示
- 输出:解码器输出为增强的复数频谱图$\hat{x}_0$(2通道:实部、虚部),再通过iSTFT转换为时域波形。
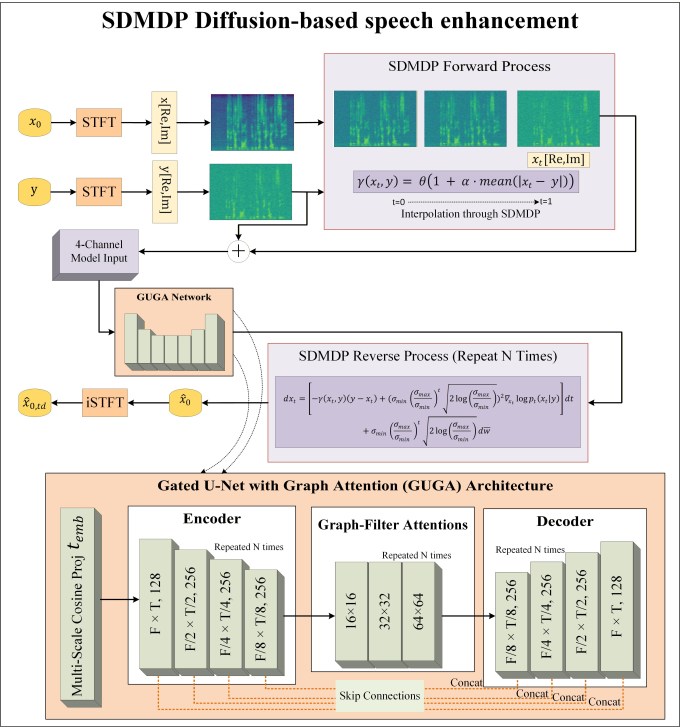 图1展示了SDMDP框架与GUGA架构的整体流程。左侧显示前向过程($x_0 \to x_t \to y$)与反向过程($y \to x_t \to \hat{x}_0$),右侧详细展示了GUGA网络结构,包括输入构造、时间步嵌入、编码器、图注意力模块和解码器。
图1展示了SDMDP框架与GUGA架构的整体流程。左侧显示前向过程($x_0 \to x_t \to y$)与反向过程($y \to x_t \to \hat{x}_0$),右侧详细展示了GUGA网络结构,包括输入构造、时间步嵌入、编码器、图注意力模块和解码器。
💡 核心创新点
状态依赖的马尔可夫扩散过程(SDMDP):
- 是什么:通过设计自适应的转移率函数$\gamma(x_t, y)$,使扩散过程的动力学(即前向加噪的“速度”)实时响应状态$x_t$与目标$y$的偏离程度。
- 先前局限:传统扩散模型使用固定或仅依赖时间$t$的转移率(如OUVE过程),无法根据数据分布的具体情况进行调整,在处理高度非平稳噪声时可能效率低下。
- 如何起作用与收益:公式2使得在状态偏差大的区域(通常对应噪声成分强的区域)扩散过程“加速”,理论上能更快地收敛到目标分布。实验(图2)显示,SDMDP方法在较少的反向步数(N=40-43)下即可达到性能峰值,验证了其效率。
门控U-Net与图注意力(GUGA)架构:
- 是什么:将门控卷积、图滤波注意力与U-Net架构进行深度融合,专为处理复数域语音频谱而设计。
- 先前局限:许多基线模型(如NCSN++)使用标准U-Net或简单的注意力机制,可能对语音的局部结构(门控卷积擅长)和全局谐波/时序结构(图注意力擅长)的建模不够精细。
- 如何起作用与收益:门控卷积增强局部特征筛选能力;图滤波注意力(带可学习偏置)允许网络在不同分辨率下灵活地建模特征图中的全局关系。两者结合旨在以更少的参数(54M vs SGMSE+的65.6M)实现更有效的表示学习,消融实验(表III)也证明了GUGA相对于NCSN++的优越性。
混合感知损失函数:
- 是什么:在数据预测训练范式(公式9)中,联合优化时频域MSE、时域MAE、以及与PESQ和STOI负相关的感知损失项。
- 先前局限:单一的重建损失(如MSE)可能无法直接优化语音的感知质量和可懂度;仅优化感知指标(如PESQetarian)则可能导致其他指标崩溃。
- 如何起作用与收益:多目标联合损失旨在平衡频谱保真度(MSE)、波形精度(MAE)和听感质量(PESQ, STOI)。消融实验(表III)显示,逐步添加这些损失项能持续提升PESQ和ESTOI,最终达到最佳性能,证明了其有效性。
🔬 细节详述
- 训练数据:使用VB-DMD数据集(引用[20]),这是语音增强的常用基准数据集。论文未详细说明其具体规模、说话人数量、噪声类型分布及数据增强策略。
- 损失函数:
- 论文主要展示了数据预测范式下的混合损失(公式9):$\mathcal{L}{data} = \lambda{tf} |\hat{x}0 - x_0|2^2 + \lambda{td} |\hat{x}{0,td} - x_{0,td}|1 - \lambda{pesq} PESQ(\hat{x}{0,td}, x{0,td}) - \lambda_{stoi} STOI(\hat{x}{0,td}, x{0,td})$。
- 权重设置:$\lambda_{td}=0.001$, $\lambda_{pesq}=0.1$, $\lambda_{stoi}=0.1$。$\lambda_{tf}$在文中未明确说明其数值(可能默认为1)。
- 同时也评估了分数匹配损失(公式7)和去噪匹配损失(公式8)。
- 训练策略:
- 优化器:Adam,学习率$10^{-4}$,使用EMA(指数移动平均),衰减率为0.999。
- 扩散步数:N=50。
- 噪声范围:$\sigma \in [0.05, 0.5]$。
- 训练时采样:时间步$t \sim U[0,1]$,生成含噪样本$x_t$(公式5)。
- 关键超参数:
- SDMDP基础参数:$\theta=1.0$, $\alpha=0.1$。
- STFT参数:512点窗,256点帧移,16kHz采样率。
- GUGA网络参数:通道维度[128, 256, 256, 256];图注意力分辨率[16x16, 32x32, 64x64];总参数量54M。
- 训练硬件:论文中未说明。
- 推理细节:
- 采样器:使用自定义的Predictor-Corrector采样器,结合了反向扩散预测器和退火朗之万动力学校正器,区别于标准的DDPM或DDIM。
- 采样步数:图2显示了反向步数N对性能的影响,最佳在40-43步左右。
- 正则化技巧:使用了GroupNorm和EMA(指数移动平均)以稳定训练。
📊 实验结果
实验在VB-DMD数据集上进行,评估指标包括POLQA、PESQ、SI-SDR、ESTOI和DNSMOS。主要对比结果如表II所示。
表II:在VB-DMD数据集上的性能对比(均值±标准差)
| 模型 | 扩散SDE | 损失函数 | POLQA | PESQ | SI-SDR (dB) | ESTOI | DNSMOS |
|---|---|---|---|---|---|---|---|
| 含噪语音 | - | - | 3.11 ± 0.79 | 1.97 ± 0.75 | 8.4 ± 5.6 | 0.79 ± 0.15 | 3.09 ± 0.39 |
| Conv-TasNet+ | - | - | 3.56 ± 0.57 | 2.63 ± 0.60 | 19.1 ± 3.5 | 0.85 ± 0.10 | 3.37 ± 0.32 |
| SEMamba | - | - | 4.33 ± 0.40 | 3.56 ± 0.60 | 19.7 ± 3.2 | 0.89 ± 0.08 | 3.58 ± 0.29 |
| PESQetarian | - | - | 1.46 ± 0.48 | 3.82 ± 0.57 | -19.8 ± 3.3 | 0.84 ± 0.09 | 2.39 ± 0.22 |
| SGMSE+ | OUVE | score | 3.95 ± 0.52 | 2.93 ± 0.62 | 17.3 ± 3.3 | 0.87 ± 0.10 | 3.56 ± 0.28 |
| M2 | OUVE | denoise | 3.96 ± 0.53 | 2.90 ± 0.67 | 18.0 ± 3.3 | 0.86 ± 0.10 | 3.55 ± 0.28 |
| M8 | SB-VE | predict | 4.20 ± 0.51 | 3.44 ± 0.73 | 15.3 ± 2.8 | 0.87 ± 0.09 | 3.58 ± 0.29 |
| GUGA (SDMDP) | SDMDP | score | 4.03 ± 0.52 | 3.15 ± 0.62 | 18.25 ± 3.2 | 0.88 ± 0.10 | 3.41 ± 0.25 |
| GUGA (SDMDP) | SDMDP | denoise | 4.16 ± 0.50 | 3.18 ± 0.63 | 18.73 ± 2.1 | 0.89 ± 0.03 | 3.50 ± 0.28 |
| GUGA (SDMDP) | SDMDP | predict | 4.34 ± 0.53 | 3.84 ± 0.54 | 20.1 ± 3.0 | 0.90 ± 0.11 | 3.61 ± 0.31 |
关键结论:
- 所提出的SDMDP+GUGA组合,特别是在数据预测(predict) 范式下,取得了所有指标的最佳结果。与强生成式基线M8相比,在PESQ(+0.40)、SI-SDR(+4.8 dB)、POLQA(+0.14)和DNSMOS(+0.03)上均有显著提升。
- 数据预测范式(predict)明显优于分数匹配(score)和去噪匹配(denoise)范式。
- 论文还展示了SDMDP方法相比固定速率过程的优越性,如图2所示。
表III:消融实验结果(部分关键行)
| 扩散过程 | 模型 | 损失(L_data) | PESQ | ESTOI |
|---|---|---|---|---|
| 固定速率 | NCSN++ | 仅MSE | 3.30 | 0.84 |
| 固定速率 | GUGA | 仅MSE | 3.45 | 0.86 |
| SDMDP | NCSN++ | 仅MSE | 3.47 | 0.86 |
| SDMDP | GUGA | 仅MSE | 3.50 | 0.87 |
| SDMDP | GUGA | MSE + λ_pesq | 3.71 | 0.90 |
| SDMDP | GUGA | 仅λ_pesq + λ_stoi | 3.80 | 0.90 |
| SDMDP | GUGA | MSE + λ_pesq + λ_stoi | 3.84 | 0.90 |
消融结论:
- SDMDP相比固定速率过程,即使在相同模型(NCSN++或GUGA)和相同损失(仅MSE)下,也能提升性能(例如GUGA从3.45提升至3.50)。
- GUGA架构优于标准NCSN++架构(在固定速率或SDMDP下均如此)。
- 混合损失显著优于单一MSE损失。添加感知损失(PESQ, STOI)能持续提升PESQ和ESTOI,最终达到最佳性能(3.84, 0.90)。
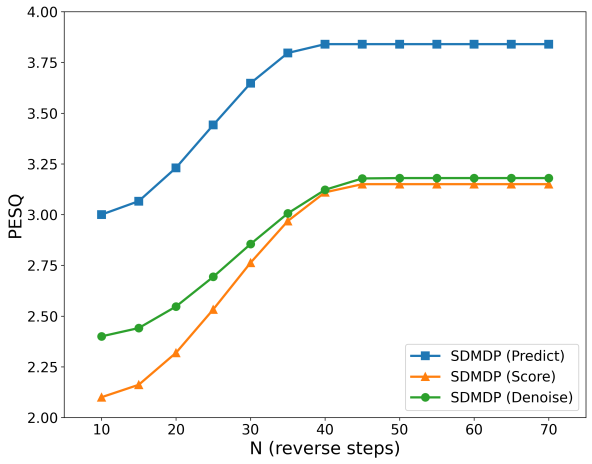 图2展示了不同SDMDP训练范式(Score, Denoise, Predict)在不同反向扩散步数(N)下的PESQ性能。可以清晰看到,SDMDP (Predict) 方法(蓝色线)在N=40步时就达到了最高的3.84分,且整体性能最高,验证了其效率。其他方法在N>60步后性能提升趋于平缓。
图2展示了不同SDMDP训练范式(Score, Denoise, Predict)在不同反向扩散步数(N)下的PESQ性能。可以清晰看到,SDMDP (Predict) 方法(蓝色线)在N=40步时就达到了最高的3.84分,且整体性能最高,验证了其效率。其他方法在N>60步后性能提升趋于平缓。
⚖️ 评分理由
- 学术质量:5.5/7:论文技术路线清晰,将自适应扩散、图注意力网络和混合损失三个创新点有机融合。实验设计规范,对比基线全面(包括判别式、生成式及不同范式),消融研究充分证明了各组件的有效性。主要不足在于核心创新属于现有技术的精巧组合,而非开辟新方向;同时,部分训练细节(如完整超参配置、数据增强)未完全披露,影响了深度的可复现性。
- 选题价值:1.5/2:语音增强是持续的研究热点,对通信、助听、语音识别等领域至关重要。本文针对非平稳噪声这一具体痛点,提出了有效的生成式解决方案,对推动该领域的发展有积极意义。
- 开源与复现加成:-0.5/1:论文对方法描述详尽,但完全没有提供代码、预训练模型、处理脚本或任何复现材料的访问途径。对于这类复杂的生成模型,缺乏开源支持将极大阻碍社区的跟进、验证与应用,因此必须扣分。