📄 A Learning-Based Automotive Sound Field Reproduction Method Using Plane-Wave Decomposition and Multi-Position Constraint
#空间音频 #波束成形 #深度学习 #多通道 #汽车音频
✅ 7.5/10 | 前25% | #空间音频 | #波束成形 #深度学习 | #波束成形 #深度学习
学术质量 6.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Yufan Qian(北京大学智能科学技术学院,通用人工智能国家重点实验室)
- 通讯作者:Tianshu Qu(qutianshu@pku.edu.cn, 北京大学智能科学技术学院,通用人工智能国家重点实验室)
- 作者列表:Yufan Qian(北京大学智能科学技术学院,通用人工智能国家重点实验室)、Xihong Wu(北京大学智能科学技术学院,通用人工智能国家重点实验室)、Tianshu Qu(北京大学智能科学技术学院,通用人工智能国家重点实验室)
💡 毒舌点评
亮点:论文巧妙地将“平面波分解”这一物理概念转化为一个可微的深度学习损失函数,用于约束声场的空间结构,并通过“多位置联合优化”策略显著扩展了有效的听音区域,实验结果扎实,图表(如图3、图6)直观有力。 短板:方法依赖于特定且昂贵的球形麦克风阵列(SMA)来获取空间信息,限制了其实用性和普适性;论文虽然声称是“learning-based”,但核心优化过程(深度优化)更像是用神经网络作为参数化求解器,并未充分利用数据驱动的端到端学习优势。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:未提及公开。论文中使用的RIR数据是在特定汽车座舱内采集的,未说明是否共享。
- Demo:未提及在线演示。
- 复现材料:论文给出了方法的主要原理和实验设置描述,但缺少训练超参数(如学习率、优化器)、神经网络初始化细节、损失函数各项具体权重(λ_ϵ)等关键信息,完整复现存在困难。
- 论文中引用的开源项目:未提及依赖的特定开源工具或模型。
📌 核心摘要
- 问题:在汽车座舱内进行高质量的声场重放(SFR)非常困难,原因是复杂的声学反射、不规则的边界以及对扬声器布局的严格限制。传统方法(如波场合成、高阶Ambisonics)在理想条件下有效,但在车内环境中会产生音染和定位不准。
- 核心方法:提出一种基于深度优化的方法,核心在于将基于平面波分解(PWD)的、具有物理意义的空间功率图(SPM)作为约束,并结合多位置控制策略进行联合优化。
- 新意:与以往基于延迟求和波束成形(DSB)估计的伪谱不同,PWD提供了一个与测量阵列解耦的、物理上更精确的声场空间分布表示。多位置优化则将约束从单个点扩展到一个区域,以构建健壮的听音区。
- 主要结果:在真实汽车座舱内的实验表明,该方法在客观指标和主观听测中均显著优于多种基线方法(如频域去卷积、凸优化、SPMnet)。例如,在扩展区域的平均性能上,所提方法的频谱偏差(SD)为1.93 dB,后感知混响量化(nPRQpost)为0.31 dB,均优于基线;基于PWD的SPM相关性(Corr.)平均达到0.77,远高于其他方法。
- 实际意义:为在汽车等受限空间中实现高保真、高定位精度的沉浸式音频体验提供了有效的解决方案,推动了车载音响系统的发展。
- 主要局限性:性能验证依赖于特定尺寸和布置的球形麦克风阵列;目前只针对单个座椅位置进行了测试,尚未扩展到多座椅的全车覆盖。
🏗️ 模型架构
本文并非传统的神经网络架构,而是将神经网络作为优化器(深度优化)来求解控制滤波器。核心系统模型与数据流如下图所示:
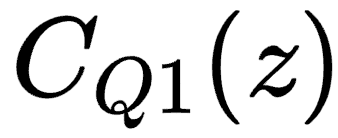 图1:声场重放系统示意图。展示了从虚拟源通过控制滤波器,经过声学信道(房间冲激响应),最终在麦克风处合成声场的信号流。
图1:声场重放系统示意图。展示了从虚拟源通过控制滤波器,经过声学信道(房间冲激响应),最终在麦克风处合成声场的信号流。
- 输入:多个虚拟声源的目标信号(或冲激响应)
d_s。 - 系统建模:整个系统被视为线性时不变(LTI)。每个虚拟源
s的全局控制滤波器向量为h_s,它通过系统矩阵C(编码了所有扬声器到所有麦克风的房间冲激响应c_ql)产生合成信号g_s。即g_s = C * h_s。 - 核心组件1:复合目标函数:定义了一个加权和损失
Δ,融合了时域、频域和空间域的约束,共同保证音质(如抑制振铃、避免音染)和空间定位准确性。 - 核心组件2:平面波分解(PWD)约束:这是关键的创新。利用球谐域波束成形器计算PWD权重
˜ω_b(f),进而从合成的频域信号˜g_s(f)估计出空间功率图Γ_rep。空间损失项就是Γ_rep与目标Γ_tar的均方误差。 - 核心组件3:多位置联合优化:为了将听音区从单点扩展到区域,对
K个不同位置(k=1,...,K)的声场分别应用PWD约束,并最小化所有位置损失之和L(θ)。神经网络(参数为θ)被用来直接生成整个控制滤波器h_s(θ),通过反向传播最小化L(θ)来训练网络。 - 输出:训练好的神经网络,其输出即为一个鲁棒的控制滤波器
h_opt_s,该滤波器能在目标区域内所有位置产生符合要求的声场。
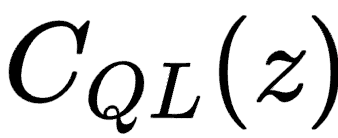 图2:实验用汽车座舱布置图。展示了11个扬声器(包括低音、中音、高音和环绕声道)和用于测量的球形麦克风阵列(SMA)的位置。
图2:实验用汽车座舱布置图。展示了11个扬声器(包括低音、中音、高音和环绕声道)和用于测量的球形麦克风阵列(SMA)的位置。
💡 核心创新点
- 基于平面波分解(PWD)的物理信息约束:之前工作(如SPMnet)使用延迟求和波束成形(DSB)估计的SPM是一个依赖阵列几何的“伪谱”。本文改用PWD,其输出的“平面波幅度密度”是声场本身的物理属性,与测量阵列解耦。这为神经网络提供了一个更精确、更稳定的优化目标。
- 收益:使优化能够直接控制声场的全局空间结构,而非离散测量点,避免了过拟合,提升了空间定位的物理准确性。
- 多位置联合优化策略:传统多点均衡方法在控制点外性能急剧下降。本文将多位置PWD约束联合到一个损失函数中,强制优化出一个在广泛区域内都能重建“远场平面波源”的滤波器。
- 收益:显著扩大了高音质、高定位精度的有效听音区域,如图3所示,所提方法在所有五个位置都保持了清晰的能量主对角线,而SPMnet仅在中心位置有效。
- 提出新的空间定位评估指标:论文提出使用多位置平均的PWD-SPM相关性(Corr.)作为评估空间定位准确性的客观指标。实验(图6)证明,该指标与主观听测结果高度一致,比传统基于中心位置的指标更能反映扩展区域内的真实性能。
- 收益:为车内声场重放等场景提供了一个更可靠、更具预测性的客观评估标准。
🔬 细节详述
- 训练数据:数据是实验中采集的房间冲激响应(RIR)。在汽车座舱内,使用指数正弦扫描信号测量了从11个扬声器到球形麦克风阵列16个单元的脉冲响应
c_ql(t)。训练数据即为这些RIR构成的系统矩阵C。数据规模未说明。 - 损失函数:
L(θ) = Σ_k Σ_ϵ λ_ϵ Δ_ϵ(g_s,k(θ), d_s)。- 时域约束:包括脉冲峰值约束和包络约束,用于抑制振铃伪影(nPRQ指标相关)。
- 频域约束:包括频谱平坦度约束和工作频率范围约束,用于避免音染并防止扬声器过载(SD指标相关)。
- 空间域约束:即PWD-SPM的均方误差(Corr.指标相关)。
- 各约束项的权重
λ_ϵ用于平衡。
- 训练策略:采用深度优化。神经网络(5层MLP)作为生成器,输入一个固定的随机向量,输出控制滤波器系数。通过最小化多位置联合损失
L(θ)来训练网络。优化器、学习率、批大小、训练轮数等细节未说明。 - 关键超参数:
- 神经网络结构:5层MLP。
- 输入/输出维度:输入层维度
L_h(滤波器长度),输出层维度L_h × L(所有扬声器的滤波器系数)。 - 多位置优化中的位置数
K:论文使用了LL, RR, O三个位置。 - 球形麦克风阵列:半径3cm,16个单元。
- 训练硬件:未说明。
- 推理细节:训练完成后,将生成的滤波器
h_s应用于系统。推理时即计算g_s = C * h_s,无需神经网络参与。 - 正则化技巧:通过多位置约束和损失函数中的各项约束隐式地实现了正则化,防止过拟合单个点。消融实验(表1中+PWD与Proposed对比)证实了多位置优化缓解了PWD单独使用时可能引入的过拟合倾向。
📊 实验结果
实验在真实的汽车座舱(图2)中进行,设置11个扬声器和1个16单元球形麦克风阵列。
主要基准对比:与未处理系统(Ori)及四种基线方法(频域去卷积FD、凸优化CVX、部分匹配投影解码PMPD、SPMnet)进行对比。
Table 1:客观评估结果(音质与空间定位)
| 方法 | 音质 (nPRQpre ↓) | 音质 (nPRQpost ↓) | 音质 (SD ↓) | 空间定位 (SPM Corr. ↑) |
|---|---|---|---|---|
| Pos O | Avg | Pos O | Avg | |
| Ori | 5.17 | 4.93±0.36 | 0.97 | 0.81±0.14 |
| FD | 5.36 | 6.34±0.76 | 2.35 | 2.80±0.39 |
| CVX | 2.12 | 2.65±0.38 | 0.84 | 1.08±0.19 |
| PMPD | 3.51 | 4.15±0.39 | 3.56 | 3.94±0.24 |
| SPMnet | 2.35 | 3.00±0.44 | 1.72 | 2.06±0.24 |
| +PWD | 2.23 | 2.89±0.43 | 1.58 | 1.97±0.31 |
| +MP | 0.84 | 0.80±0.21 | 0.44 | 0.37±0.11 |
| Proposed | 0.88 | 0.86±0.22 | 0.39 | 0.31±0.13 |
注:Pos O为中央位置,Avg为五个位置的平均。
- 关键发现:所提方法(Proposed)在扩展区域平均性能(Avg)上全面领先。特别是在空间定位指标Corr.上,Proposed(0.77)远高于次优的PMPD(0.54);在音质指标上也达到最优(SD: 1.93 dB, nPRQpost: 0.31 dB)。与基线SPMnet相比,Proposed在Avg Corr.上提升了约64%(从0.47到0.77)。
消融实验:基于SPMnet对比了PWD和多位置优化(MP)各自的贡献。
- +PWD:提升了音质(SD从2.58降至2.34),但Corr.反而下降(0.47->0.40),表明PWD单独使用可能过拟合。
- +MP:极大提升了性能的一致性(Avg Corr.接近Pos O Corr.),且Avg性能远超SPMnet。
- Proposed (PWD+MP):结合两者优势,达到最佳综合性能。
空间功率图可视化:
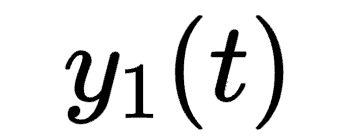 图3:不同方法在五个位置(LL, L, O, R, RR)的PWD估计空间功率图。
图3:不同方法在五个位置(LL, L, O, R, RR)的PWD估计空间功率图。
- 结论:所提方法在所有位置都呈现出清晰、明亮的主对角线,表示成功重建了水平面内的平面波声场。而SPMnet仅在中心位置(O)有较清晰的主对角线,在其他位置则模糊,说明其空间鲁棒性差。
空间定位相关性与角度关系:
 图6:(a) Pos O和(b) Avg位置的SPM相关系数随声源角度的变化。黑点标记在统计显著性检验中表现最佳的方法。
图6:(a) Pos O和(b) Avg位置的SPM相关系数随声源角度的变化。黑点标记在统计显著性检验中表现最佳的方法。
- 结论:平均相关系数(Avg Corr.)能更好地反映主观感受。SPMnet和+PWD在侧窗和后方头枕方向(30°-60°, 150°-210°)性能下降明显,而+MP和Proposed方法有效改善了这些区域的性能。
主观实验结果:
 图4:主观评估结果小提琴图。(a) 音质,(b) 空间定位。
图4:主观评估结果小提琴图。(a) 音质,(b) 空间定位。
- 结论:主观听测结果与客观指标一致。在音质和空间定位两项评分中,Proposed方法得分最高,其次是+MP,SPMnet和+PWD得分较低且相近,锚点(Anchor)得分最低。统计分析证实Proposed方法具有显著优势。
⚖️ 评分理由
- 学术质量:6.0/7。论文问题定义清晰,方法创新(PWD约束+多位置优化)有充分的技术合理性和物理动机。实验设计严谨,包含了客观测量、主观听测、多基线对比和消融研究,结果具有统计显��性,证据链完整。扣分点在于方法对专用硬件(SMA)的依赖,以及“深度优化”的训练细节(如学习率、优化器)缺失,部分降低了完全复现的可能性。
- 选题价值:1.5/2。汽车声场重放是空间音频领域一个具有挑战性且商业价值巨大的前沿方向。该研究直接针对产业痛点,提出的解决方案具有明确的应用前景和影响力,对相关领域的研究者也有启发。
- 开源与复现加成:0/1。论文未提及任何代码、模型、数据集的开源计划或获取方式,严重限制了方法的快速复现和后续研究跟进。