📄 A Robust KNN Approach for Multi-Class Laryngeal Disease Detection using MFCC Features
#音频分类 #信号处理 #图神经网络 #医疗AI #鲁棒性
✅ 7.5/10 | 前25% | #音频分类 | #信号处理 | #图神经网络 #医疗AI
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 中
👥 作者与机构
- 第一作者:Pingping Wu(南京审计大学工程审计学院)
- 通讯作者:未说明
- 作者列表:
- Pingping Wu(南京审计大学工程审计学院)
- Weijie Gao(南京审计大学计算机科学学院)
- Haibing Chen(江苏省人民医院耳鼻喉科)
💡 毒舌点评
本文将图神经网络(GNN)引入传统的K近邻(KNN)分类框架,为病理语音特征建模提供了一个有趣的视角,这是其最亮眼的创新点。然而,论文对所提出图增强KNN中GNN的具体实现(如层数、聚合器类型、注意力机制)和关键超参数(如K值选择)的讨论严重不足,使得“图”这一核心概念的魔力显得有些“黑箱”,也给复现设置了不必要的障碍。此外,使用一个仅320例、未公开的临床数据集得出的结论,其泛化能力有待未来更大规模数据的验证。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:数据集来自合作医院,论文未提及是否公开或获取方式。
- Demo:未提供在线演示。
- 复现材料:论文详细说明了MFCC提取参数(采样率、帧长、帧移、滤波器组数量)、数据划分比例、交叉验证方法以及实验的软硬件环境(Table 2),这些信息有助于在相同条件下复现实验。
- 引用的开源工具:论文明确提到了使用
librosa库(版本0.10)进行音频处理和特征提取。 - 总结:论文中未提及开源计划(代码、数据、模型均未公开)。
📌 核心摘要
- 问题:喉部疾病(如癌症、息肉、结节、白斑)的早期无创检测对改善预后至关重要,而传统的内窥镜检查受限于设备和专家。现有研究多集中于简单的二分类,对多种疾病的精细分类探索不足。
- 方法核心:提出一种图增强的KNN框架。首先从语音信号中提取MFCC特征序列,然后为每个样本构建基于特征相似度的K近邻图,最后利用图神经网络(GNN)在图上进行信息聚合,学习更具判别性的表示,最终进行分类。
- 创新点:1) 首次将多种非癌症性喉部病变(息肉、结节、白斑)纳入统一的五分类框架进行研究;2) 将图神经网络与KNN结合,通过建模局部拓扑关系来增强传统距离度量的判别能力,这是对标准KNN分类器的一种结构性改进。
- 主要结果:在自建的320例患者数据集上,该方法在二分类(健康 vs 病变)任务中达到96%的准确率,在五分类(健康、癌症、息肉、结节、白斑)任务中达到88%的准确率,均优于包括CNN和传统KNN在内的基线模型。关键数据对比如下表所示:
模型 二分类准确率 五分类准确率 传统KNN 0.94 0.83 CNN 0.94 0.80 本文方法 (Ours) 0.96 0.88 - 实际意义:该研究验证了基于语音的、结合图结构的机器学习模型在非侵入式喉部疾病筛查中的潜力,为临床早期诊断提供了新的技术思路。
- 主要局限性:数据集规模较小(320例)且未公开,模型泛化性存疑;对图神经网络部分的实现细节描述不够深入,技术贡献的清晰度和可复现性有所折扣。
🏗️ 模型架构
本文提出的模型整体流程(如图1所示)可分为四个主要阶段:
- MFCC特征提取:输入为原始语音信号。经过静音去除、归一化、分帧、加窗、STFT、Mel滤波器组、对数运算和DCT变换,提取出13维静态MFCC特征。再计算一阶和二阶差分,最终得到每帧39维的特征向量。整个语音片段形成一个MFCC特征序列。
- 图构建:将每个语音片段(或帧)视为图中的一个节点,节点的特征即为对应的39维MFCC向量。对于任意两个节点i和j,若它们的MFCC特征是彼此的K个最近邻之一(基于欧氏距离),则在它们之间建立一条边。边的权重定义为特征距离的倒数(加一个小常数防除零),表示相似度。最终构建一个稀疏的K近邻图。
- 图神经网络(GNN)聚合:在构建的图上运行GNN(如GCN或GAT)。每一层通过聚合邻居节点的信息来更新当前节点的表征。论文给出了标准的聚合公式:
h_i^{(l+1)} = σ(∑_{j∈N(i)} α_{ij} W h_j^{(l)})。其中W是可学习的权重矩阵,α_{ij}是归一化的边权重。这个过程可以重复多层,以捕捉更高阶的邻域信息。 - 分类:经过L层GNN处理后,每个节点都获得了一个富含上下文信息的嵌入向量。为了得到整个语音片段的表征,对图中所有节点的嵌入进行图级池化(如平均池化或最大池化)。池化后的向量再通过一个全连接层和softmax分类器,输出各类疾病的概率分布,进行最终预测。
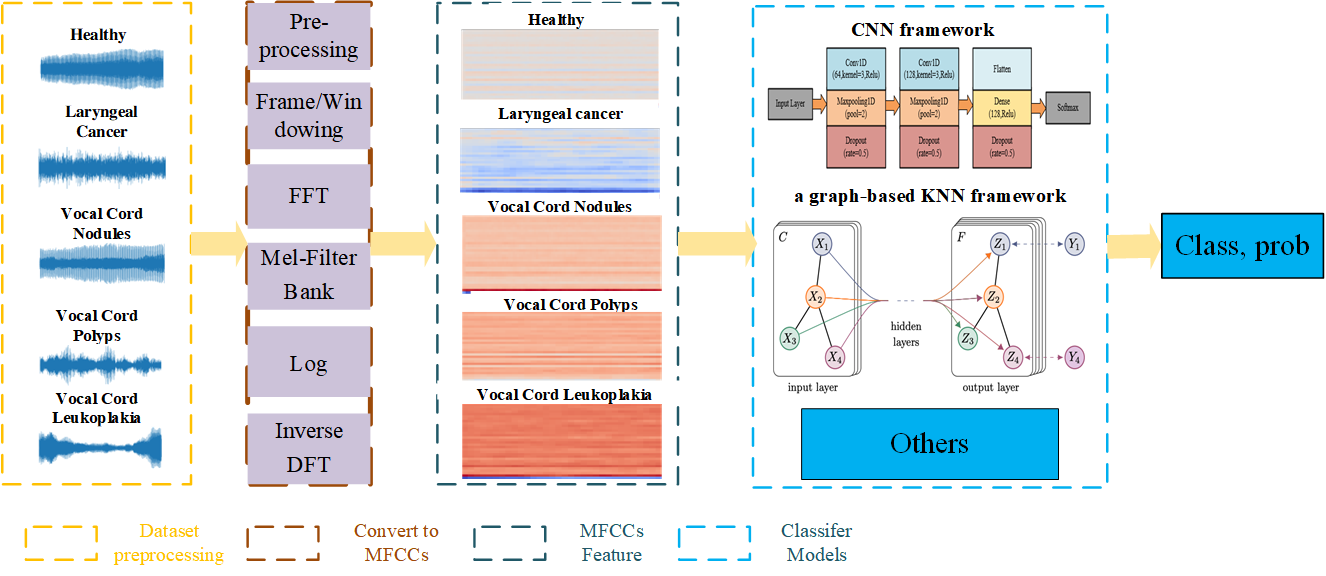 图1 展示了从语音信号输入,经过MFCC提取、图构建、GNN聚合到最终分类的完整数据流。
图1 展示了从语音信号输入,经过MFCC提取、图构建、GNN聚合到最终分类的完整数据流。
关键设计选择:
- 动机:传统KNN仅基于距离投票,对噪声和高维特征空间敏感,且无法捕捉非线性关系。通过引入图结构并用GNN学习,模型能够自适应地加权邻居的重要性,并整合局部结构信息,从而形成更鲁棒的判别边界。
- 交互:GNN是整个框架的核心计算单元,它在预构建的拓扑结构上操作,利用特征相似度(通过图边体现)来引导信息流动,实现了数据驱动的关系建模。
💡 核心创新点
- 图增强KNN框架:这是论文最核心的创新。它没有将KNN视为一个简单的分类器,而是将其转化为一个图上的表示学习问题。通过构建邻域图并利用GNN进行特征聚合,将静态的距离计算升级为动态的、可学习的结构化推理,显著提升了分类性能,尤其是在更具挑战性的多类别任务中。
- 多类别喉部疾病检测统一框架:据作者声称,这是首次将多种良性病变(息肉、结节、白斑)与喉癌、健康对照整合到一个五分类系统中进行研究和比较,拓宽了病理语音分析的研究范畴,更贴近临床实际中的鉴别诊断需求。
- 临床语音数据集构建与评估:论文收集了一个包含320名受试者、涵盖五种状态的高质量临床语音数据集,并系统评估了多种传统机器学习和深度学习方法,为该领域的后续研究提供了有价值的基线数据和参考。
🔬 细节详述
- 训练数据:来自江苏省人民医院耳鼻喉科的320名患者。包含喉癌(86例)、声带息肉(153例)、声带结节(44例)、声带白斑(44例)和健康对照(93例)五个类别。数据采集了持续元音/a/和标准中文句子。数据集被划分为80%训练集和20%测试集,训练集内进行5折交叉验证。
- 数据预处理:音频被重采样至22050Hz,归一化,静音和噪声部分被移除。使用1秒窗口、50%重叠的滑动窗口进行分段,以增加数据量和捕捉动态特征。
- 特征提取:使用librosa库提取MFCC。参数设置:采样率22050Hz,帧长25ms,帧移10ms,128个Mel滤波器组。最终每帧得到39维特征(13静态 + 一阶差分13 + 二阶差分13)。
- 损失函数:论文未明确说明损失函数,从分类任务和最终使用softmax分类器推断,应为交叉熵损失(Cross-Entropy Loss)。
- 训练策略:
- 优化器、学习率、调度策略:论文未说明。
- Batch size、训练轮数:未提供具体数值。Table 2显示训练轮数为100,但未说明是针对GNN模型还是其他基线。
- GNN模型细节:论文仅给出了GNN层更新的通用公式,未指明具体使用了GCN、GAT还是其他变体,也未说明图网络的深度(层数)、隐藏层维度、是否使用残差连接、归一化等关键技术细节。这是本部分最大的信息缺失。
- 关键超参数:KNN中的K值(邻域大小)是关键超参数,但论文未给出其选取值或选取策略。
- 训练硬件:在NVIDIA RTX 4070 SUPER (12GB) GPU上进行,环境为PyTorch 1.11.0,Python 3.8。
- 推理细节:未说明。
- 正则化技巧:未说明。
📊 实验结果
论文在二分类(健康 vs 所有疾病)和五分类任务上与多种基线模型进行了对比。主要结果汇总如下表:
表3. 论文分类性能对比结果
| 模型 | 二分类准确率 | 二分类F1 | 五分类准确率 | 五分类F1 |
|---|---|---|---|---|
| 随机森林 (RF) | 0.94 | 0.66 | 0.75 | 0.73 |
| 支持向量机 (SVM) | 0.57 | 0.56 | 0.55 | 0.49 |
| K近邻 (KNN) | 0.94 | 0.86 | 0.83 | 0.81 |
| 逻辑回归 (LR) | 0.77 | 0.75 | 0.60 | 0.55 |
| 朴素贝叶斯 (NB) | 0.80 | 0.63 | 0.46 | 0.56 |
| 多层感知机 (MLP) | - | - | 0.66 | 0.65 |
| 卷积神经网络 (CNN) | 0.94 | 0.85 | 0.80 | 0.78 |
| 本文方法 (Ours) | 0.96 | 0.96 | 0.88 | 0.88 |
关键结论:
- 在所有模型中,本文提出的图增强KNN在两项任务上均取得了最高的准确率和F1分数,验证了其有效性。
- 二分类任务相对简单,多数模型(RF, KNN, CNN)都能达到94%以上的准确率,但本文方法仍有微小优势。
- 五分类任务更具挑战性,模型间性能差距拉大。传统KNN(0.83)表现优于CNN(0.80),而本文方法在传统KNN基础上通过图学习进一步提升了5个百分点(达到0.88),说明图结构建模确实捕捉到了更有效的疾病鉴别模式。
- 消融实验:论文未提供针对图模块(如去掉GNN仅用传统KNN)、图构建参数(如K值、边权公式)或特征选择的消融实验,这使得无法精确量化图建模带来的具体贡献。
⚖️ 评分理由
- 学术质量:5.5/7:创新性较强,将GNN与KNN结合用于语音疾病检测的思路新颖且有效。技术路线基本正确,实验设计合理,包含了多类基线对比。主要扣分点在于核心组件GNN的实现细节描述模糊,缺乏消融实验,且基于单一小数据集,限制了结论的普适性和技术细节的透明度。
- 选题价值:1.5/2:选题具有明确的临床应用导向和非侵入性优势,属于语音处理在医疗健康领域的有价值的垂直应用。虽然不是最前沿的学术热点(如大模型),但其社会价值和实用潜力明确。
- 开源与复现加成:0.5/1:论文提供了数据采集、预处理、特征提取和训练环境的关键参数,为复现提供了良好基础。但因未公开代码、数据集和模型权重,完全复现存在障碍,故给予中等加分。