📄 A Dataset of Robot-Patient and Doctor-Patient Medical Dialogues for Spoken Language Processing Tasks
#语音对话系统 #数据集 #大语言模型 #模型评估 #语音识别
✅ 7.5/10 | 前25% | #语音对话系统 | #数据集 | #大语言模型 #模型评估
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 1.0 | 置信度 高
👥 作者与机构
- 第一作者:Heriberto Cuayáhuitl(University of Lincoln, School of Engineering and Physical Sciences)
- 通讯作者:未说明(论文中未明确指定通讯作者)
- 作者列表:
- Heriberto Cuayáhuitl(University of Lincoln, School of Engineering and Physical Sciences)
- Grace Jang(Lincoln Medical School, Universities of Lincoln and Nottingham)
💡 毒舌点评
亮点:数据集规模(111+小时)和收集方法(结合远程操控机器人与真实医患对话)在公开免费资源中独树一帜,并创新性地设计了模拟ASR噪声的评估协议。短板:对LLM的评估停留在通用多选题任务上,未能深入设计更能体现医疗对话复杂性和安全性的评测,使得这项重要的数据资源在论文中的价值释放略显不足,更像一个“半成品”基准。
🔗 开源详情
- 代码:论文中未提及代码链接。提到将提供用于回放对话的独立应用程序(本地Web服务器,基于.NET和Node.js),但未说明是否开源。
- 模型权重:未提及。论文评估的是闭源的商业或前沿LLM(GPT-5 mini, DeepSeek V3, Claude Sonnet 4)。
- 数据集:公开,免费获取(限非商业用途)。论文声明“The dataset is free of charge for non-commercial purposes.”并提供了详细的统计信息。
- Demo:提供了一个YouTube视频链接展示对话回放示例,并说明提供了一个独立的医疗问诊回放应用程序。
- 复现材料:提供了数据收集系统的详细技术描述、标注格式、基准测试的完整设置(提示词模板、选项构成、评估指标)以及详细的实验结果表格,复现评估实验的材料充分。
- 论文中引用的开源项目:
- 语音识别:Vosk (模型:vosk-model-en-us-0.22),Faster-Whisper (用于生成ASR噪声)。
- 文本处理:FastPunct (自动标点)。
- 语音合成:Acapela TTS。
- 机器人平台:Pepper机器人。
- 录音工具:MS Teams (用于人人对话),Audacity (用于标注)。
- 评估模型:引用了GPT-5 mini、DeepSeek V3、Claude Sonnet 4。
📌 核心摘要
- 问题:尽管大语言模型(LLM)发展迅速,但其在文本或语音形式的医疗问诊中应用仍是一个开放问题,主要瓶颈之一是缺乏大规模、公开、包含人机交互的医疗对话语音数据集。
- 方法核心:提出MeDial-Speech数据集,通过创新的Wizard-of-Oz系统,收集了111+小时的机器人-患者和医生-患者对话语音数据,覆盖四种常见疾病。并设计了基于句子选择(20选1)的对话基准测试,评估了多个前沿LLM在有无ASR噪声下的表现。
- 创新点:1) 数据集规模大、模态丰富(语音、转录、说话人标签),且免费开放;2) 同时包含人机和人人对话,更贴近未来应用场景;3) 基准测试引入ASR噪声,模拟真实世界中患者语音识别不准的情况。
- 实验结果:在句子选择任务中,Claude Sonnet 4表现最佳,手动转录下平衡准确率为71.1%,自动转录下为74.7%。关键发现是所有被评估的LLM(GPT-5 mini, DeepSeek-V3, Claude Sonnet 4)都表现出强烈的过度自信,即无论预测正确与否,其给出的概率分布都高度集中。
- 关键实验结果表格如下:
指标 无噪声(手动转录) 有噪声(ASR转录) 模型 GPT-5 mini DeepSeek V3 平衡准确率↑ 0.4919 0.6271 F1分数↑ 0.6591 0.7708 Brier分数↓ 0.2754 0.2421 校准损失↓ 0.1119 0.1321
- 关键实验结果表格如下:
- 实际意义:为医疗AI的训练和评估提供了宝贵的开放资源,有望加速语音对话系统、自动化临床辅助等应用的发展,并为医学生提供教学工具。
- 主要局限性:1) 参与者为模拟患者而非真实患者,可能影响对话的临床真实性;2) 论文提出的基准任务相对简单,未深入探索对话生成、临床推理等更复杂任务;3) 对揭示的LLM“过度自信”问题,未能提出有效的解决方案。
🏗️ 模型架构
本文的核心贡献并非提出一个新的神经网络模型,而是提出一个数据收集与评估系统。其系统架构如下图所示:
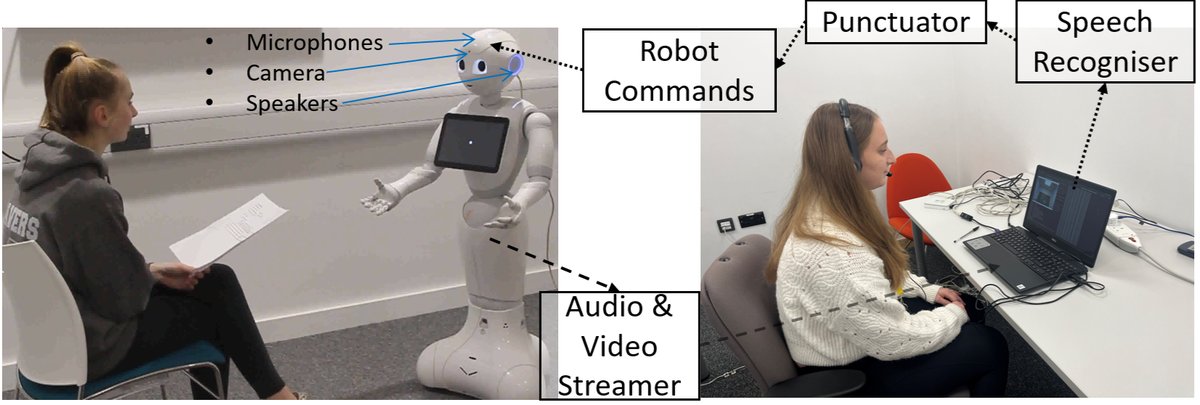 系统工作流程详解:
系统工作流程详解:
- 核心设置:采用Wizard-of-Oz方法。人类医生作为“遥操作者”,在独立房间通过耳机和笔记本电脑(接收患者视频与转录文本)与Pepper机器人交互。
- 人机交互流程:
- 输入(医生->机器人):医生说话 → 使用Vosk ASR系统实时转录为文本 → 通过FastPunct自动加标点 → 由Acapela TTS合成语音 → 机器人同时输出语音和预录手势动作(如点头、挥手)。
- 输出(患者->机器人):患者对着机器人说话 → 机器人麦克风持续录制患者语音和视频 → 数据流近实时传输给医生的笔记本电脑。
- 关键技术点:系统刻意避免了GUI预设选项,鼓励医生进行个性化、类人的自然语言交流。ASR模型为
vosk-model-en-us-0.22。 - 人人对话:医生-患者对话通过MS Teams录制。
- 数据处理:最终数据被分割为每轮对话的独立音频文件,并提供了包含时间戳和说话人标签(医生、机器人、患者)的转录文本(
.txt)及Audacity工程文件(.aup3)。
💡 核心创新点
- 首个大规模、免费的混合式医疗对话语音数据集:数据集包含111+小时、581个对话,融合了机器人-患者(使用TTS)和医生-患者(自然语音)两种模态,这在现有公开数据集中是独特的。
- 创新的数据收集协议:利用Wizard-of-Oz和远程操控机器人,模拟了未来人机医疗咨询的场景,同时保证了数据收集的可控性和伦理合规性。
- 引入噪声鲁棒性评估:在基准测试中,刻意将ASR生成的带噪转录用于患者话语,以模拟真实世界中语音识别的不确定性,评估LLM在这种不完美输入下的表现。
- 对LLM过度自信的实证分析:通过高斯分布图和重叠系数,直观且定量地证明了当前顶尖LLM在医疗句子选择任务中存在严重的概率校准问题,无论对错都表现出高置信度。
🔬 细节详述
- 训练数据:即MeDial-Speech数据集本身。包含325名未付费参与者(主要为大学生,年龄18-24岁占87.1%),模拟四种病情(路易体痴呆、心力衰竭、肩痛、心绞痛)。数据集总大小12.6GB,包含26.4万词,6100个独立词汇。
- 损失函数:未说明(论文未训练自有模型)。
- 训练策略:未说明(论文未训练自有模型)。
- 关键超参数:未说明。
- 训练硬件:未说明。
- 推理细节:
- 评估任务:句子选择,给定对话上下文(5-20轮),从20个选项中选出最合理的下一句医生回复。
- 提示模板:论文提供了评估所用的标准提示词,要求LLM“提供一个概率分布,一行内包含选项和概率,无其他内容”。
- ASR转录:用于产生“有噪声”评估集,使用了Faster-Whisper模型。
- 正则化或稳定训练技巧:不适用。
📊 实验结果
论文主要评估了三个LLM在句子选择任务上的性能。关键结果表格(Table 2) 已在“核心摘要”部分完整列出。核心结论如下:
- 模型性能排名:在所有分类和概率校准指标上,Claude Sonnet 4均显著优于DeepSeek V3和GPT-5 mini。例如,在无噪声条件下,其平衡准确率(0.7119)比第二名DeepSeek V3(0.6271)高出8.48个百分点。
- 噪声鲁棒性:引入ASR噪声后,Claude Sonnet 4的性能甚至略有提升(平衡准确率从0.7119到0.7473),而DeepSeek V3性能显著下降(从0.6271到0.5598),表明不同模型对噪声的敏感度不同。
- 校准问题:这是论文最重要的发现之一。下图展示了模型预测概率的分布。
- 图2:高斯分布图
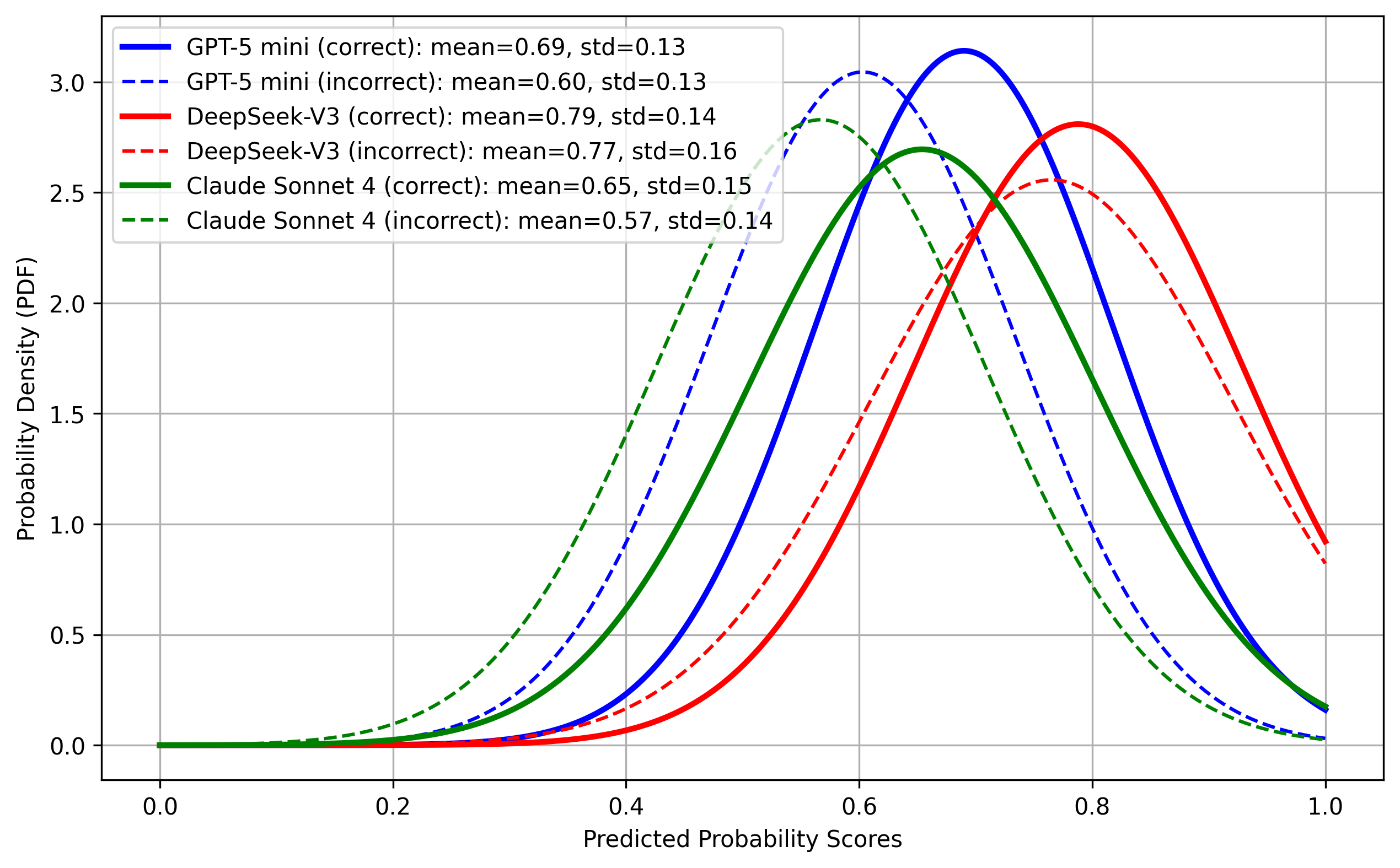 说明:直线代表正确预测的置信度分布,虚线代表错误预测的置信度分布。理想模型应使直线靠右(高置信),虚线靠左(低置信)。但图中所有模型的两曲线高度重叠,计算出的重叠系数(OVL)均超过0.7,表明模型无论对错都给出相似的高概率。
说明:直线代表正确预测的置信度分布,虚线代表错误预测的置信度分布。理想模型应使直线靠右(高置信),虚线靠左(低置信)。但图中所有模型的两曲线高度重叠,计算出的重叠系数(OVL)均超过0.7,表明模型无论对错都给出相似的高概率。 - 图3:可靠性图
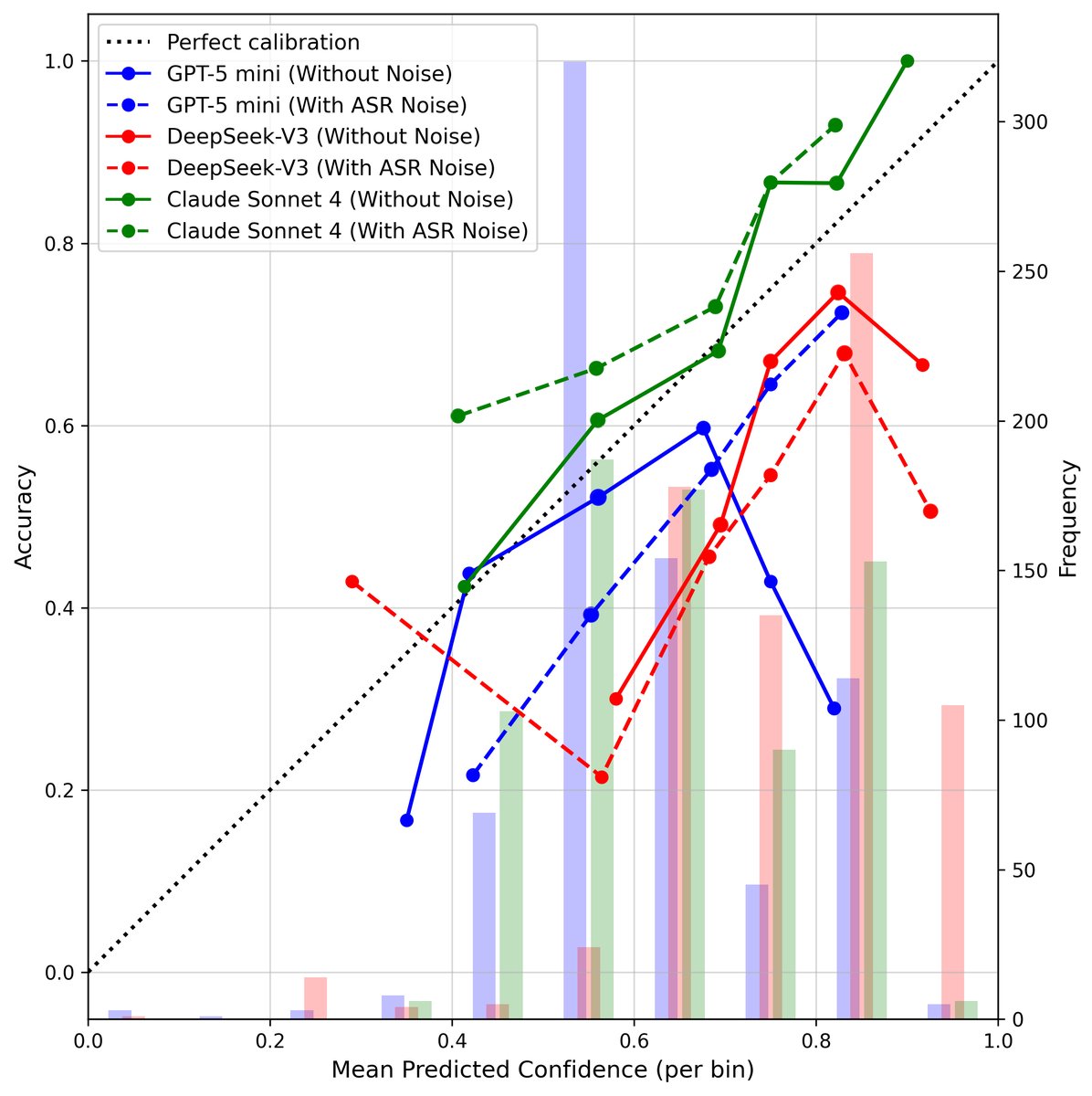 说明:理想模型的点应落在对角线上(预测概率=实际频率)。图中点明显偏离对角线,尤其是在高概率区域,模型实际正确率远低于其预测概率,证实了过度自信。
说明:理想模型的点应落在对角线上(预测概率=实际频率)。图中点明显偏离对角线,尤其是在高概率区域,模型实际正确率远低于其预测概率,证实了过度自信。
- 图2:高斯分布图
- 统计显著性:作者使用符号检验、Wilcoxon符号秩检验和T检验,确认了Claude Sonnet 4与DeepSeek V3的性能差异显著(p < .05)。
⚖️ 评分理由
- 学术质量:5.5/7:数据集构建工作扎实、系统,设计合理,并包含了一个有价值的基准测试。实验部分评估了多个模型并得出了有洞察力的发现(过度自信)。但创新主要体现在“资源整合与评估设计”上,而非底层方法或模型的突破。评估任务(多选一)相对简单,对数据集潜力的挖掘不够深入。
- 选题价值:1.5/2:医疗对话数据集是当前AI交叉领域的稀缺资源,对语音处理、对话系统、医疗AI等多个方向的研究者有直接价值。题目前沿且实用性强。扣分点在于数据为模拟患者,临床外推性需谨慎看待。
- 开源与复现加成:1.0/1:论文明确承诺数据集免费开放,并提供了详细的统计、格式和回放工具说明。基准测试的评估提示词也计划公开,复现门槛低。但未提及开源数据处理代码或更复杂的分析脚本。