📄 A Data-Driven Framework for Personal Sound Zone Control Addressing Loudspeaker Nonlinearities
#空间音频 #信号处理 #麦克风阵列 #深度学习
✅ 7.5/10 | 前25% | #空间音频 | #信号处理 | #麦克风阵列 #深度学习
学术质量 7.0/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 高
👥 作者与机构
- 第一作者:Lei Zhou (重庆邮电大学通信与信息工程学院)
- 通讯作者:Liming Shi (重庆邮电大学通信与信息工程学院)
- 作者列表:Lei Zhou(重庆邮电大学通信与信息工程学院),Chen Gong(重庆邮电大学通信与信息工程学院),Chen Huang(重庆邮电大学通信与信息工程学院),Hongqing Liu(重庆邮电大学通信与信息工程学院),Lu Gan(Brunel University伦敦校区工程、设计与物理科学学院),Liming Shi(重庆邮电大学通信与信息工程学院)
💡 毒舌点评
亮点:论文针对一个实际且被长期忽略的问题(小型扬声器的非线性破坏了传统线性控制理论),提出了一个“用魔法打败魔法”的优雅框架——先用深度学习精确建模非线性,再用这个模型去训练一个能补偿非线性的控制器,逻辑闭环非常漂亮。
短板:虽然物理实验验证了有效性,但核心控制器(如WaveNet+VNN)的计算开销巨大(MACs达33G),对于论文标题中暗示的“移动和边缘设备”场景,其落地可行性存疑,更像一个原理验证原型。
标题:A Data-Driven Framework for Personal Sound Zone Control Addressing Loudspeaker Nonlinearities
摘要:论文针对个人声区控制系统性能受小型扬声器非线性严重制约的问题,提出一个两阶段、数据驱动的框架。第一阶段,训练一个高保真非线性前向模型以精确捕获从数字输入到声压的真实声学过程。第二阶段,将该预训练模型作为可微模拟器,优化一个控制网络。该框架为传统线性方法提供了一个统一视角,同时实现了更强的端到端非线性控制。在物理微型扬声器阵列上的实验表明,性能最佳的非线性控制器相比基线方法,在语音信号(200–4000 Hz)上实现了平均5.33 dB的声对比度(AC)提升。
🔗 开源详情
- 代码:论文中未提及代码仓库链接。
- 模型权重:论文中未提及公开模型权重。
- 数据集:使用了公开的THCHS-30数据集,但论文本身未提及是否公开其处理后的增强数据集及录制的原始音频数据。
- Demo:论文中未提及提供在线演示。
- 复现材料:论文给出了部分架构细节和关键超参数(如WaveNet块数、膨胀率、网络结构选择),但缺少完整的训练设置(优化器、学习率、batch size、迭代次数等)、硬件环境以及预训练模型,复现难度较大。
- 引用的开源项目:引用了WaveNet [26]的原始论文,但未明确说明是否使用了开源实现。
📌 核心摘要
- 要解决什么问题:传统个人声区控制方法基于线性声学传递函数假设,但消费电子中常用的小型扬声器存在显著的非线性失真。这导致两个核心失败点:(E1) 线性系统辨识获得的声学传递函数被扭曲;(E2) 线性叠加原理在控制设计中失效,从而严重限制系统性能。
- 方法核心是什么:提出一个两阶段数据驱动框架(图1)。第一阶段(系统辨识):训练一个基于WaveNet的非线性前向模型,以学习从驱动信号到麦克风声压的端到端映射。第二阶段(控制器设计):将冻结的前向模型作为可微模拟器,在其构建的声学场中直接优化控制网络(可以是线性FIR、PNN、VNN或WaveNet等),以最大化目标声对比度。
- 与已有方法相比新在哪里:
- 范式转变:从“先辨识线性模型,再优化线性控制器”的分离式设计,转向“先学习高保真非线性模型,再端到端优化非线性控制器”的数据驱动范式。
- 统一视角:证明传统线性控制器是该框架的一个特例(线性控制网络+线性ATF前向模型)。即使使用线性控制器,针对非线性前向模型进行优化也能提升性能。
- 差异化架构:根据物理布局(独立扬声器 vs 耦合腔扬声器)设计不同的控制网络(SISO与MIMO),显式建模耦合。
- 主要实验结果如何:在物理四通道微型扬声器阵列上进行实验,对比VAST基线方法(性能类似ACC)。关键结果见下表,最佳配置(Wavenet+VNN)实现了5.33 dB的AC提升。图3显示,性能提升主要集中在非线性失真显著的200-2000 Hz频段。
| 网络1 (扬声器1) | 网络2 (扬声器3,4) | 参数量(K) | 计算量(MACs) | ΔAC (dB) | 因果性 |
|---|---|---|---|---|---|
| Linear | Linear | 4.8 | 228M | 1.04 | ✓ |
| Linear | PNN | 7.6 | 307M | 3.62 | ✓ |
| Linear | VNN | 7.2 | 288M | 3.70 | ✓ |
| Linear | WaveNet | 379.6 | 26G | 5.15 | ✓ |
| PNN | PNN | 9.6 | 461M | 4.25 | ✓ |
| VNN | VNN | 9.0 | 432M | 3.82 | ✓ |
| Wavenet+VNN | Wavenet+VNN | 524.9 | 33G | 5.33 | ✓ |
- 实际意义是什么:为智能手机、车载系统等空间受限设备的隐私音频保护(如防止通话漏音)提供了更有效的技术方案,通过算法补偿扬声器硬件缺陷,提升用户音频体验。
- 主要局限性是什么:1) 计算成本:性能最佳的控制器(Wavenet+VNN)计算量巨大,难以部署在资源受限的移动设备上。2) 模型泛化:前向模型和控制网络针对特定阵列和环境训练,其跨设备、跨环境的泛化能力未验证。3) 开环设计:未考虑实时反馈与环境变化。
🏗️ 模型架构
本文提出一个两阶段的端到端框架,整体架构如图1所示。
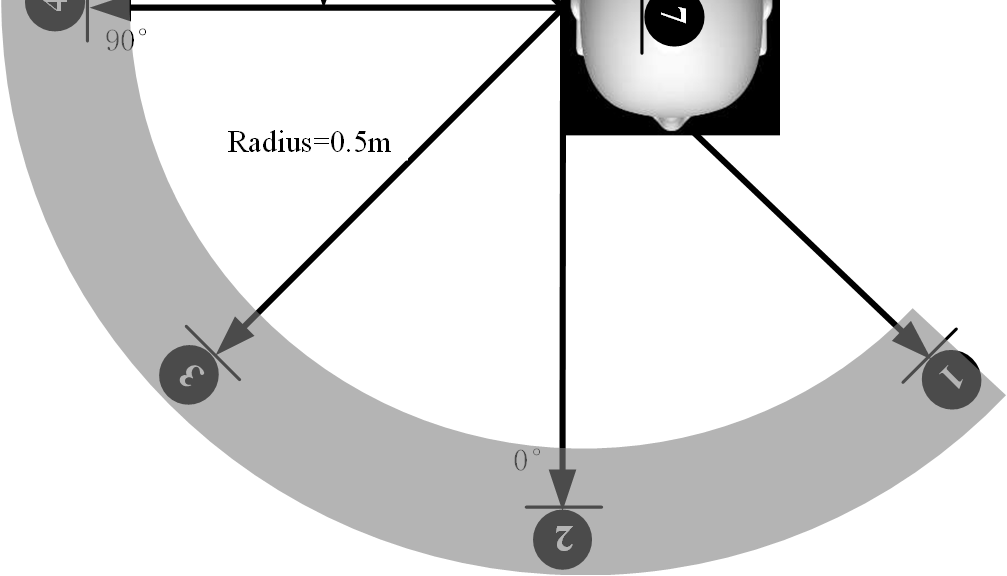
第一阶段:系统辨识(训练前向模型)
- 目标:学习一个能准确模拟真实物理声场的非线性前向模型 $\hat{\mathbf{H}}$。
- 输入:用于训练的音频数据集(语音信号)。
- 模型:采用WaveNet架构。这是一个具有因果膨胀卷积的深度自回归模型,擅长建模长程依赖和复杂非线性。论文具体使用了9个残差块,每个块内有10层扩张率从2^0到2^9的膨胀层,使用16通道膨胀卷积和512通道线性混合器。
- 训练:模型通过同时最小化时域和频域损失(公式8)进行优化,以学习从驱动信号 $s[n]$ 到麦克风测量压力 $p$ 的映射。训练后模型被冻结。
第二阶段:控制器设计(在预训练前向模型上优化控制网络)
- 目标:设计一组控制网络 $W$,其驱动信号通过冻结的前向模型 $\hat{\mathbf{H}}$ 传播后,能在目标控制点产生理想的声场分布(最大化亮暗区能量差)。
- 核心思想:将前向模型 $\hat{\mathbf{H}}$ 作为“可微模拟器”。梯度可以从控制网络的输出(压力)反向传播通过前向模型,直达控制网络的参数,实现端到端优化。
- 差异化控制网络设计:根据扬声器物理布局定制网络:
- 扬声器1(底部):使用一个独立的单输入单输出(SISO)控制网络。
- 扬声器3&4(顶部耦合腔):使用一个共享的多输入多输出(MIMO)控制网络,以显式建模它们之间的声学耦合。
- 可选网络架构:论文对比了多种控制网络,包括线性FIR、多项式神经网络(PNN)、Volterra神经网络(VNN)和WaveNet。其中,PNN实现了广义多项式Hammerstein模型(非线性-线性),VNN实现了二阶Volterra滤波器。
- 数据流:源信号 $x[n]$ → 控制网络 $W$ → 驱动信号 $\hat{y}$ → 冻结前向模型 $\hat{\mathbf{H}}$ → 预测压力 $\hat{p}_B, \hat{p}_D$ → 计算损失函数 → 更新控制网络 $W$。
💡 核心创新点
- 提出统一的数据驱动PSZ框架:首次为个人声区控制提供了一个能兼容传统线性方法、同时支持先进非线性控制的统一框架。它通过将传统线性ATF和线性FIR控制器建模为该框架的特例,建立了新旧方法之间的理论联系。
- 非线性感知的高保真前向模型:放弃了传统线性LTI系统假设,采用深度神经网络(WaveNet)学习扬声器阵列的端到端非线性映射,从根本上解决了系统辨识失真(问题E1)。
- 基于可微模拟器的端到端控制优化:利用预训练的前向模型作为可微分的声学模拟器,在闭环中直接优化控制网络以最大化声对比度,同时解决了控制设计中的非线性叠加失效问题(问题E2)。
- 物理先验驱动的差异化网络架构:根据扬声器的物理布局(独立 vs 耦合)设计不同的网络结构(SISO vs MIMO),将硬件约束融入数据驱动模型,提高了建模效率和性能。
🔬 细节详述
- 训练数据:
- 来源:THCHS-30数据集(中文语音)。
- 规模与预处理:100条干净语音,重采样至48 kHz,截断为7秒。
- 数据增强:通过19个随机均衡滤波器处理每条语音,生成共2000条唯一语音。训练集与测试集按70:30随机划分。
- 录制方案:在半消声室中,录制两种条件下的数据:四个扬声器分别单独播放,以及四个扬声器同时播放相同语音。单独播放数据用于前向模型训练,同时播放数据用于控制网络训练。
- 损失函数:
- 前向模型损失 (公式8):$\mathcal{L}{forward} = \mathcal{L}{time}(\mathbf{p}, \hat{\mathbf{p}}) + \beta \cdot \mathcal{L}{freq}(\mathbf{p}, \hat{\mathbf{p}})$,其中 $\beta=0.3$。$\mathcal{L}{time}$ 为波形MSE,$\mathcal{L}_{freq}$ 为基于STFT的频域损失。
- 控制网络损失 (公式9):$\mathcal{L} = \gamma \mathcal{L}{AED} + (1-\gamma) \mathcal{L}{freq-AED} + \eta \mathcal{L}_{spec}(\hat{\mathbf{p}}_B, \mathbf{d}B)$。本文主要任务为泄漏抑制,因此设置 $\eta=0$,$\gamma=0.3$。$\mathcal{L}{AED}$ (公式10) 是声能量差的时域代理损失。
- 训练策略:论文未说明具体的学习率、优化器、batch size、训练轮数等超参数。
- 关键超参数:
- 前向模型:WaveNet,9个残差块,每块10层膨胀卷积(扩张率2^0至2^9),16通道,512通道线性层。
- 控制网络:以最佳Wavenet+VNN为例,WaveNet部分(用于网络1)有3个残差块,每块10层膨胀卷积,32通道;VNN部分(用于网络2)实现二阶Volterra滤波器,记忆深度600。
- 训练硬件:论文中未提及。
- 推理细节:论文中未详细说明,但强调了所有控制网络都保证了因果性(表1最后一列)。
- 正则化/稳定技巧:在控制网络损失中使用了声能量差(AED)替代直接优化AC以防止数值不稳定;使用了谱保真度损失 $\mathcal{L}_{spec}$ 的可选加权(本文设为0)。
📊 实验结果
主要实验设置:
- 任务:模拟智能手机通话场景,抑制语音泄漏。
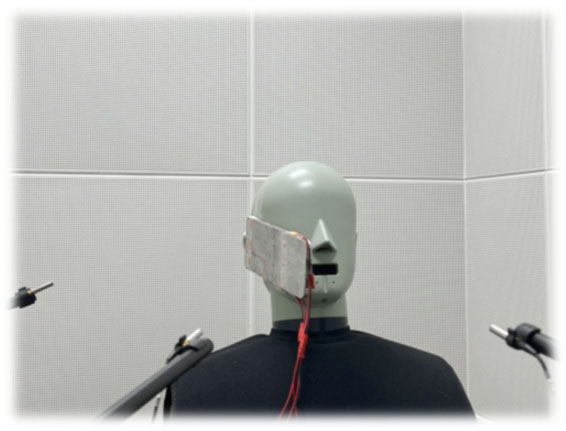
- 硬件:四通道微型扬声器阵列(手机尺寸铝壳),HATS(头与躯干模拟器)。
- 基线方法:频率域可变跨度折衷滤波器(VAST)方法 [29],其性能与传统声对比度控制(ACC)算法相当。
- 评估指标:声对比度(AC),定义为亮暗区平均功率谱密度的比值(dB),见公式(11)。
关键结果(见下表):
- 所有非线性控制网络(PNN, VNN, WaveNet组合)均显著优于纯线性控制网络(其ΔAC仅为1.04 dB)。
- 最佳性能由 WaveNet+VNN 组合实现,相比VAST基线提升了 5.33 dB。这证明了针对不同扬声器单元采用差异化控制架构的有效性。
- 表现次优的线性+WaveNet配置(ΔAC=5.15 dB)表明,即使使用线性控制器,仅通过在准确的非线性模型上优化,也能获得巨大收益。
- 性能与计算复杂度存在权衡:Linear+VNN配置以显著更低的计算量(288M vs 33G MACs)实现了3.70 dB的提升,可能更适合实时应用。
| 控制网络组合 | 参数量(K) | 计算量(MACs) | ΔAC (dB) |
|---|---|---|---|
| Linear + Linear | 4.8 | 228M | 1.04 |
| Linear + PNN | 7.6 | 307M | 3.62 |
| Linear + VNN | 7.2 | 288M | 3.70 |
| Linear + WaveNet | 379.6 | 26G | 5.15 |
| PNN + PNN | 9.6 | 461M | 4.25 |
| VNN + VNN | 9.0 | 432M | 3.82 |
| WaveNet+VNN | 524.9 | 33G | 5.33 |
图表分析:
- 图3(SPL对比):展示了最佳控制器(Linear+WaveNet)与基线VAST的声压级对比。在暗区(DZ),该控制器在200-2000 Hz频段实现了显著的声压级降低,这正是小型扬声器非线性失真最严重的区域,验证了方法针对性。
- 图4(驱动信号波形):比较了Linear+WaveNet控制器与VAST为扬声器3生成的驱动信号。两者波形差异细微,表明非线性控制器产生的信号主体仍是线性分量,叠加了较小的非线性预失真分量以补偿扬声器失真。
⚖️ 评分理由
- 学术质量:7.0/7:论文提出了一个完整、新颖且理论自洽的数据驱动框架来解决一个明确的实际问题。创新点清晰(统一框架、非线性建模、端到端优化、差异化设计),技术方案合理。实验在真实物理平台上完成,对比基线选择恰当,结果数据充分且具有说服力。扣分点主要在于:1) 部分关键复现细节(训练超参数、硬件)缺失;2) 缺乏对模型泛化能力的验证;3) 最优模型计算成本过高,与应用目标存在潜在矛盾。
- 选题价值:1.5/2:选题精准定位了消费电子音频设备(如手机)中声区控制性能瓶颈的现实问题,具有明确的应用背景和市场需求。提出的解决方案为音频信号处理领域应对硬件非线性挑战提供了新的范式。但个人声区控制本身是一个相对垂直的研究领域,受众和影响范围有限。
- 开源与复现加成:0.0/1:论文中未提供代码、模型权重、完整训练配置或数据集的链接。对于复现其框架,尤其是前向模型和控制网络的完整训练过程,信息严重不足,因此无加成。