📄 A Speech-Driven Paradigm for Physics-Informed Modeling of Coupled Micro-Speakers
#信号处理 #音频生成 #端到端 #声源定位
✅ 7.0/10 | 前50% | #音频生成 | #信号处理 | #端到端 #声源定位
学术质量 5.0/7 | 选题价值 1.5/2 | 复现加成 -0.5 | 置信度 高
👥 作者与机构
- 第一作者:Chen Huang†(重庆邮电大学通信与信息工程学院)
- 通讯作者:Liming Shi†,⋆(重庆邮电大学通信与信息工程学院)
- 作者列表:Chen Huang†(重庆邮电大学通信与信息工程学院)、Chen Gong†(重庆邮电大学通信与信息工程学院)、Lei Zhou†(重庆邮电大学通信与信息工程学院)、Guoliang Wu†(重庆邮电大学通信与信息工程学院)、Hongqing Liu†(重庆邮电大学通信与信息工程学院)、Lu Gan‡(Brunel University College of Engineering, Design and Physical Science)、Liming Shi†(重庆邮电大学通信与信息工程学院)
💡 毒舌点评
论文的亮点在于其“范式转变”的提出——用真实语音而非工程信号进行系统辨识,并为此设计了一个物理启发式的紧凑神经网络(HPNN),在参数量和计算量远小于WaveNet的情况下达到了接近的性能,展现了“小而美”的工程优化价值。然而,短板也显而易见:作为一篇强调“生态效度”和“复现”的工作,论文完全未提供任何代码、模型权重或数据集,其实验结论对于第三方复现而言犹如空中楼阁,大大削弱了其作为“新范式”证明的说服力。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:论文中未提及公开模型权重。
- 数据集:论文中未提及公开数据集。实验数据为自己采集。
- Demo:论文中未提供在线演示。
- 复现材料:论文提供了部分模型配置和训练策略(学习率、优化器、损失函数),但缺少硬件环境、完整超参数搜索过程、数据预处理细节等关键复现信息,不足以独立复现。
- 论文中引用的开源项目:未在提供的论文文本中明确列出依赖的开源工具/模型。
📌 核心摘要
- 问题:智能手机中的共腔多微扬声器系统存在复杂的非线性失真和声学耦合,传统的线性系统辨识方法(如正弦扫频)无法准确建模,影响了声音场控制等下游应用的性能。
- 方法核心:提出一种以真实语音为激励源、基于物理信息的系统辨识新范式。核心是设计了一个“混合多项式神经网络”(HPNN),其架构直接映射自扬声器阵列的物理拓扑:对线性响应的扬声器使用单层卷积,对非线性强的扬声器引入并行多项式卷积与激活,并通过一个全连接混合层联合建模多个扬声器的响应与耦合。
- 与已有方法相比新在哪里:摒弃了传统的扫频激励信号,改用更符合实际使用场景、频谱更丰富的语音信号进行激励和训练,以期更全面地激发系统非线性。模型架构上,HPNN是专为该多扬声器耦合问题定制的“灰盒”模型,兼具可解释性(物理结构指导)和数据拟合能力,在效率和参数规模上显著优于通用黑盒模型(如WaveNet)。
- 主要实验结果:在消声室原型阵列上,HPNN的时间域归一化均方误差(NMSE)达到-11.35 dB,与WaveNet(-11.28 dB)性能相当,但参数量仅为117.62K(WaveNet为1.02M),内存占用和计算量(MACs)也大幅降低。在频率域(200-4000Hz),HPNN在多个频段的表现优于线性FIR模型和Volterra神经网络(VNN),接近WaveNet。具体数据见下表。
| 模型 | LSK1 (dB) | LSK2 (dB) | LSK3 (dB) | LSK4 (dB) | All (dB) |
|---|---|---|---|---|---|
| HPNN | -13.92 | -16.25 | -17.54 | -8.13 | -11.35 |
| WaveNet | -13.91 | -17.03 | -18.25 | -8.15 | -11.28 |
| VNN | -11.39 | -12.25 | -12.40 | -7.32 | -9.37 |
| FIR | -11.45 | -11.47 | -12.51 | -5.83 | -6.27 |
- 实际意义:为复杂非线性音频系统(如多扬声器设备)提供了一种更高效、更贴近实际工况的建模范式与模型设计思路,有望加速移动设备等资源受限环境下的音频系统开发与调试。
- 主要局限性:研究仅在特定原型阵列和消声室环境下验证,其泛化能力未知;未公开代码、数据与模型,可复现性差;作为“新范式”的证明,缺乏与更多传统或先进方法的广泛对比。
🏗️ 模型架构
论文提出的混合多项式神经网络(HPNN)架构如图1所示,其设计紧密贴合所研究的四扬声器(LSK1-LSK4)智能手机物理系统。
- 输入:每个扬声器的驱动信号
x[n]。 - 输出:多个麦克风(MIC 1 至 MIC M)处的声压预测值。
- 主要组件与数据流:
- 线性卷积层1 (Linear Layer 1):处理独立扬声器LSK1。由于LSK1(底部扬声器)膜片大、效率高且通常低幅驱动,其行为近似线性,因此使用一个单输入线性卷积层(FIR滤波器)直接建模其独立响应。公式为
ŷi[n] = Σ h⁽¹⁾[k] · x[n-k],i ∈ {1,4}。 - 并行多项式卷积层 (2nd- pth- Conv Layer):处理非线性强的共腔扬声器LSK2(听筒)和LSK3(顶部)。这些扬声器工作在高驱动电压下,表现出强非线性。模型使用多个并行的卷积层,分别对输入信号进行2阶、3阶……直至P阶的多项式变换(即
xᵖ[n]),每个阶次对应一个独立的FIR核h⁽ᵖ⁾[k]。这相当于用可学习参数替代了传统Volterra级数的核函数,以端到端方式捕获非线性幅频响应。 - 非线性激活 (σ):在每个多项式卷积层之后应用非线性激活函数
σ(·),对中间信号进行整形,增强模型的表达能力。 - 共享线性卷积层:论文提到LSK2、LSK3和LSK4共享腔体,需要联合建模。因此,它们的输入会经过一个三输入线性卷积层,用于直接响应和共享线性耦合部分的建模。
- 混合层 (Mixer Layer):将来自单输入线性层(LSK1)、共享线性层(LSK2-4)以及各阶多项式激活层的所有输出分支进行拼接,然后通过一个全连接的线性混合层,将特征映射(重映射)为最终多个麦克风处的声压预测值
ŷMIC。这一层实现了扬声器响应与耦合效应的全局混合。
- 线性卷积层1 (Linear Layer 1):处理独立扬声器LSK1。由于LSK1(底部扬声器)膜片大、效率高且通常低幅驱动,其行为近似线性,因此使用一个单输入线性卷积层(FIR滤波器)直接建模其独立响应。公式为
- 关键设计选择:
- 物理启发:架构直接反映硬件拓扑(1个独立+3个共腔),体现了灰盒建模思想。
- 混合线性-非线性路径:将线性响应与高阶非线性响应解耦并行处理,再混合,结构清晰且针对性强。
- 端到端多项式卷积:避免了传统Volterra级数需要解析选择核函数阶数和长度的麻烦,通过数据驱动学习各阶非线性核。
💡 核心创新点
- 激励信号范式的转变:摒弃了系统辨识中常用的扫频等工程信号,首次提出并验证使用真实语音信号作为激励源来训练非线性模型。其动机在于语音信号具有宽带、大动态范围和复杂频谱结构,能更充分地激发系统在实际使用中的全部非线性行为(如互调失真),从而获得更具生态效度的模型。
- 面向特定硬件的物理启发式网络设计:提出的HPNN不是通用的黑盒模型,其架构(独立处理vs.联合处理、线性层vs.多项式层)严格遵循所研究的四扬声器共腔阵列的物理布局和操作条件(如驱动电压差异)。这实现了模型效率(参数、计算量)与表达能力的平衡。
- 高效灰盒建模的实证:通过与强大的黑盒基线(WaveNet)和传统的线性/非线性基线(FIR, VNN)进行系统性对比,论文提供了实证证据:一个精心设计的、轻量的灰盒模型(HPNN)可以在大幅降低资源消耗的同时,达到与庞大黑盒模型相媲美的预测精度,为资源受限场景下的复杂系统建模提供了有效路径。
🔬 细节详述
- 训练数据:
- 来源:在消声室中使用四扬声器原型机和麦克风阵列实际采集。
- 规模:超过两小时的录音数据。输入信号包含语音和音乐,经预滤波以匹配各扬声器工作范围。
- 预处理:未详细说明具体预处理步骤(如归一化)。
- 数据增强:论文中未提及使用数据增强技术。
- 损失函数:
- 名称:联合时频域损失。
- 作用:同时优化时域波形和频域频谱的匹配度。
- 公式:
L = α NMSE(y₁, y₂) + (1 - α) NMSE(|Y₁|, |Y₂|),其中y和Y分别表示真实与预测的波形及其频谱幅度。 - 权重:权重因子
α设为 0.3,即更侧重于频域损失。
- 训练策略:
- 优化器:AdamW。
- 学习率:初始为
3e-3,当验证损失停滞20个epoch时减半。 - Batch size:20。
- 权重衰减:
1e-4。 - 训练轮数:未明确说明总epoch数或步数。
- 关键超参数:
- HPNN:线性卷积核长度=2400;并行多项式卷积核长度=512;混合层核长度=1200。参数量:117.62K;内存:59.61 MB;计算量:39.52G MACs。
- WaveNet基线:9个残差块,膨胀率指数增长(1,2,…,256),每个块使用16通道膨胀卷积(核长16)和线性混合器(核长512)。参数量:1.02M;内存:1702.68 MB;计算量:326.96G MACs。
- VNN基线:最高3阶Volterra核,记忆长度:2阶核为16,3阶核为8。参数量:79.72K;内存:312.13 MB;计算量:26.79G MACs。
- FIR基线:2400抽头的FIR滤波器,通过扫频响应反卷积得到。
- 训练硬件:论文中未说明训练所使用的GPU/TPU型号、数量及训练时长。
- 推理细节:论文中未提供推理时的解码策略、温度、beam size等具体信息,因为任务是回归而非生成。
- 正则化或稳定训练技巧:使用了AdamW优化器(自带权重衰减),并采用了基于验证集的退火学习率策略。
📊 实验结果
实验在消声室中的原型四扬声器阵列上进行,评估指标为时域和频域的归一化均方误差(NMSE,单位为dB)。
主要对比实验结果
| 模型 | 参数量 | 内存 (MB) | 计算量 (G MACs) | 时域NMSE (All, dB) |
|---|---|---|---|---|
| HPNN | 117.62K | 59.61 | 39.52 | -11.35 |
| WaveNet | 1.02M | 1702.68 | 326.96 | -11.28 |
| VNN | 79.72K | 312.13 | 26.79 | -9.37 |
| FIR | 未提供 | 未提供 | 未提供 | -6.27 |
表1:各模型在时域建模误差(NMSE)的对比(来自论文Table 1)
论文同时给出了分扬声器和分频段的详细误差数据(Table 2)。关键结论是:HPNN在整体性能(-11.35 dB)上与庞大的WaveNet基线(-11.28 dB)几乎持平,但参数量、内存和计算成本分别只有WaveNet的约1/9、1/35和1/8。而VNN和线性FIR模型性能明显较差。
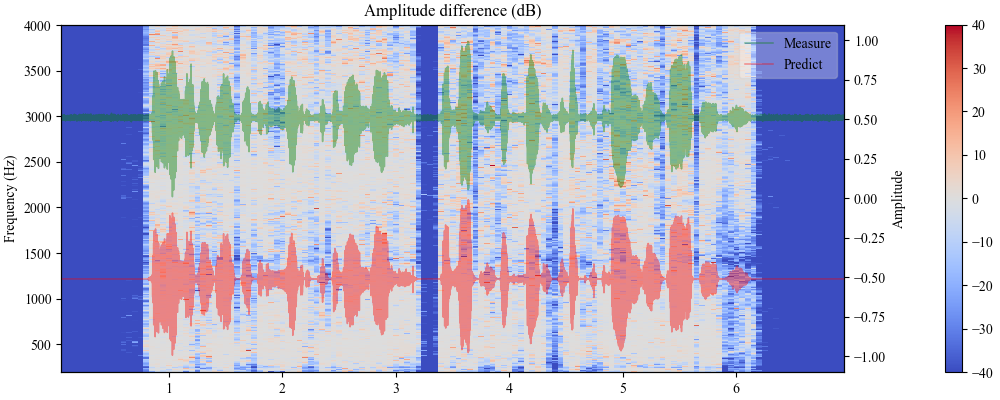
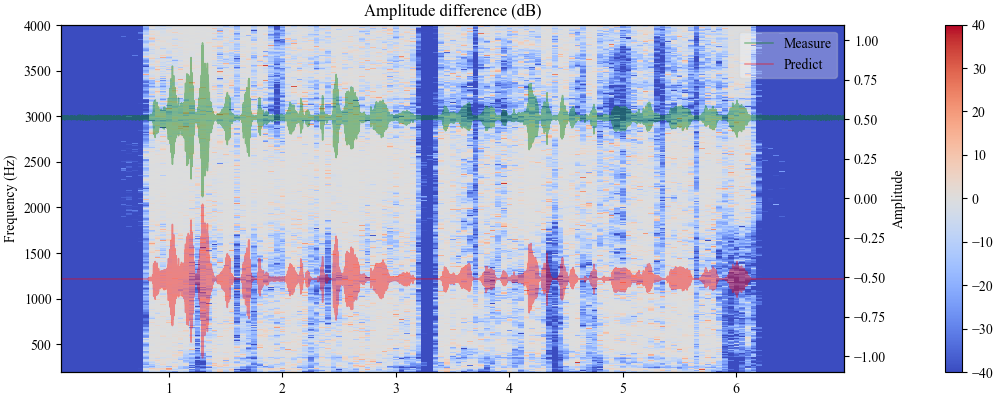 图3展示了LSK1(前两行)和LSK3(后两行)在语音激励下的频率域预测误差。颜色越接近白色表示误差越小。图中可见LSK1在低频区域误差较大,可能与电源噪声有关;而LSK2、LSK3在高频区域的误差被有效抑制,表明多项式层起了作用。
图3展示了LSK1(前两行)和LSK3(后两行)在语音激励下的频率域预测误差。颜色越接近白色表示误差越小。图中可见LSK1在低频区域误差较大,可能与电源噪声有关;而LSK2、LSK3在高频区域的误差被有效抑制,表明多项式层起了作用。
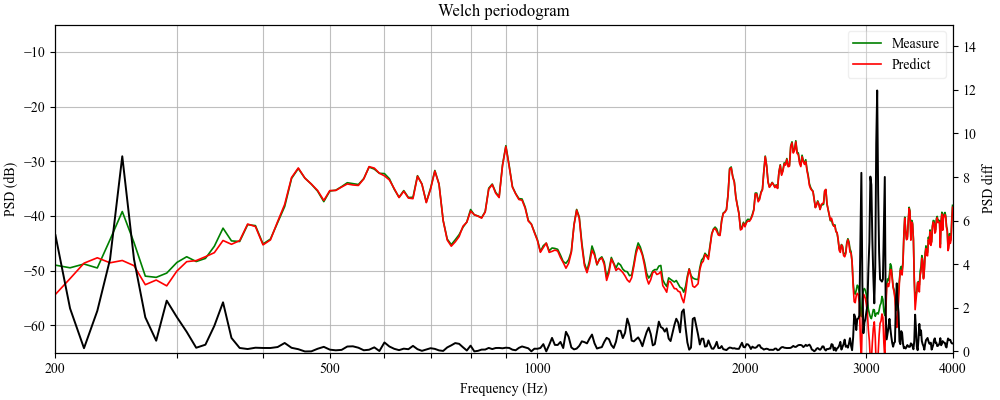 图4显示了在语音活跃期和静默期,不同模型(HPNN, WaveNet, VNN, FIR)对LSK1和LSK3的预测输出波形(红色)与真实波形(蓝色)的对比。它直观地展示了HPNN能紧密跟踪真实波形,且在静默段不过拟合噪声。
图4显示了在语音活跃期和静默期,不同模型(HPNN, WaveNet, VNN, FIR)对LSK1和LSK3的预测输出波形(红色)与真实波形(蓝色)的对比。它直观地展示了HPNN能紧密跟踪真实波形,且在静默段不过拟合噪声。
消融与分析:
- 论文通过对比FIR模型(纯线性)与非线性模型(HPNN, WaveNet, VNN)的频域误差(Table 2),直接证明了非线性建模的必要性。例如在400Hz, FIR的All NMSE为1.58 dB(正值表示误差极大),而HPNN为-12.02 dB。
- 对HPNN架构设计的消融实验(如移除多项式层、改变物理映射方式)在论文中未进行。
⚖️ 评分理由
- 学术质量:5.0/7。论文动机清晰,问题定义准确。提出的“语音激励范式”和“物理启发式HPNN”模型在针对特定问题时设计合理,并通过充分的对比实验验证了其有效性(效率与精度的平衡)。技术方案正确,证据可信。但创新性主要体现在工程优化和问题定制上,属于应用层面的改进,而非基础理论或方法论上的重大突破。缺少对HPNN各模块贡献的消融实验,以及对语音激励优势的量化分析(与扫频激励训练的模型在相同测试集上对比)。
- 选题价值:1.5/2。该问题对移动设备、可穿戴设备中的音频系统设计与性能提升具有明确的实用价值和应用前景。选题垂直、具体,与音频系统建模和信号处理领域的从业者高度相关。虽然领域不算最前沿,但扎实的工程解决方案具有实际意义。
- 开源与复现加成:-0.5/1。论文明确强调了“生态效度”和“快速原型”,但却完全未提供代码、模型权重、训练数据或详细的超参数配置,使得其宣称的“新范式”难以被第三方验证和复用。这对于一篇旨在推动新方法应用的研究来说,是一个显著的短板。