📄 A Generalization Strategy for Speech Quality Prediction: From Domain-Specific to Unified Datasets
#语音质量评估 #领域适应 #轻量化模型 #语音增强
✅ 6.5/10 | 前25% | #语音质量评估 | #领域适应 | #轻量化模型 #语音增强
学术质量 6.5/7 | 选题价值 1.5/2 | 复现加成 0.5 | 置信度 高
👥 作者与机构
- 第一作者:Imran E Kibria(俄亥俄州立大学计算机科学与工程系)
- 通讯作者:Donald S. Williamson(俄亥俄州立大学计算机科学与工程系)
- 作者列表:Imran E Kibria(俄亥俄州立大学计算机科学与工程系)、Ada Lamba(俄亥俄州立大学计算机科学与工程系)、Donald S. Williamson(俄亥俄州立大学计算机科学与工程系)
💡 毒舌点评
论文抓住了多数据集训练MOS模型时“顾此失彼”的真实痛点,并用一个优雅的优化器(SAM)作为解决方案,思路直接且实验验证充分。然而,整个工作像是用新扳手拧旧螺丝——核心模型和问题都不是新的,且实验对比缺乏与当前更强基线(如基于SSL的SOTA模型)的直接较量,使得结论的冲击力打了折扣。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:训练和测试数据集均为公开数据集,论文中列出了具体名称并说明可通过SHEET工具下载。
- Demo:未提及。
- 复现材料:提供了AttentiveMOS的原始论文引用以及本研究的关键超参数(η, ρ, batch size, epochs)。未提供详细的训练脚本或配置文件。
- 论文中引用的开源项目:
- SHEET [16]:用于下载和处理MOS数据集的工具包。
- AttentiveMOS [4]:本文实验所使用的基础模型。
- 其他:论文中未提及开源计划。
📌 核心摘要
- 要解决的问题:使用多个MOS(平均意见分)数据集统一训练语音质量评估模型时,由于数据集在录制条件、语言、畸变类型等方面存在巨大差异(即“域多样性”)以及“语料库效应”(相同质量系统因引入更优系统而得分下降),导致模型在未见的评测集上泛化性能严重下降。
- 方法核心:提出使用Sharpness-Aware Minimization(SAM)优化器来训练统一数据集上的MOS预测网络。SAM通过同时最小化损失和损失曲面的锐度(即寻找平坦的最小值),促使模型学习更多样化、互补的特征,从而提高对分布外数据的泛化能力。
- 与已有方法相比新在哪里:论文首次将SAM优化器系统地应用于解决多数据集MOS预测的泛化问题。与以往关注架构设计(如AlignNet)、损失函数改造(如Bias-aware loss)或使用大型预训练模型(如SSL)的方法不同,本文提出了一种无需修改模型架构或损失函数、只需更换优化器的轻量级泛化增强策略。
- 主要实验结果:在7个训练集和12个测试集的广泛评估中:
- 传统的Adam优化器在统一数据集上训练后,相比在单一最佳数据集上训练,在大多数测试集上性能下降显著(如表1所示)。
- 使用SAM+Adam优化器,在12个测试集中的8个上,降低了MSE并提升了SRCC(如图1、图2所示)。
- SAM显著缓解了从单一数据集到统一数据集训练的性能损失(即减小了∆MSE和∆SRCC,如图3所示),但在少数包含训练集中未出现语言(如德语、法语)的测试集上效果不佳。
测试集 Adam (Unified) MSE SAM+Adam (Unified) MSE Adam (Unified) SRCC SAM+Adam (Unified) SRCC BVCC 1.047 (图1显示更低) 0.642 (图2显示更高) SOMOS 0.837 (图1显示更低) 0.305 (图2显示更高) SingMOS 0.273 (图1显示更低) 0.068 (图2显示更高) (其他测试集类似) 注:表1提供了Adam优化器在单一最佳训练集和统一训练集下的具体数值。图1和图2则以柱状图形式对比了Adam与SAM+Adam在统一训练集设置下,各测试集的MSE和SRCC。
- 实际意义:为构建更鲁棒、通用的语音质量评估系统提供了一种简单有效的优化策略,尤其适用于资源有限、需要快速部署轻量级模型且数据来源多样的场景。
- 主要局限性:1) 验证使用的模型(AttentiveMOS)非常轻量级(仅86K参数),其结论能否推广到当前主流的、更强大的基于自监督学习(SSL)的大模型尚不明确。2) 实验未与近期针对MOS泛化提出的其他专用方法(如多数据集微调、对比回归等)进行直接性能对比。3) SAM需要额外的计算开销(每步更新需要两次前向/反向传播)。4) 对于训练集中完全缺失的语言或极端分布外数据,方法效果有限。
🏗️ 模型架构
论文中作为验证工具的模型是AttentiveMOS(引用自[4]),其本身不是本文的贡献。架构是一个轻量级的纯注意力网络:
- 输入:原始波形,重采样至16kHz,固定长度为20.48秒。
- 处理流程:
- 帧分割:波形被分割成小的、重叠的2毫秒帧。
- 嵌入生成:每个帧通过一个线性层生成嵌入向量。
- 局部特征提取:嵌入序列输入局部模块,该模块使用Swin Transformer从帧的小组中提取上下文特征,然后通过1D最大池化层减少帧数。
- 全局特征提取:精简后的上下文特征序列输入一系列全局模块,每个模块是一个标准Transformer,对所有嵌入进行注意力计算,以捕获话语级别的特征。
- 预测:一个浅层前馈网络将全局特征映射为一个标量MOS预测值。
- 关键设计选择:模型完全由注意力机制构成(无卷积),参数量极小(86K),便于从头快速训练,以确保评估SAM优化器效果时不受预训练SSL模型的影响。论文中未提供AttentiveMOS的架构图,因此无法用
描述]格式展示。
💡 核心创新点
- 将SAM优化器应用于MOS预测泛化问题:这是本文最核心的创新。首次将旨在寻找平坦极小值的SAM优化器引入多数据集统一训练的MOS预测任务,以对抗域偏移和语料库效应。之前的工作未探索过优化几何特性对MOS泛化能力的影响。
- 基于轻量级、从头训练模型的验证:选择AttentiveMOS这种轻量级、非SSL的模型进行验证,排除了预训练表征带来的混淆因素,使结论更清晰地归因于优化策略本身。这为未来在更复杂模型上应用SAM提供了基线参考。
- 系统性的泛化能力评估:实验设计具有说服力,使用了7个涵盖多种语言、失真类型的训练集进行统一训练,并在12个测试集(包括5个完全未见的“盲测”集)上评估,全面考察了方法在不同分布下的泛化性能。通过图3量化了SAM对统一训练性能损失的缓解程度。
🔬 细节详述
- 训练数据:
- 训练集(7个):BVCC, SOMOS, SingMOS, NISQA, TMHINT-QI, Tencent, PSTN。使用SHEET工具下载,遵循预定义划分。
- 测试集(12个):包括上述7个数据集的测试子集,以及5个完全未见的数据集(BC-19, VMC‘23 track-1a, track-1b, track-2, track-3)。
- 数据覆盖:涵盖合成语音(TTS, VC, SVS, SVC)、增强系统;畸变类型(人工/真实噪声、混响、VoIP、传输、回放);语言(英语、中文、日语、台湾普通话、德语、法语);采样率(8kHz-48kHz)。
- 预处理:所有音频重采样至16kHz,固定长度为20.48秒。
- 损失函数:标准的均方误差(MSE),即预测MOS值与真实MOS标签之间的平方损失。
- 训练策略:
- 优化器:对比了两个设置:1) Adam(基线);2) SAM + Adam(SAM负责计算“最坏情况”梯度,Adam负责实际权重更新)。
- 超参数:学习率 η = 5 × 10^-5,SAM邻域大小 ρ = 0.05。
- 批大小:8。
- 训练轮数:最多750个epoch,或早停(损失饱和时)。
- 调度策略:未说明是否使用学习率调度。
- 关键超参数:模型参数量:约86K(AttentiveMOS)。
- 训练硬件:论文中未说明。
- 推理细节:未提及特殊策略,直接使用训练好的模型进行前向传播得到预测MOS值。
- 正则化或稳定训练技巧:未说明是否使用Dropout、权重衰减等。SAM本身被认为具有提高泛化和鲁棒性的效果。
📊 实验结果
主要实验对比了在统一数据集训练下,Adam与SAM+Adam优化器的性能。
表1(论文中)关键数据转写:显示了使用Adam优化器时,AttentiveMOS在“最佳单一训练集”和“统一训练集”上在部分测试集的表现。清晰地展示了统一训练导致的性能下降(MSE升高,SRCC降低)。
| 测试集 | Best Single Train MSE | Best Single Train SRCC | Unified Train MSE | Unified Train SRCC |
|---|---|---|---|---|
| BVCC | 0.336 | 0.717 | 1.047 | 0.642 |
| SOMOS | 0.070 | 0.708 | 0.837 | 0.305 |
| SingMOS | 0.153 | 0.566 | 0.273 | 0.068 |
| BC-19 (盲测) | 0.761 | 0.500 | 1.036 | 0.260 |
| VMC‘23-1a (盲测) | 0.446 | 0.377 | 1.219 | 0.078 |
| VMC‘23-1b (盲测) | 0.534 | 0.387 | 1.221 | 0.034 |
| (其他测试集数据类似) |
图1(MSE对比) 与 图2(SRCC对比) 分析:
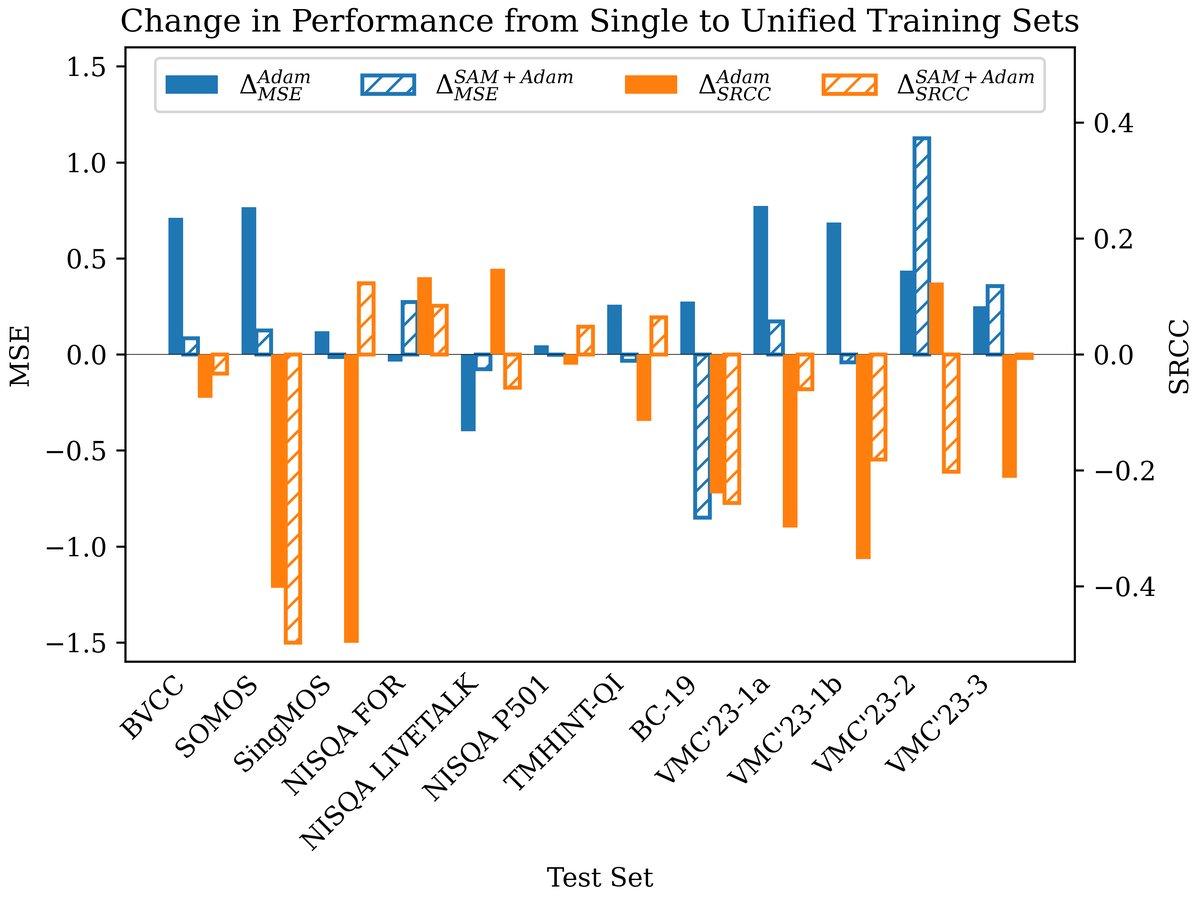 图1:MSE对比。在12个测试集中,有8个(BVCC, SOMOS, SingMOS, TMHINT-QI, BC-19, VMC‘23-2, VMC‘23-3, P501)的MSE在使用SAM+Adam后显著低于单独使用Adam。这直观地证明了SAM减少了预测误差。
图1:MSE对比。在12个测试集中,有8个(BVCC, SOMOS, SingMOS, TMHINT-QI, BC-19, VMC‘23-2, VMC‘23-3, P501)的MSE在使用SAM+Adam后显著低于单独使用Adam。这直观地证明了SAM减少了预测误差。
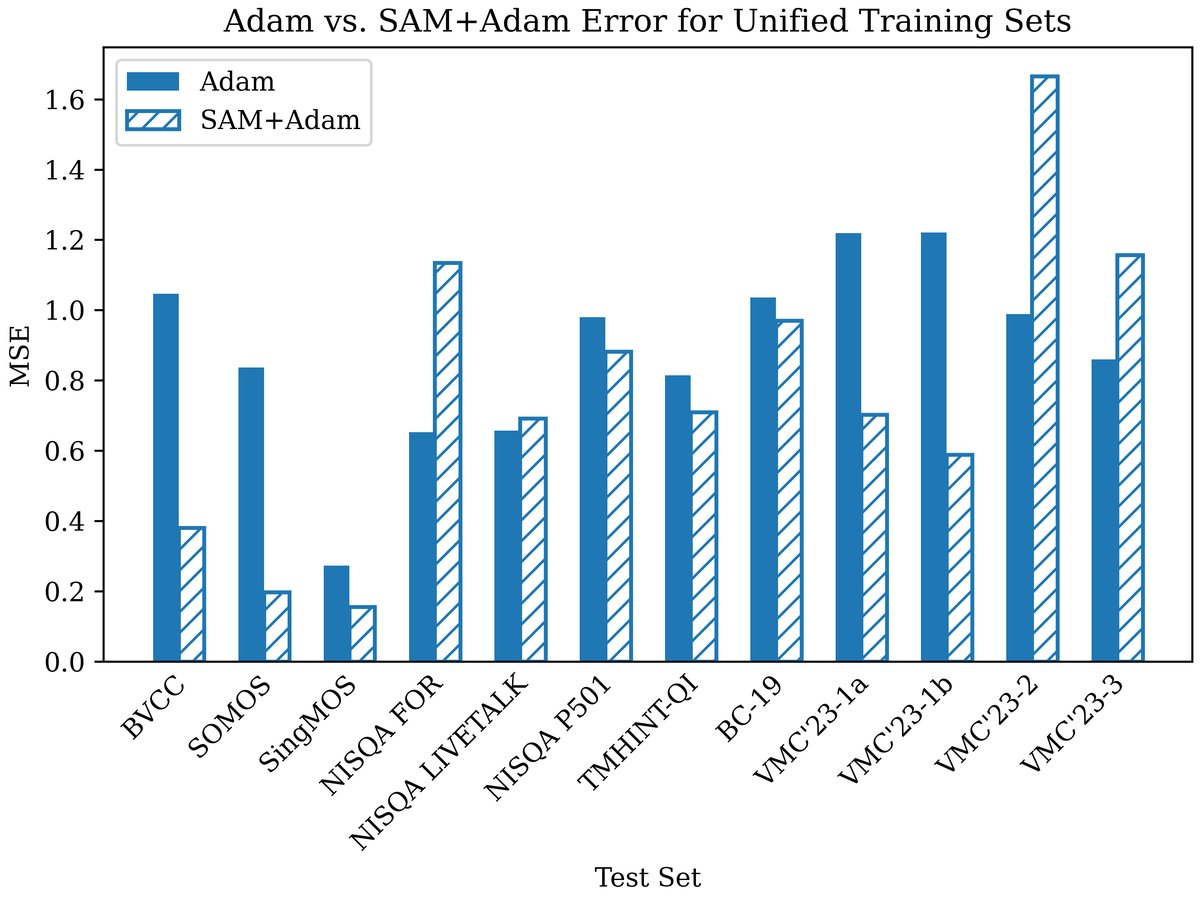 图2:SRCC对比。与MSE趋势一致,在同样的8个测试集上,SAM+Adam取得了更高的SRCC,表明模型排序与人类评价的一致性更好。例外情况(如NISQA FOR, LIVETALK, VMC‘23-1a, 1b)可能与语言差异有关。
图2:SRCC对比。与MSE趋势一致,在同样的8个测试集上,SAM+Adam取得了更高的SRCC,表明模型排序与人类评价的一致性更好。例外情况(如NISQA FOR, LIVETALK, VMC‘23-1a, 1b)可能与语言差异有关。
图3(性能损失缓解) 分析:
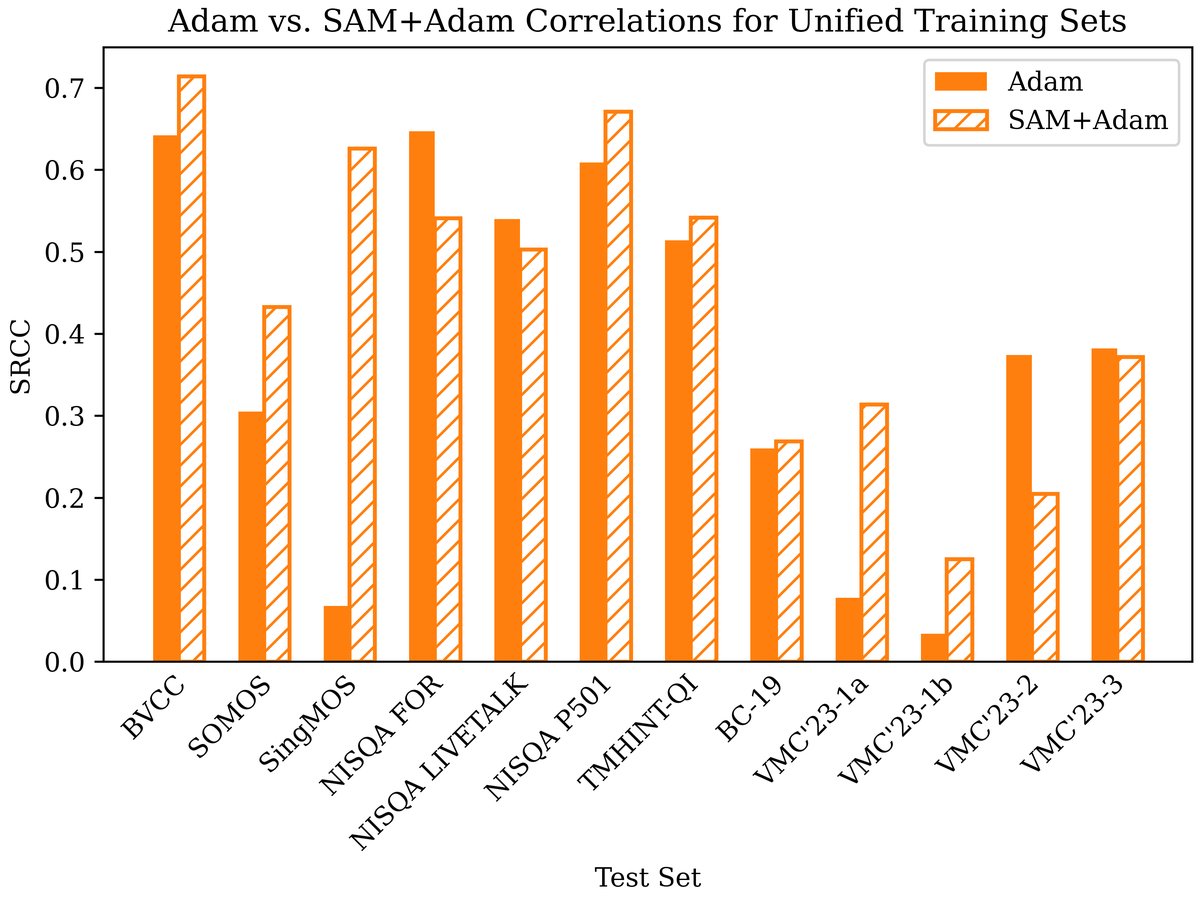 图3:从“最佳单一数据集”到“统一数据集”训练带来的性能变化(∆)。正向的∆MSE(柱子越高)和负向的∆SRCC(柱子越低)代表性能损失越大。图中显示,在8个测试集上,SAM+Adam(黄色/橙色柱)的∆值均小于或等于Adam(蓝色/红色柱),即SAM显著减轻了因引入多域数据导致的性能下降。例如,在SOMOS上,Adam的∆MSE高达约0.77,而SAM+Adam的∆MSE显著降低。
图3:从“最佳单一数据集”到“统一数据集”训练带来的性能变化(∆)。正向的∆MSE(柱子越高)和负向的∆SRCC(柱子越低)代表性能损失越大。图中显示,在8个测试集上,SAM+Adam(黄色/橙色柱)的∆值均小于或等于Adam(蓝色/红色柱),即SAM显著减轻了因引入多域数据导致的性能下降。例如,在SOMOS上,Adam的∆MSE高达约0.77,而SAM+Adam的∆MSE显著降低。
与最强基线对比:本文的主要基线是标准的Adam优化器。论文并未与近期提出的其他专门解决MOS泛化问题的方法(如AlignNet, Bias-aware loss, 对比回归等)或在更大规模的SSL模型上直接比较SRCC/MSE数值。 因此,无法判断该方法是否达到了当前SOTA水平。其实验结论是SAM在所述设置下优于Adam,且能缓解统一训练的负面影响。
关键消融实验:论文未提供传统意义上的消融实验(如改变ρ值、去掉SAM的某个步骤等)。其主要对比实验(单一数据集 vs. 统一数据集;Adam vs. SAM+Adam)本身具有消融性质,揭示了数据多样性和优化器选择对泛化性的影响。
⚖️ 评分理由
- 学术质量:6.5/7:论文逻辑清晰,实验设计系统且数据充足,结论有图表数据强力支撑。技术正确性高。创新点在于将现有优化器应用于一个具体但重要的问题,属于有效的工程改进和验证性研究,而非开创性的理论或架构创新。缺乏与SOTA方法的直接对比稍显不足。
- 选题价值:1.5/2:问题来自实际需求,解决MOS模型的跨域泛化对构建实用系统很重要。但验证模型过于简单轻量,使得结论的普适性和影响力有待在更强大、更接近实际应用的模型上验证。
- 开源与复现加成��0.5/1:论文提供了详细的实验设置(数据集来源、超参数),并引用了关键工具(SHEET)和基线模型(AttentiveMOS)。但未提供本研究产出的代码、模型权重或具体的训练脚本,复现需要读者自行整合信息并实现SAM与AttentiveMOS的结合。