📄 A New Method and Dataset for Classroom Teaching Stage Segmentation
#课堂阶段分割 #多模态融合 #教育技术 #数据集
✅ 6.5/10 | 前25% | #课堂阶段分割 | #多模态融合 | #教育技术 #数据集
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Shihao Yang(东北师范大学信息科学学院)
- 通讯作者:Shuhua Liu(东北师范大学信息科学学院,邮箱:liush129@nenu.edu.cn)
- 作者列表:Shihao Yang(东北师范大学信息科学学院)、Nan Zhang(东北师范大学信息科学学院)、Yue Jiang(东北师范大学信息科学学院)、Ziyi Zhang(东北师范大学信息科学学院)、Shuhua Liu(东北师范大学信息科学学院)
💡 毒舌点评
本文最大亮点是首次明确定义了“课堂教学阶段分割”这一任务并构建了首个大规模多模态数据集,为教育过程分析提供了重要的基准和基础设施。然而,其提出的“多模态聚类-分离损失”与“熵权动态加权”方法在技术原创性上略显保守,更多是已有技巧在特定任务上的组合应用,动态加权策略带来的性能提升(如表2中从63.17到66.85)虽显著但幅度有限。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:论文构建并介绍了TSS数据集,包含1,928节课和详细划分,但未提及数据集的具体公开或获取方式。
- Demo:未提及。
- 复现材料:提供了训练的主要超参数(学习率、batch size、epoch数、损失权重)和硬件配置,但部分细节(如优化器、数据预处理代码)未说明。
- 论文中引用的开源项目:提到了使用的预训练模型(Bart, Longformer, TimeSformer, wav2vec2)和工具(讯飞语音转写API)。
📌 核心摘要
这篇论文首次聚焦于“课堂教学阶段分割”任务,旨在将完整的教学过程自动划分为复习、导入、讲解、总结和布置作业等逻辑阶段,以支持师范生培训和教学评估。为此,作者构建了一个包含1928节课、涵盖文本、音频、视频三种模态的大规模数据集(TSS),这是该领域的首个专用数据集。方法上,提出了一种多模态融合框架,其核心创新在于设计了“聚类损失”和“分离损失”以增强阶段内语义一致性与阶段间区分度,并采用基于信息熵的动态加权策略来融合多模态信息,自适应抑制噪声模态。实验表明,该多模态方法在Pk、WD、MacroF1等指标上显著优于仅使用文本的基线及最新的大语言模型(如Longformer基线在多模态动态加权下MacroF1达到66.85)。该研究为智能教育提供了新的技术路径,但其方法的普适性及数据集在不同文化、学科背景下的泛化能力仍需进一步验证。
🏗️ 模型架构
该模型是一个多模态序列标注(边界检测)框架,旨在对教学过程中的每个句子进行边界预测(0或1)。整体流程如下:
- 多模态特征编码:输入对齐的句子级文本、视频片段和音频片段,分别通过预训练的文本编码器(Bart或Longformer)、视频编码器(TimeSformer)和音频编码器(wav2vec2),得到句子级别的特征向量
vi,t,vi,v,vi,a。关键设计是三模态在时间线上严格对齐,避免了繁琐的模态对齐操作。 - 动态模态加权:为了融合不同模态的信息并自适应地调整重要性,提出基于熵的动态加权。对于每个模态m,先通过一个线性层和sigmoid函数得到其预测概率
pi,m。然后计算该模态的不确定性(熵值)Hi,m。模态权重wi,m与熵值成反比(公式1,2),即不确定性(噪声)越高的模态,其权重越低。最终的多模态融合概率pi,f是各模态概率的加权平均(公式3)。 - 损失优化:模型不仅使用标准的边界检测损失(加权二元交叉熵损失
LBCE),还创新性地引入了两个针对阶段表示的损失函数(如图2(b)所示):- 语义聚类损失 (
Lcluster):促使同一阶段内的所有句子特征向量向该阶段的质心靠拢,增强阶段内一致性。 - 全局分离损失 (
Lsep):拉大不同阶段质心之间的距离,增强阶段间的区分度。 三个损失以加权和的形式构成最终联合损失Ltotal。
- 语义聚类损失 (
- 输出:根据融合概率
pi,f与阈值(0.5)比较,输出二值化的边界预测结果。
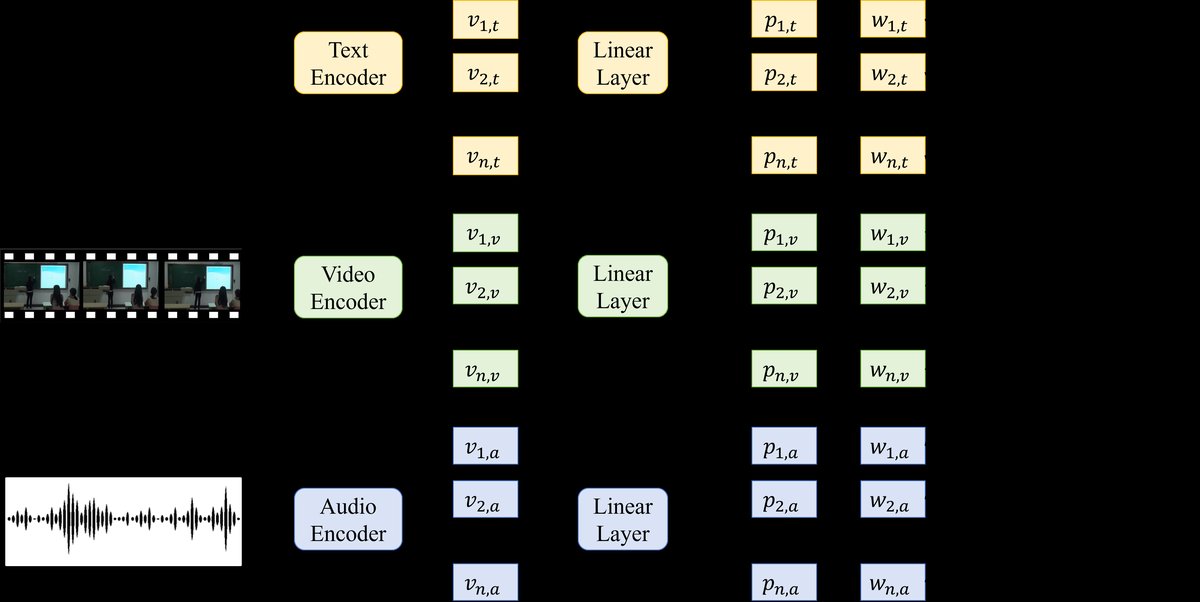
图2(a) 展示了模型的整体架构:输入是多模态句子特征,经过动态加权融合后,得到最终的预测概率。图2(b) 详细说明了联合损失的构成:对所有模态的特征表示,分别计算聚类损失、分离损失,并与边界检测损失结合。
💡 核心创新点
- 定义新任务与构建首个数据集:首次提出“课堂教学阶段分割”这一具有明确教育学背景的任务,并构建了包含近2000节课、三模态对齐的大规模专用数据集(TSS)。这是填补领域空白的基础性贡献,为后续研究提供了基准。
- 多模态聚类-分离损失框架:针对教学阶段内语义相似、阶段间边界模糊的挑战,设计了联合损失函数。
Lcluster保证同一教学阶段的内容在特征空间紧凑,Lsep则拉远不同阶段的表示。这种在表示空间直接施加结构约束的方法,有效增强了模型对阶段边界的判别能力。 - 基于熵的动态模态加权策略:摒弃了固定的多模态融合权重,提出根据每个模态预测的不确定性(信息熵)动态分配权重。这使得模型在融合时能够自动抑制噪声较大或信息量不足的模态(如某节课中视频信息可能不关键),提高了融合的鲁棒性和准确性。
🔬 细节详述
- 训练数据:TSS数据集,包含1,928节课(平均78.37句/课),分为训练(1,542)、验证(193)、测试(193)集(8:1:1)。数据来源于10分钟以内的课堂录像,包含5种教学阶段。音视频和转录文本通过讯飞API提取并对齐。
- 损失函数:
Lcluster:最小化同阶段句子与阶段质心的余弦距离之和(公式4, 5)。Lsep:最小化不同阶段质心间的余弦相似度(公式6)。LBCE:加权二元交叉熵损失(公式7),权重因子α=0.2,用于缓解正负样本(边界句子 vs. 非边界句子)不平衡问题。Ltotal= 1.0Lcluster+ 0.2Lsep+ 1.0 *LBCE。
- 训练策略:
- 优化器:未明确说明,但学习率设为5e-5。
- Batch Size:4。
- 训练轮数:20 epochs,使用早停法。
- 硬件:单卡NVIDIA RTX 4090 GPU,Intel i9-12900K CPU,64GB内存。
- 关键超参数:
- 文本编码器:Bart 或 Longformer。
- 视频编码器:TimeSformer。
- 音频编码器:wav2vec2。
- 动态加权中的平滑因子
ε = 10^{-6}。
- 推理细节:未详细说明解码策略,推测为直接根据概率阈值(0.5)输出二值标签。
- 正则化技巧:使用了早停法防止过拟合。
📊 实验结果
实验在TSS测试集上进行,评估指标为Pk↓、WD↓(越低越好)和MacroF1↑(越高越好)。关键结果如下:
表2:不同模态组合与损失函数的消融实验
| Text Encoder | Video Encoder | Audio Encoder | Cluster loss | Sep loss | BCE loss | Fusion Method | Pk ↓ | WD ↓ | MacroF1↑ |
|---|---|---|---|---|---|---|---|---|---|
| Bart | × | × | × | × | ✓ | × | 22.23 | 23.41 | 56.85 |
| Bart | × | × | ✓ | × | ✓ | × | 22.06 | 22.88 | 57.32 |
| Bart | × | × | ✓ | ✓ | ✓ | × | 19.25 | 20.50 | 59.58 |
| Longformer | × | × | × | × | ✓ | × | 20.62 | 22.54 | 57.82 |
| Longformer | × | × | ✓ | × | ✓ | × | 20.20 | 21.85 | 58.33 |
| Longformer | × | × | ✓ | ✓ | ✓ | × | 19.47 | 18.98 | 61.36 |
| Bart | TimeSformer | Wav2vec2 | × | × | ✓ | Avg | 21.12 | 23.22 | 57.84 |
| Bart | TimeSformer | Wav2vec2 | ✓ | × | ✓ | Avg | 21.06 | 21.21 | 58.69 |
| Bart | TimeSformer | Wav2vec2 | ✓ | ✓ | ✓ | Avg | 18.70 | 18.53 | 61.56 |
| Bart | TimeSformer | Wav2vec2 | ✓ | ✓ | ✓ | D.W.avg | 15.78 | 16.32 | 62.20 |
| Longformer | TimeSformer | Wav2vec2 | × | × | ✓ | Avg | 19.50 | 20.84 | 59.26 |
| Longformer | TimeSformer | Wav2vec2 | ✓ | × | ✓ | Avg | 18.17 | 20.56 | 61.33 |
| Longformer | TimeSformer | Wav2vec2 | ✓ | ✓ | ✓ | Avg | 15.95 | 17.55 | 63.17 |
| Longformer | TimeSformer | Wav2vec2 | ✓ | ✓ | ✓ | D.W.avg | 13.32 | 15.76 | 66.85 |
关键结论:
- 损失函数有效:在单模态(文本)和多模态场景下,引入聚类损失(Cluster loss)和分离损失(Sep loss)均能稳定提升性能(比较每组的前三行)。例如,Longformer文本模型在加入两个损失后,MacroF1从57.82提升至61.36。
- 多模态融合有效:全模态(文本+视频+音频)在简单平均(Avg)下已优于单模态(对比第4行和第11行)。
- 动态加权有效:在多模态全损失配置下,熵权动态加权(D.W.avg)相比简单平均进一步显著提升了性能(例如Longformer系列,MacroF1从63.17提升至66.85,Pk和WD大幅下降)。这证明了动态加权抑制噪声模态的能力。
表3:边界检测损失中负样本权重α的影响
| α | Pk↓ | WD↓ | Macro F1↑ |
|---|---|---|---|
| 0.1 | 14.52 | 17.36 | 60.20 |
| 0.2 | 13.32 | 15.76 | 66.85 |
| 0.33 | 15.69 | 17.82 | 58.33 |
| 1 | 44.51 | 53.28 | 16.36 |
关键结论:α=0.2时性能最优,α=1(即不加权)时性能急剧下降,验证了处理样本不平衡的重要性。
表4:与大语言模型(LLM)的对比实验
| Method | Pk↓ | WD↓ | Macro F1↑ |
|---|---|---|---|
| Llama3.2-3B | 40.23 | 48.52 | 12.32 |
| Qwen3-235B | 24.51 | 26.85 | 43.48 |
| Ours(t) | 19.47 | 18.98 | 61.36 |
| Ours(t,v,a) | 13.32 | 15.76 | 66.85 |
关键结论:即使仅使用文本(Ours(t)),本方法也远优于强大的通用LLM(Llama3.2-3B, Qwen3-235B)。加入多模态信息后(Ours(t,v,a)),性能进一步大幅领先。这表明针对特定任务设计的模型和损失函数,比通用大模型更有效。
⚖️ 评分理由
- 学术质量(5.5/7):论文贡献清晰(新任务、新数据集、新框架),技术方案合理且实验验证充分。扣分点在于:1)核心方法(聚类/分离损失、熵权法)并非全新,属于在特定任务上的有效应用;2)与LLM的对比虽显示优势,但对比的LLM是否针对该任务进行了优化(如微调)未说明;3)数据集虽规模可观,但未讨论数据质量(标注一致性)和数据集偏置(学科、地区)。
- 选题价值(1.5/2):选题精准切入教师教育和课堂教学分析的痛点,具有明确的应用场景和实际意义,是教育技术领域一项有价值的基础设施和方法探索。
- 开源与复现加成(0.0/1):论文公开了数据集的基本信息,但未提供获取方式、标注细节或代码。训练超参数和硬件信息提供了一定复现基础,但模型具体实现(如线性层细节)和预处理流程描述不足,复现门槛较高。