📄 A Parameter-Efficient Multi-Scale Convolutional Adapter for Synthetic Speech Detection
#音频深度伪造检测 #自监督学习 #语音伪造检测 #迁移学习 #参数高效微调
✅ 7.0/10 | #音频深度伪造检测 #自监督学习
👥 作者与机构
- 第一作者:Yassine El Kheir(DFKI, Germany;Gretchen AI, Germany)
- 通讯作者:未说明
- 作者列表:Yassine El Kheir(DFKI, Germany;Gretchen AI, Germany)、Fabian Ritter-Guttierez(Nanyang Technological University, Singapore)、Arnab Das(DFKI, Germany;Gretchen AI, Germany)、Tim Polzehl(DFKI, Germany;Gretchen AI, Germany)、Sebastian Moller(DFKI, Germany;Technical University of Berlin, Germany)
💡 毒舌点评
亮点在于设计了一个巧妙的参数高效适配器,用仅1%的参数就显著超越了全微调方法,在效率与性能的权衡上取得了亮眼成绩。但短板也很明显:论文没有提供代码或模型链接,让复现成了“开卷考试但没带书”;另外,对多尺度特征融合的物理意义(如具体哪些特征对应短时/长时伪影)缺乏更深入的可视化分析或解释。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了多个公开的基准数据集(ASVspoof系列, ITW, MLAAD),但未提供经过处理的或增强后的数据集。
- Demo:未提供在线演示。
- 复现材料:论文提供了较为详细的实现细节(超参数、优化器设置、数据增强方法等),但未提供训练脚本、配置文件或预训练模型,复现仍需较多工作。
- 论文中引用的开源项目:引用了Wav2Vec2.0/XLSR, HuBERT, WavLM, AASIST等模型,并提到了LoRA、Houlsby Adapter、ConvAdapter等方法作为对比基线,但未明确说明是否依赖特定开源实现。
📌 核心摘要
这篇论文针对现有基于自监督学习(SSL)的语音合成检测模型在全微调时计算成本高、而通用参数高效微调(PEFT)方法缺乏捕捉音频多尺度时间伪影的特定归纳偏置这一问题,提出了一种新的多尺度卷积适配器(MultiConvAdapter)。该方法的核心是在SSL骨干网络(如XLSR)的Transformer层中的多头自注意力(MHSA)模块后,插入一个并行的、使用不同大小卷积核的深度卷积模块,使模型能同时学习短时伪影和长时失真。与已有方法(如LoRA、Houlsby适配器)相比,新方法显式地引入了针对音频时间结构的先验知识。主要实验结果表明,在五个公开数据集(ASVspoof LA19、DF21、ITW、MLAAD、ASV5)上,MultiConvAdapter仅使用3.17M可训练参数(仅为317M骨干模型的1%),其平均EER(等错误率)达到5.91%,相比全微调方法(7.07%)相对降低了16.41%,并优于其他PEFT方法(如LoRA为8.43%)。该方法的意义在于为部署高效、鲁棒的合成语音检测系统提供了一种可行的参数高效解决方案。主要局限性在于论文未公开代码和模型,且分析局限于标准数据集,未探讨在极端对抗环境或更复杂编解码条件下的泛化能力。
🏗️ 模型架构
论文提出的MultiConvAdapter架构旨在增强预训练SSL模型(如XLSR、HuBERT)对合成语音检测任务的适应性,其整体流程如下:
- 输入与骨干网络:输入音频波形被截断或填充至4秒(64,600采样点)。使用预训练的SSL模型(如XLSR)作为特征提取骨干,其包含卷积编码器和多层Transformer编码器。SSL模型输出序列特征 Hl ∈ R^{B×T×D}(B:批次大小,T:序列长度,D:嵌入维度)。
- 适配器放置与流程:MultiConvAdapter被插入到每个Transformer层的MHSA子层之后。首先,将MHSA的输出Hl通过一个投影下采样层(Proj Down,全连接层)映射到低维空间 H′l ∈ R^{B×T×D′},其中D′(论文中为64)远小于D,以降低计算复杂度。
- 并行多尺度卷积模块:低维特征H′l在通道维度上被分割为N个头(论文中N=4)。每个头由一个独立的1D深度卷积层处理,每个卷积层使用不同的核大小(如{3,7,15,23})。深度卷积确保每个通道的特征被独立处理,使模型能并行提取不同时间分辨率的特征:小核(如3)捕捉局部高频伪影,大核(如23)建模更长期的失真。
- 特征融合与输出:所有卷积头的输出在通道维度上拼接,然后通过一个融合模块(Mixup Conv)进行交互。该模块是一个带有残差连接的1D卷积(核大小为3),其作用是让不同尺度的特征能够相互融合,学习跨尺度的组合模式。最后,通过一个投影上采样层(Proj Up)将特征维度恢复回原始D。
- 整体数据流:
输入音频 -> SSL骨干特征提取 -> 在每个Transformer层的MHSA后并行插入MultiConvAdapter -> 最终特征送入AASIST分类器进行二分类判断。
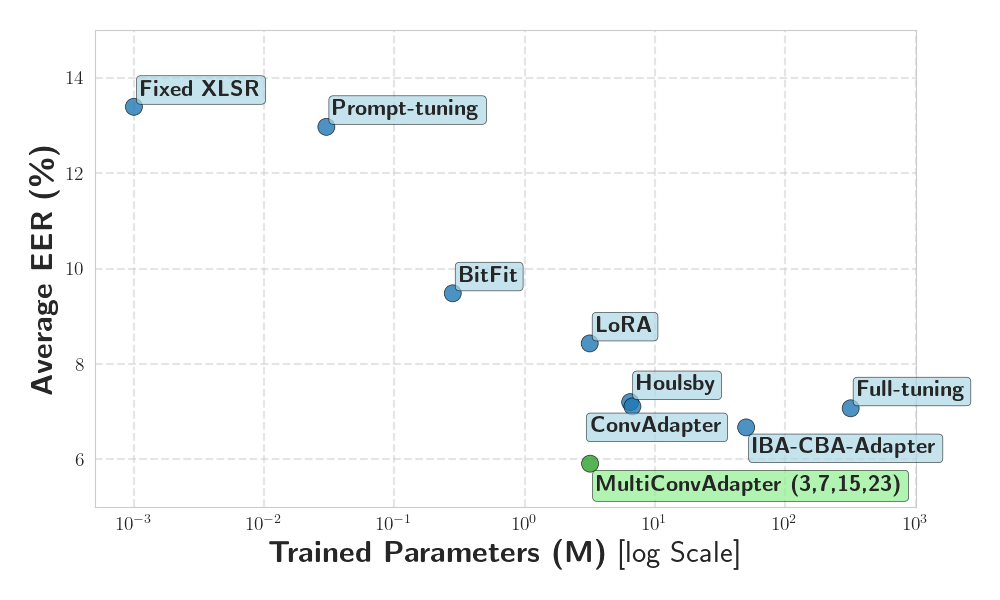
图1展示了不同PEFT方法的“可训练参数 vs EER%”权衡曲线,突出显示了MultiConvAdapter在极低参数下取得最优EER的定位。 图2(论文中提及但未提供URL)展示了MultiConvAdapter模块在Transformer块中的具体位置及其内部结构,包括并行的1D深度卷积、Mixup Conv融合层以及投影层。
关键设计选择:
- 并行多尺度卷积:动机源于合成语音伪影的多尺度特性(短时与长时),而单一尺度的适配器(如LoRA、Houlsby)无法有效捕捉所有尺度的信息。
- 深度卷积:在效率上,深度卷积的参数量远少于标准卷积;在建模上,它将时域建模与通道建模解耦,允许每个尺度专注于时间模式。
- 放置在MHSA之后:旨在利用MHSA提供的全局上下文信息,再通过卷积引入针对局部时间模式的强归纳偏置。
- Mixup Conv融合:比简单的拼接或求和更能促进不同尺度特征之间的信息流动和学习跨尺度交互。
💡 核心创新点
- 显式多尺度时间建模的适配器:首次为语音伪造检测任务设计了集成多尺度卷积核的适配器架构,直接针对伪造语音中存在短时伪影和长时失真的特性,弥补了现有PEFT方法(如LoRA的代数低秩假设、Houlsby的MLP瓶颈)缺乏音频结构先验的不足。
- 极高的参数效率:通过并行深度卷积和瓶颈设计,在仅引入约1%骨干网络参数(3.17M)的情况下,实现了优于全微调(100%参数)和其他PEFT方法的性能,提供了优异的准确性-效率权衡。
- 有效的融合机制(Mixup Conv):提出使用带残差的1D卷积作为融合模块,而非简单的拼接或求和,实验证明这能显著提升模型在域外数据(如ITW, MLAAD, ASV5)上的泛化能力,因为它能建模跨尺度特征的相互作用。
- 强鲁棒性与泛化性:在多个不同的SSL骨干(XLSR, HuBERT, WavLM)和五个具有不同攻击类型、录音条件的数据集上均取得一致性的性能提升,证明了该架构设计的通用性。
🔬 细节详述
- 训练数据:
- 使用ASVspoof 2019���辑访问(LA19)数据集的官方划分进行训练和验证。
- 测试在五个数据集上进行:LA19测试集、ASVspoof2021深度伪造(DF21)、In-The-Wild(ITW)、MLAAD(v3英文子集)、ASVspoof5(ASV5)。数据集规模和描述在论文第3.1节有详细说明。
- 数据增强:论文提及应用了噪声注入、混响和SpecAugment。
- 损失函数:交叉熵损失(Cross-Entropy Loss)。
- 训练策略:
- 优化器:Adam, β1=0.9, β2=0.999。
- 学习率:1×10^{-5}。
- 权重衰减:1×10^{-4}。
- 批次大小:14。
- 训练轮数:50个epochs。
- 结果报告:所有结果基于三个不同随机种子的实验取平均值。
- 关键超参数:
- MultiConvAdapter的低维投影维度 D′=64。
- 默认卷积核大小配置为 {3, 7, 15, 23}。
- 作为对比的LoRA方法秩(rank)为16。
- Houlsby适配器的投影维度也设置为64以保证公平对比。
- 训练硬件:单张NVIDIA H100 GPU。未说明具体训练时长。
- 推理细节:未说明。
- 正则化:除数据增强和权重衰减外,未提及其他特定正则化技巧。
📊 实验结果
主要性能对比(表1, 平均EER%, ↓表示越低越好):
| 方法 | 参数量 | LA19 | DF21 | ITW | MLAAD | ASV5 | AVG |
|---|---|---|---|---|---|---|---|
| Full-tuning (XLSR) | 317 M | 0.35 | 2.60 | 9.43 | 15.86 | 7.12 | 7.07 |
| Fixed XLSR | 0 M | 1.52 | 7.02 | 29.70 | 17.03 | 11.69 | 13.39 |
| Prompt-tuning | 0.03 M | 1.79 | 5.90 | 24.71 | 20.97 | 11.50 | 12.97 |
| BitFit | 0.28 M | 0.79 | 3.06 | 13.64 | 18.53 | 11.37 | 9.48 |
| LoRA | 3.15 M | 0.61 | 4.33 | 13.15 | 16.85 | 7.22 | 8.43 |
| Houlsby | 6.44 M | 0.58 | 2.88 | 10.55 | 15.57 | 6.42 | 7.20 |
| ConvAdapter | 6.70 M | 0.67 | 2.23 | 9.81 | 16.70 | 6.13 | 7.11 |
| IBA-CBA-Adapter | 50 M | 0.42 | 2.07 | 8.47 | 15.86 | 6.52 | 6.67 |
| MultiConvAdapter {3,7,15,23} | 3.17 M | 0.56 | 1.89 | 7.92 | 13.23 | 5.97 | 5.91 |
| MultiConvAdapter {7,15,23,31} | 3.17 M | 0.27 | 1.75 | 8.29 | 17.31 | 6.41 | 6.81 |
关键发现:
- MultiConvAdapter({3,7,15,23})以5.91%的平均EER,在仅用3.17M参数的情况下,显著优于全微调(7.07%,参数多100倍)和所有其他PEFT方法。
- 相比参数量相近的LoRA(3.15M, AVG EER 8.43%),取得了29.9%的相对EER降低。
- 相比参数量更大的IBA-CBA-Adapter(50M),平均EER从6.67%降至5.91%,性能更优且参数少约94%。
- 在最具挑战性的域外数据集MLAAD和ASV5上,该方法取得了最佳性能(13.23%和5.97%)。
核大小消融实验(表2):
| 核配置 | AVG EER |
|---|---|
| 无核(∅) | 7.42 |
| 单头{15} | 6.66 |
| 两头{3,23} | 6.56 |
| 四头{3,7,15,23} | 5.91 |
关键发现:引入多尺度核显著优于单尺度或无核;默认的{3,7,15,23}配置在平均性能和泛化能力上最佳。
融合策略与位置消融(表3):
| 设置 | AVG EER |
|---|---|
| Mixup Conv (默认) | 5.91 |
| 加权求和 | 6.76 |
| 拼接 | 7.12 |
| 求和 | 7.30 |
| 适配器仅在FFN后 | 7.04 |
| 适配器在MHSA和FFN后 | 6.39 |
关键发现:Mixup Conv融合显著优于其他聚合策略;适配器放在MHSA之后效果最佳。
此图(论文中的图1)直观展示了MultiConvAdapter在参数-EER权衡上的优势:它位于曲线的左下角区域,意味着在参数极少的条件下达到了最低的EER。
⚖️ 评分理由
- 学术质量:6.0/7 论文提出了一个设计合理、目标明确的适配器架构,创新性地将多尺度卷积引入语音伪造检测的PEFT任务,解决了现有方法的局限性。实验设计全面,包含多个数据集、多个骨干网络以及充分的消融研究(核配置、融合策略、位置),证据可信。主要扣分点在于:虽然实验充分,但未能在所有数据集上都取得最优(如LA19上并非最优),且论文未提供代码,使得其声称的复现性存在一定折扣。
- 选题价值:1.5/2 语音合成检测是当前AI安全领域的重要前沿问题,具有明确的应用价值。该方法聚焦于提高检测模型的部署效率和泛化能力,与工业界和学术界的需求高度相关。但任务本身相对垂直,非最大众的语音AI方向。
- 开源与复现加成:-0.5/1 这是论文最大的短板。论文中未提及任何代码、预训练模型或配置文件的开源计划。虽然详细描述了实验设置,但缺乏关键的实现细节和检查点,极大地限制了研究的可复现性和即时影响力。因此给予负分。