📄 A Consistent Learning Depression Detection Framework Integrating Multi-View Attention
#语音生物标志物 #一致性学习 #注意力机制 #数据增强 #音频分类
✅ 6.5/10 | 前50% | #语音生物标志物 | #一致性学习 | #注意力机制 #数据增强
学术质量 6.2/7 | 选题价值 1.5/2 | 复现加成 0.3 | 置信度 中
👥 作者与机构
- 第一作者:徐淑敏(Shuomin Xue)(东南大学网络科学与工程学院)
- 通讯作者:杨春峰(Chunfeng Yang)(东南大学计算机科学与工程学院)
- 作者列表:徐淑敏(Shuomin Xue)(东南大学网络科学与工程学院)、姚嘉轩(Jiaxuan Yao)(东南大学软件工程学院)、杨春峰(Chunfeng Yang)(东南大学计算机科学与工程学院)
💡 毒舌点评
这篇论文首次将一致性学习范式引入基于音频的抑郁症检测,想法巧妙,技术整合度也不错。但论文的实验对比部分有些“自说自话”,Table 1中多个重要基线方法的Precision和Recall列为空,削弱了对比的说服力,而且作为一篇2026年的论文,完全没有提及开源计划,这对于临床应用研究来说是一个明显的短板。
🔗 开源详情
- 代码:论文中未提及代码���接。
- 模型权重:未提及公开权重。
- 数据集:论文使用了公开数据集DAIC-WOZ和CMDC,但未在论文中提供具体的获取方式或链接(通常这些数据集需通过官方渠道申请)。
- Demo:未提供在线演示。
- 复现材料:论文给出了基本的超参数设置(λ1, λ2, σ, p, 学习率, batch size, BiLSTM维度)和数据预处理流程,但缺少模型具体层结构参数(如FAM中间层维度、多头注意力头数)、训练轮数、Dropout率、代码框架(如PyTorch/TensorFlow)等关键信息。
- 论文中引用的开源项目:论文中引用了VGGish[7]和eGeMAPS[6](通过OpenSMILE工具[6]实现)作为特征提取器,这些是公开可用的模型和工具。
📌 核心摘要
本文旨在解决基于音频的自动抑郁症检测中面临的信号噪声大、模型鲁棒性不足的问题。作者提出了DSCAM(Dual-Student Consistency Learning Framework with Multi-view Attention)框架,其核心是采用两个独立初始化的学生模型,通过对未标注数据施加高斯噪声和通道掩码增强,利用一致性损失和稳定性损失约束两个模型输出的一致性,从而学习对噪声鲁棒的表示。同时,提出了时间注意力模块(TAM)和特征注意力模块(FAM),分别从时间和特征维度关注关键信息并抑制噪声。实验在CMDC和DAIC-WOZ两个抑郁症数据集上进行,结果表明DSCAM在F1分数和召回率上优于所对比的监督学习方法,例如在DAIC-WOZ数据集上F1达到0.683,召回率达0.710,在CMDC数据集上F1和召回率均达到0.955。消融实验证明了每个模块的贡献。该工作的实际意义在于为临床抑郁症的早期、客观筛查提供了一种潜在的自动化工具。主要局限性包括:1)实验对比不够全面,部分关键基线指标缺失;2)方法高度依赖半监督学习设置,且在更复杂的真实噪声环境下的泛化能力有待验证;3)未提供代码或模型复现资源。
🏗️ 模型架构
DSCAM的完整架构如图1(a)所示,是一个基于双学生模型的半监督学习框架。其核心流程如下:
- 输入与增强:将训练数据分为有标签和无标签两部分。对无标签数据,通过高斯噪声(公式1)和通道掩码(公式2)生成两个增强视图(
Xaug1,Xaug2),并各自应用Dropout(公式3),最终得到四个输入:Xlabel,Xaug1‘,Xaug2‘(来自第一个学生S1)以及对应的视图输入给第二个学生S2(S1和S2结构相同但初始化不同)。 - 特征提取与时序建模:对每个视图,分别使用预训练的VGGish模型提取128维深度特征(
Xvgg)和eGeMAPS工具提取88维声学特征(Xege)。每个特征流都经过层归一化(LN)后输入双向LSTM(BiLSTM)以捕获时序依赖,得到时序增强的特征Xt_vgg和Xt_ege。 - 时间维度注意力(TAM):TAM的结构如图1(b)所示。它接收BiLSTM的输出,沿特征维度分别进行平均池化和最大池化(公式5, 6),然后拼接(公式7)。拼接后的特征通过一个包含两层1D卷积、BatchNorm和Sigmoid激活的模块,生成时间注意力权重
Wtem(公式8, 9)。该权重与原始BiLSTM输出逐元素相乘,实现对重要时间段的加权(公式10)。 - 特征融合与全局池化:将两个经过时间加权的特征(
Xtem_vgg,Xtem_ege)在特征维度拼接,得到融合特征Xfusion。随后通过多头自注意力(Multi-Head Attention)捕获不同时间步间的依赖关系,输出X‘fusion。再经过自适应平均池化和展平,得到全局向量Xglobal。 - 特征维度注意力(FAM):FAM的结构如图1(c)所示。它是一个小型神经网络,接收
Xglobal,经过线性层(降维)、ReLU激活、线性层(升维)和Sigmoid激活,生成特征注意力权重Wfeature(公式13)。该权重与Xglobal逐元素相乘,增强重要特征维度(公式14)。 - 分类与损失:增强后的特征
Xenhanced通过一个分类器(包含BN、Dropout和两层线性层)得到最终预测P(公式15)。模型总损失(公式21)由三部分组成:有标签数据的交叉熵损失(Li_cls),无标签数据两个增强视图之间的一致性损失(Li_con,公式16),以及两个学生模型之间的稳定性损失(Li_stab,公式19)。稳定性损失的设计是改进的关键,它根据模型自身预测的稳定性(si)来决定是否及如何互相监督。
 图1说明: (a)展示了DSCAM的整体双学生框架,数据流从左到右,包括数据增强、两个并行的学生模型(S1/S2)处理流程,以及最终的联合损失计算。(b)和(c)分别放大展示了TAM和FAM的内部结构。
图1说明: (a)展示了DSCAM的整体双学生框架,数据流从左到右,包括数据增强、两个并行的学生模型(S1/S2)处理流程,以及最终的联合损失计算。(b)和(c)分别放大展示了TAM和FAM的内部结构。
💡 核心创新点
- 首次引入双学生一致性学习到抑郁症检测:将原本用于图像领域的双学生半监督学习框架(Ke et al., ICCV 2019)适配到音频抑郁症检测任务中。通过设计针对音频噪声的数据增强(高斯噪声、通道掩码)和改进的稳定性损失计算方式(利用两个增强视图预测的一致性来衡量稳定性),使得模型在噪声环境下学习更鲁棒的表征。
- 提出双视角注意力机制(TAM & FAM):设计了两个互补的注意力模块,分别从时间维度(定位音频中与抑郁相关的关键语音片段)和特征维度(突出对判别重要的声学或深度特征)抑制噪声。TAM利用池化和一维卷积生成时序权重,FAM利用轻量级神经网络生成特征权重。
- 改进的稳定性损失设计:论文对双学生框架中的稳定性损失(公式19)进行了重新设计。不同于原框架,它通过检查两个学生模型对同一原始样本的两个增强视图预测类别是否一致(
si)来判断稳定性,并据此动态决定是单向监督还是选择更稳定的模型作为监督目标。这比单纯依赖模型参数平均的教师模型可能更灵活。
🔬 细节详述
- 训练数据:
- 数据集:DAIC-WOZ(189段,训练/开发/测试划分:107/35/47)和CMDC(78段,26抑郁/52健康)。
- 预处理:DAIC-WOZ去除静音后分割为5秒片段;CMDC分割为5秒片段,段间有2秒重叠。
- 数据增强:仅对无标签数据进行。高斯噪声标准差
σ=0.01,通道掩码概率p=0.03。增强后对两个视图应用Dropout(概率未说明)。
- 损失函数:
- 交叉熵损失(
Li_cls):标准二分类交叉熵,用于有标签数据。 - 一致性损失(
Li_con):计算同一学生模型对两个增强视图预测概率分布(softmax后)的归一化均方误差(MSE),强制模型在不同扰动下输出稳定。 - 稳定性损失(
Li_stab):如公式19所示,是一种条件MSE损失。权重:λ1=0.2(一致性损失),λ2=1.0(稳定性损失)。
- 交叉熵损失(
- 训练策略:
- 优化器:Adam。
- 学习率:
1e-4。 - Batch Size:64。
- 训练轮数/步数:未说明。
- Warmup/调度策略:未说明。
- 关键超参数:
- BiLSTM隐藏层维度:32。
- 多头注意力:头数未说明。
- 特征维度:VGGish输出128维,eGeMAPS输出88维。融合后全局向量
Xglobal维度为2*(128+88)=432?论文公式(11)有误,拼接应是Xtem_vgg和Xtem_ege在特征维拼接,假设Xtem_vgg为B×T×128,Xtem_ege为B×T×88,则Xfusion为B×T×216。经多头注意力、池化后Xglobal维度应为216。FAM内部线性层的降维/升维维度未说明。 - 分类器结构:
Linear(Dropout(Linear(BN(Xenhanced)))),中间维度未说明。
- 训练硬件:24GB NVIDIA RTX 3090 GPU。
- 推理细节:未说明解码策略等,因本任务是分类而非生成。
- 正则化技巧:使用了Dropout(在数据增强后和分类器中)、层归一化(LN)、Batch Normalization(BN)。
📊 实验结果
论文在两个数据集上进行了对比实验和消融研究,主要结果如下。
表1:与基线方法在DAIC-WOZ和CMDC数据集上的性能比较(最佳值加粗)
| 数据集 | 方法 | Precision | F1 | Recall |
|---|---|---|---|---|
| DAIC-WOZ | Wei et al.[11] | 0.560 | 0.610 | 0.660 |
| Ghadiri et al. [12] | 0.611 | 0.634 | 0.667 | |
| Hanai et al. [13] | 0.710 | 0.630 | 0.560 | |
| Feng et al. [14] | 0.830 | 0.560 | 0.420 | |
| Sun et al. [15] | / | 0.610 | / | |
| Wu et al. [16] | / | 0.639 | / | |
| DSCAM (ours) | 0.673 | 0.683 | 0.710 | |
| CMDC | Gupta et al. [17] | 0.938 | 0.915 | 0.900 |
| Zhang et al. [18] | 0.948 | 0.905 | 0.883 | |
| Sun et al. [19] | 0.920 | 0.870 | 0.830 | |
| Zou et al. [10] | 1.000 | 0.910 | 0.830 | |
| DSCAM (ours) | 0.956 | 0.955 | 0.955 |
关键结论:在DAIC-WOZ数据集上,DSCAM的F1(0.683)和Recall(0.710)均为最高,相比第二优模型(Ghadiri et al. 的F1 0.634)分别提升了4.9%和4.3%。在CMDC数据集上,DSCAM的F1和Recall均为0.955,显著高于其他方法。值得注意的是,部分基线方法(如Sun et al.[15], Wu et al.[16])的Precision或Recall未报告。
消融研究:在两个数据集上对比了DSCAM与三个变体:(i) w/o dual students (单模型监督学习),(ii) w/o fea (去掉FAM),(iii) w/o tem (去掉TAM)。结果如图2所示。
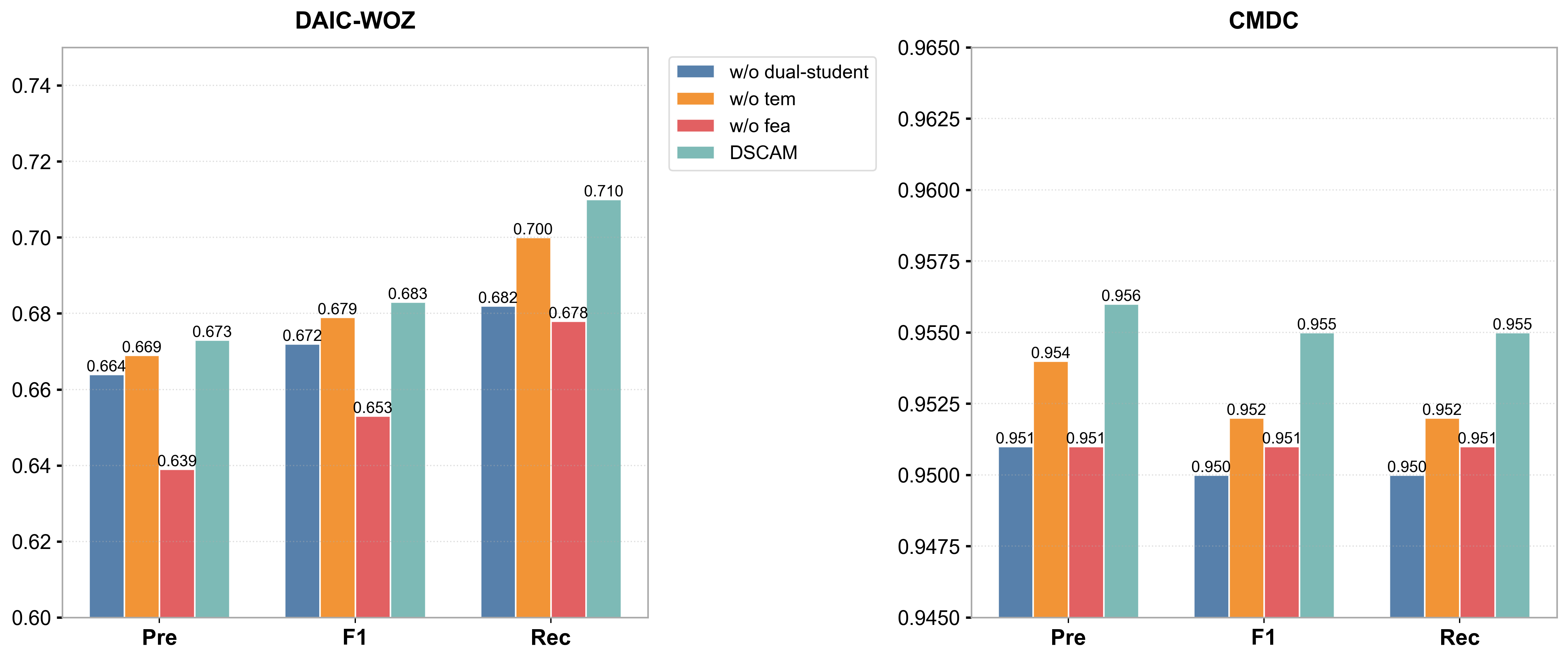 图2说明: 在DAIC和CMDC数据集上,移除任何模块(双学生、FAM、TAM)都会导致Precision、F1和Recall三个指标的下降。在DAIC-WOZ数据集上,完整模型相比“w/o dual students”变体,在三项指标上分别提升了0.9%, 1.1%, 2.8%。这表明在噪声更大的DAIC-WOZ数据集上,一致性学习(双学生框架)的贡献更显著。同时,FAM和TAM的去除也带来了明显的性能下降,尤其在DAIC数据集上(FAM去除导致F1下降3.0%),验证了两个注意力模块的有效性。
图2说明: 在DAIC和CMDC数据集上,移除任何模块(双学生、FAM、TAM)都会导致Precision、F1和Recall三个指标的下降。在DAIC-WOZ数据集上,完整模型相比“w/o dual students”变体,在三项指标上分别提升了0.9%, 1.1%, 2.8%。这表明在噪声更大的DAIC-WOZ数据集上,一致性学习(双学生框架)的贡献更显著。同时,FAM和TAM的去除也带来了明显的性能下降,尤其在DAIC数据集上(FAM去除导致F1下降3.0%),验证了两个注意力模块的有效性。
⚖️ 评分理由
- 学术质量:6.2/7:论文提出了一个完整且动机清晰的框架,创新性地将双学生一致性学习应用于音频抑郁症检测,并设计了针对性的注意力模块。技术细节描述基本清晰,实验包含对比和消融,提供了量化证据。扣分点在于:1) 对比实验不充分,Table 1中多个关键基线指标缺失,削弱了结论的强度;2) 对改进的稳定性损失的有效性缺乏更深入的分析或验证;3) 部分公式和图表标注有小错误(如公式11的拼接维度描述与图示可能不符)。
- 选题价值:1.5/2:抑郁症检测是重要的临床辅助应用,利用语音生物标志物进行非侵入性筛查具有高社会价值和应用前景。论文聚焦噪声鲁棒性这一实际部署中的关键问题,选题前沿且务实。
- 开源与复现加成:0.3/1:论文提供了实施细节(数据集划分、超参数、模型组件描述),使得方法思路可理解、大体可复现。但完全未提供代码仓库、预训练模型或数据集下载指引,也未提及任何开源计划,这严重阻碍了同行的验证与应用,复现加成仅基于文本描述。