📄 A Dynamic Gated Cross-Attention Framework for Audio-Text Apparent Personality Analysis
#多模态模型 #音频分类 #人格分析 #跨模态
✅ 7.0/10 | 前25% | #音频分类 | #多模态模型 | #人格分析 #跨模态
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Yunan Li(西安电子科技大学计算机科学与技术学院;西安大数据与智能视觉重点实验室;陕西省智能人机交互与可穿戴技术重点实验室)
- 通讯作者:Zixiang Lu(西安电子科技大学计算机科学与技术学院;西安大数据与智能视觉重点实验室;陕西省智能人机交互与可穿戴技术重点实验室)
- 作者列表:Yunan Li(同上)、Zixiang Lu(同上)、Yang Ma(西安电子科技大学计算机科学与技术学院)、Haozhe Bu(西安电子科技大学计算机科学与技术学院)、Zhuoqi Ma(西安电子科技大学计算机科学与技术学院;西安大数据与智能视觉重点实验室;陕西省智能人机交互与可穿戴技术重点实验室)、Qiguang Miao(西安电子科技大学计算机科学与技术学院;西安大数据与智能视觉重点实验室;陕西省智能人机交互与可穿戴技术重点实验室)
💡 毒舌点评
该论文提出了一种结构清晰的音频-文本双流融合框架,其动态门控机制为处理模态特异性与交互性提供了合理的解决方案。然而,其核心创新(交叉注意力+门控)在多模态融合领域已不算新奇,且实验仅限于一个数据集,缺乏跨数据集或跨任务的泛化验证,说服力有限。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用了公开的ChaLearn First Impressions V2数据集,但论文中未说明具体获取方式。
- Demo:未提及。
- 复现材料:仅提供了部分训练细节(优化器、学习率范围、损失函数类型)和硬件信息,但缺乏完整的超参数配置、数据预处理脚本、训练日志等,复现难度较大。
- 论文中引用的开源项目:提到了Adam优化器[18],以及参考了损失函数设计[7],但未明确列出依赖的开源代码库或预训练模型(如RoBERTa的具体版本)。
- 总体:论文中未提及开源计划。
📌 核心摘要
- 要解决什么问题:针对从音频和文本中推断人格特质的表观人格分析(APA)任务,现有方法在融合异质模态时存在语义对齐不足和动态贡献调节困难的问题。
- 方法核心是什么:提出一个基于动态门控交叉注意力(DGCA)的框架。首先使用注意力增强的ResNet(AttResNet)和RoBERTa分别编码音频和文本;然后通过双向交叉注意力机制(BCAM)建模细粒度交互;最后引入动态门控模块(GMM)和单模态保留门,自适应地平衡模态贡献并保留特异性信息。
- 与已有方法相比新在哪里:与简单的拼接或加权融合不同,该方法设计了双向交叉注意力以对称捕捉跨模态依赖,并创新性地集成了两组门控机制:一组(GMM)用于抑制跨模态对齐中的噪声,另一组(单模态保留门)用于显式保留原始模态特征,防止信息在融合中丢失。
- 主要实验结果如何:在ChaLearn First Impressions V2数据集上,该方法在大五人格特质预测的平均分上达到0.9010,优于文中对比的所有基线方法(如Sun et al. 0.8966, Li et al. 0.8967, Zhu et al. 0.8984)。消融实验证明,AttResNet比基础ResNet性能更优,BCAM和GMM的引入共同带来了性能提升(从0.8906提升至0.9010)。具体结果见下表。
表1:与现有方法的性能对比(ChaLearn First Impressions V2)
| 方法 | EXT | NEU | AGR | CON | OPN | 平均 |
|---|---|---|---|---|---|---|
| Sun et al. [8] | 0.8954 | 0.8960 | 0.9015 | 0.8894 | 0.9008 | 0.8966 |
| Li et al. [7] | 0.8953 | 0.8951 | 0.9010 | 0.8920 | 0.9002 | 0.8967 |
| Zhu et al. [11] | 0.8933 | 0.9066 | 0.8939 | 0.8946 | 0.8928 | 0.8984 |
| Ours | 0.8987 | 0.8999 | 0.9039 | 0.8997 | 0.9030 | 0.9010 |
表2:不同音频编码模块的消融实验
| 模态 | EXT | NEU | AGR | CON | OPN | 平均 |
|---|---|---|---|---|---|---|
| ResNet | 0.8942 | 0.8942 | 0.9005 | 0.8912 | 0.8996 | 0.8959 |
| AttResNet | 0.8972 | 0.8983 | 0.9007 | 0.8990 | 0.9007 | 0.8997 |
表3:BCAM和GMM模块的消融实验
| BCAM | GMM | EXT | NEU | AGR | CON | OPN | 平均 |
|---|---|---|---|---|---|---|---|
| × | × | 0.8897 | 0.8908 | 0.8940 | 0.8865 | 0.8923 | 0.8906 |
| ✓ | × | 0.8955 | 0.8965 | 0.8992 | 0.8977 | 0.9000 | 0.8979 |
| ✓ | ✓ | 0.8987 | 0.8999 | 0.9039 | 0.8997 | 0.9030 | 0.9010 |
- 实际意义是什么:该研究为基于语音和文本的人格分析提供了一个有效的多模态融合框架,对于人机交互、个性化服务等场景有潜在应用价值,尤其是在视频数据不可用的隐私敏感场景下。
- 主要局限性是什么:实验仅在一个公开数据集(ChaLearn V2)上进行验证,缺乏在更多样化数据集或真实场景下的泛化能力评估;论文未讨论模型的可解释性细节;未提供代码和模型权重。
🏗️ 模型架构
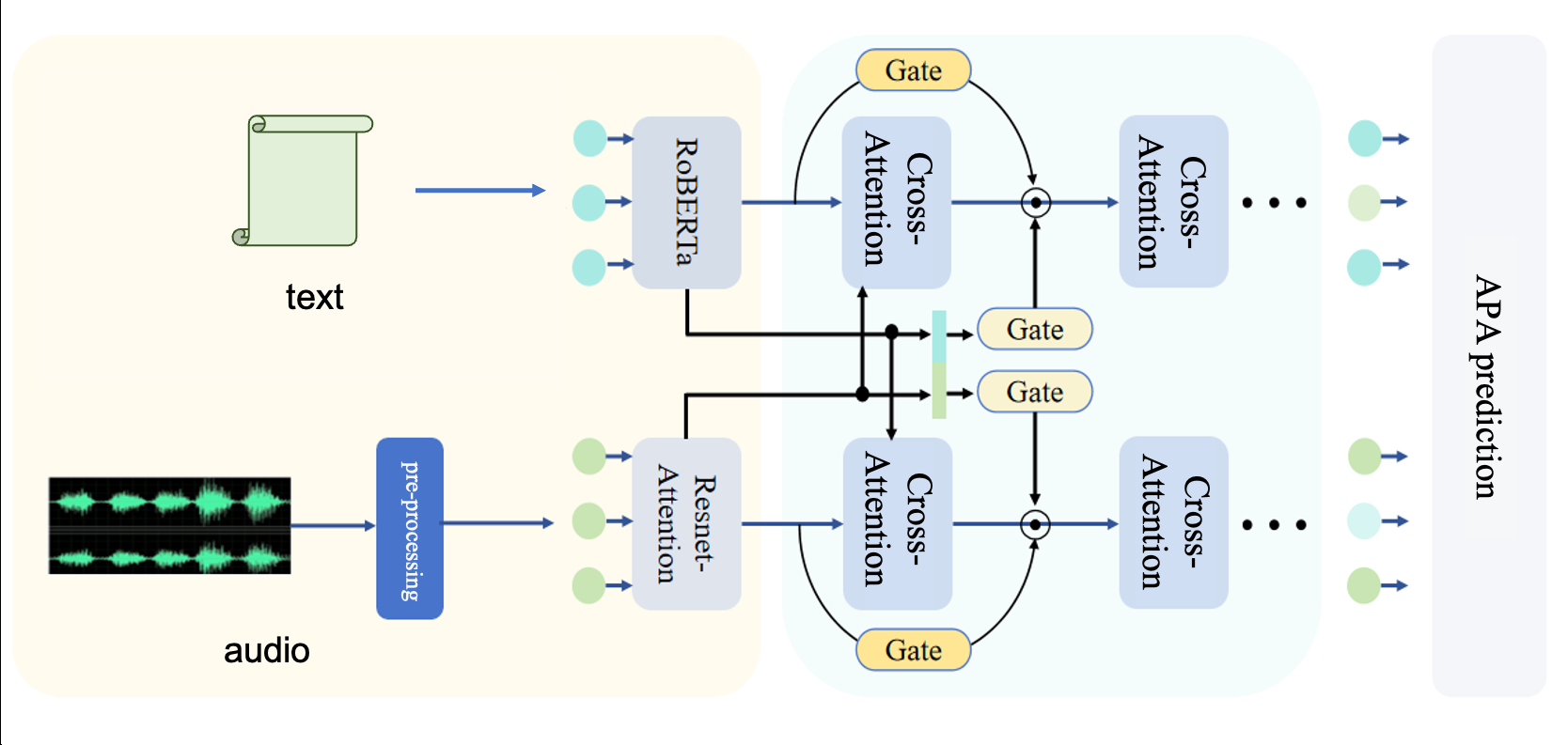 该模型是一个端到端的双流多模态融合框架,主要包含三个部分:音频编码器、文本编码器和动态门控交叉注意力融合模块。
该模型是一个端到端的双流多模态融合框架,主要包含三个部分:音频编码器、文本编码器和动态门控交叉注意力融合模块。
- 输入:原始音频波形(s ∈ ℝᴺ)和对应的文本(T)。
- 音频编码路径:
- 波形经过幅值归一化和拼接平铺(tiling)策略处理成固定长度。
- 进行短时傅里叶变换(STFT)和梅尔滤波器组,得到梅尔频谱图(Maudio ∈ ℝᶠˣᵀ)。
- 输入到AttResNet编码器(图中右侧分支)。AttResNet结合了ResNet块和轻量级自注意力机制。自注意力分支计算一个时间重要性权重(w ∈ ℝ¹ˣᵀ),用于突出显著帧。
- 对AttResNet输出(H ∈ ℝᶜˣᵀ)进行基于注意力权重的统计池化(计算加权均值μ和标准差σ),得到最终的音频嵌入(z ∈ ℝ²ᶜ)。这种方法能捕捉韵律的中心趋势和变异性。
- 文本编码路径:
- 文本(T)直接输入到RoBERTa模型(图中左侧分支),利用其在大规模预训练中学到的深层语义编码能力,输出文本表示(Htext)。
- 动态门控交叉注意力融合模块(DGCA):
- 接收音频嵌入(A,即z)和文本嵌入(T,即Htext)。
- 双向交叉注意力机制(BCAM):包含两个并行的多头注意力子模块。
- A2T分支:音频特征作为查询(Q_A),文本特征作为键和值(K_T, V_T),计算注意力输出(O_A2T)。这使音频能够“关注”相关文本信息。
- T2A分支:文本特征作为查询(Q_T),音频特征作为键和值(K_A, V_A),计算注意力输出(O_T2A)。这使文本能够“关注”相关音频信息。
- 这种双向设计确保了模态间的对称信息流动。
- 动态门控机制(GMM):
- 跨模态调制门:将A和T拼接后通过全连接层和Sigmoid激活,生成门控向量(G_c1, G_c2)。这两个门控向量分别对BCAM的输出(O_A2T, O_T2A)进行逐元素调制,得到O’_A2T和O’_T2A。这用于抑制跨模态对齐中的噪声并平衡交互。
- 单模态保留门:分别对原始的音频特征(A)和文本特征(T)应用独立的门控(G_r1, G_r2),得到A’和T’。这确保了模态的特异性信息(如音频的韵律节奏、文本的句法结构)在融合后得以保留,不被完全淹没。
- 最终融合表示:将调制后的跨模态交互特征(O’_A2T, O’_T2A)与保留的单模态特征(A’, T’)拼接,形成最终的多模态表示。
- 输出:通过一个回归头(未详细说明结构)从最终融合表示中预测大五人格特质分数(EXT, NEU, AGR, CON, OPN)。
💡 核心创新点
- 注意力增强的音频编码器(AttResNet):在标准ResNet中集成了轻量级自注意力分支,用于自适应地强调音频信号中具有区分性的时间帧(如关键副语言线索),同时抑制无关噪声帧,从而学习到更鲁棒的音频表示。实验证明其优于基础ResNet。
- 双向交叉注意力机制(BCAM):设计了对称的A2T和T2A两个注意力路径,允许音频和文本模态相互“关注”并提取对对方有用的信息,克服了单向交叉注意力的局限性,实现了更深层次的跨模态语义对齐。
- 动态门控模块(GMM)与单模态保留门:提出了一个包含两组门控的融合策略。跨模态调制门根据输入的联合表示动态调节交叉注意力的输出,过滤噪声对齐。单模态保留门则独立地对原始模态特征进行加权,显式地保留各模态自身的特异性信息。这共同解决了融合过程中信息冗余和模态特征退化的问题。
🔬 细节详述
- 训练数据:ChaLearn First Impressions V2数据集(论文中提及)。
- 损失函数:论文提及使用了MSE、MAE和Bell loss(参考[7])。未说明各损失的权重或具体结合方式。
- 训练策略:使用PyTorch实现,在NVIDIA RTX 4090 GPU上训练。使用Adam优化器。学习率在10⁻³到10⁻⁶之间衰减(具体策略未说明)。
- 关键超参数:未说明模型的具体大小(如ResNet层数、RoBERTa版本、注意力头数、隐藏维度等)。
- 训练硬件:NVIDIA RTX 4090 GPU(仅提到单卡)。
- 推理细节:未说明推理时的具体解码策略或批处理设置。
- 正则化或稳定训练技巧:未提及Dropout、权重衰减等具体技巧。音频预处理中使用了幅值归一化和平铺策略。
📊 实验结果
论文主要报告了在ChaLearn First Impressions V2数据集上的大五人格特质预测任务结果,评估指标为皮尔逊相关系数(根据表格数值推断)。主要对比结果和消融实验见“核心摘要”中的表格。
- 与SOTA对比:本文方法(平均0.9010)在平均分上超越了所有列出的、同样使用音频和文本模态的基线方法,最高提升0.0044(对比Sun et al.)。论文声称达到了“state-of-the-art”性能。
- 关键消融实验:
- 编码器效果(表2):AttResNet(平均0.8997)相比普通ResNet(平均0.8959)在所有特质上均有提升,证明了注意力机制的有效性。
- 融合模块效果(表3):
- 仅使用简单拼接(无BCAM和GMM)性能最差(平均0.8906)。
- 加入BCAM后性能显著提升(平均0.8979),表明建模跨模态交互至关重要。
- 同时加入BCAM和GMM达到最佳性能(平均0.9010),证明了动态门控机制在优化融合过程中的额外贡献。
⚖️ 评分理由
- 学术质量:5.5/7:论文技术路线清晰,针对具体问题(多模态对齐和动态融合)提出了合理的模块设计(AttResNet, BCAM, GMM),并通过充分的消融实验验证了各组件的有效性。创新性属于渐进式改进,而非范式突破。实验仅在单一数据集上进行,缺乏更广泛的验证,结论的普适性有待考察。
- 选题价值:1.5/2:音频-文本人格分析是一个有实际意义的多模态理解课题,尤其在隐私保护场景下有应用潜力。但该任务相对垂直,受众和影响范围可能有限。
- 开源与复现加成:0.0/1:论文中未提及代码、预训练模型权重、详细的训练配置(如确切的学习率调度、批大小)的开源计划,复现依赖度高,因此给予0分。