📄 A Bayesian Approach to Singing Skill Evaluation Using Semitone Pitch Histogram and MCMC-Based Generated Quantities
#音乐理解 #贝叶斯建模 #信号处理 #模型评估 #少样本
✅ 7.0/10 | 前25% | #音乐理解 | #贝叶斯建模 | #信号处理 #模型评估
学术质量 5.5/7 | 选题价值 1.5/2 | 复现加成 0.0 | 置信度 中
👥 作者与机构
- 第一作者:Tomoyasu Nakano(日本产业技术综合研究所,AIST)
- 通讯作者:未说明
- 作者列表:Tomoyasu Nakano(日本产业技术综合研究所,AIST)、Masataka Goto(日本产业技术综合研究所,AIST)
💡 毒舌点评
亮点:论文将统计建模的严谨性引入了一个通常由深度学习主导的“歌唱评估”领域,利用贝叶斯概率输出和PHC指标,为“音准好不好”这个问题提供了带有不确定性的量化答案,而非一个冰冷的分数,这种视角在可解释性和用户反馈设计上很有价值。 短板:模型假设过于简化,将颤音和音符过渡“均匀”地混在一起,导致音准指标(π, pδ)本质上是“稳定音高比例”的一个嘈杂估计;且实验仅在单一内部数据集上进行,缺乏与传统机器学习或深度学习方法的直接性能对比,说服力有限。
🔗 开源详情
- 代码:论文中未提及代码链接。
- 模型权重:未提及。
- 数据集:使用内部数据集,论文未提及公开获取方式。
- Demo:未提及。
- 复现材料:论文详细描述了模型公式、先验分布、MCMC采样设置(预热、采样数、链数、收敛标准),以及评估指标(pδ, PHC)的计算方法,提供了较高的理论复现性。依赖的开源项目:CmdStanPy (https://mc-stan.org/cmdstanpy/),Stan (https://mc-stan.org/)。
- 论文中未提及开源计划。
📌 核心摘要
- 问题:现有自动歌唱技能评估方法要么依赖手工特征,要么依赖大规模数据集训练模型输出单一标量分数(如排名/评级),难以从单次演唱中提供可解释的、概率性的技能指标,且对引入新任务不友好。
- 方法核心:提出一种基于贝叶斯建模的方法。以“半音音高直方图”(将基频F0转换为半音并以±0.5半音为窗口折叠)作为表示,构建了一个由截断正态分布和均匀分布组成的混合模型来对其进行建模。使用汉密尔顿蒙特卡洛(HMC)/No-U-Turn Sampler (NUTS) 从模型后验中采样。
- 新意:与依赖点估计或判别式学习的方法不同,该方法通过MCMC后验采样生成“生成量”(generated quantities),如参数π(稳定音高成分权重)和σ(分布宽度),并进一步计算“假设正确概率(PHC)”。这允许进行概率性的、考虑不确定性的技能比较和阈值判断,且对小样本数据友好。
- 主要实验结果:在包含140首日文流行歌曲的内部数据集上进行验证。表1显示,模型参数(σ, π, pδ)在87%-96%的演唱中达到收敛标准。图3的散点图显示,生成的指标(π, pδ=0.10, pδ=0.25)与人工标注的综合音准分数呈现正相关(EAP相关系数分别为0.34, 0.44, 0.42),σ则呈现负相关(-0.30)。
- 实际意义:为歌唱技能评估提供了一种可解释、概率化、无需大规模数据的新范式,可用于个性化反馈(如指出哪些段落音准更稳定)和交互设计。该框架可扩展至其他音频特征。
- 主要局限性:模型仅部分捕捉音准相关技巧,未显式建模颤音和音符过渡等重要成分,仅将其视为“非稳定”噪声的一部分;实验未与任何现有SOTA歌唱评估方法进行性能对比;数据集规模较小且未公开。
🏗️ 模型架构
论文未提供系统架构图。其核心是一个用于建模半音音高直方图的贝叶斯混合模型。流程如下:
- 输入:单次演唱的原始音频。
- 预处理:
- 使用WORLD声码器提取基频(F0)序列。
- 排除无声帧。
- 将F0(Hz)转换为半音单位:
s = 12 * log2(f0 / 440) + 69。 - 将半音值折叠到±0.5半音区间:
x = (s + 0.5) mod 1 - 0.5。这一步确保正确音高的中心在0。
- 模型:混合概率模型,公式为
p(x) = π NT(x; µ, σ²) + (1-π) U(x; -0.5, 0.5)。- 截断正态分布
NT(x; µ, σ²):定义在[-0.5, 0.5]区间。代表“稳定演唱”成分,即围绕目标音高的音高分布。µ是均值(可吸收轻微的调音频率偏差),σ是标准差(反映音高集中度)。 - 均匀分布
U(x; -0.5, 0.5):代表“非稳定”成分,统一建模音符过渡、颤音和音准误差。 - 权重
π:表示稳定成分在整体分布中的比例。
- 截断正态分布
- 先验分布:
µ ~ N(0, 0.1²):假设均值接近0。σ ~ Half-Student-t(3, 0, 0.15²):半正态的学生t分布,确保σ为正且允许较厚尾部。π ~ Beta(1, 1):均匀先验。
- 推断:使用CmdStanPy(Stan的概率编程接口)和NUTS采样器进行MCMC后验采样。设置:3000次预热,1000次采样,4条链。使用
R̂ < 1.01和ESS > 400作为收敛诊断。 - 输出:后验样本(T=4000个样本),以及基于这些样本计算的生成量,如:
- 参数估计值(π, σ, µ的EAP/MAP)。
- 概率量
pδ:稳定成分在区间[µ-δ, µ+δ]内的概率质量(见公式7)。例如pδ=0.1。 - 假设正确概率(PHC):用于评估任意假设U(如
π > c或π_A > π_B)的后验概率(见公式8-9)。
💡 核心创新点
- 将贝叶斯概率框架引入歌唱技能评估:不同于以往输出单一确定性分数的方法,本框架从单次演唱中生成参数的后验分布和概率性指标,允许量化评估结果的不确定性,为可解释的分析和交互式反馈奠定基础。
- 提出基于生成量的评估范式:利用MCMC采样的后验样本计算“生成量”(如
pδ)和PHC。这使得可以进行概率比较(例如,计算一个版本比另一个版本音准好的概率),超越了简单的点估计对比。 - 使用半音音高直方图并对其进行贝叶斯混合建模:选用半音音高直方图作为输入特征以减少歌曲特异性。构建截断正态-均匀混合模型来解释音高分布,该模型直接且可解释地分离出“稳定”与“非稳定”成分,参数(π, σ)与音准技能相关。
- PHC作为直观的评估与比较工具:借鉴心理学中的PHC概念,将其应用于声学特征评估,通过计算后验概率来直观展示技能水平或进行两两比较,具有较好的可解释性和用户友好性。
🔬 细节详述
- 训练数据:
- 数据集:论文作者的内部数据集,源自[17]。
- 规模:140段独唱演唱(20首日文流行歌曲,每首由7位歌手演唱)。
- 预处理:音频转换为16kHz单声道,使用WORLD提取F0,排除无声帧。背景音乐在评估时混入,但分析使用干声。
- 数据增强:未提及。
- 损失函数/优化目标:本方法为贝叶斯推断,不使用传统损失函数。目标是根据先验和似然函数(模型公式3)计算参数的后验分布
p(µ, σ, π | 数据)。 - 训练策略:
- 采样器:NUTS(HMC的一种自适应变体)。
- 预热(Burn-in):3000次迭代。
- 采样:1000次迭代。
- 链数:4条。
- 收敛诊断:
R̂ < 1.01且有效样本量(ESS) > 400。
- 关键超参数:见上述训练策略。先验分布的超参数(如
N(0, 0.1²)中的0.1,Half-Student-t(3, 0, 0.15²)中的0.15)在文中给出。 - 训练硬件:未说明。
- 推理细节:对于新的演唱,重复步骤1-5进行推断,得到该演唱的后验样本。然后基于这些样本计算所需的生成量(如
pδ)和PHC。 - 正则化或稳定训练技巧:未明确提及。贝叶斯框架通过先验分布自然地引入了正则化。
📊 实验结果
主要数据与指标:
- 数据集:内部140段日文流行歌曲演唱。
- 基准/对比:未与任何现有的歌唱评估方法(如基于机器学习的评分、其他声学指标)进行定量对比。评估基准是人工标注的综合音准分数(通过IRT模型聚合10位专家的7点Likert评分得出)。
- 收敛性分析(表1):
| 参数 | 收敛数量(/140) | 收敛百分比 |
|---|---|---|
| σ | 123 | 87.9% |
| π | 122 | 87.1% |
| pδ=0.05 | 134 | 95.7% |
| pδ=0.10 | 132 | 94.3% |
| pδ=0.15 | 129 | 92.1% |
| pδ=0.20 | 127 | 90.7% |
| pδ=0.25 | 125 | 89.3% |
| 结论:在大多数演唱上,模型能够收敛,表明所提出的模型和设置在实践中是可行的。 |
与人工评分的相关性(图3):
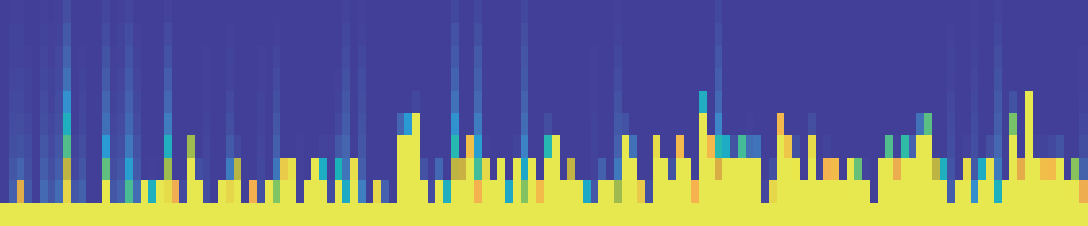 图3说明:展示了收敛的演唱中,人工综合音准分数(EAP)与模型参数(π, σ, pδ=0.10, pδ=0.25)的散点图。图中包含了MAP/EAP估计值及其3-97%最高密度区间(HDI)。
关键数字:EAP相关系数:π (0.34), σ (-0.30), pδ=0.10 (0.44), pδ=0.25 (0.42)。MAP相关系数:π (0.43), σ (-0.19), pδ=0.10 (0.45), pδ=0.25 (0.46)。
结论:生成的指标(特别是pδ)与人工评分存在中等强度的正相关,σ呈负相关,表明这些指标确实能部分反映人工感知的音准技能。pδ的相关性略高于π。
图3说明:展示了收敛的演唱中,人工综合音准分数(EAP)与模型参数(π, σ, pδ=0.10, pδ=0.25)的散点图。图中包含了MAP/EAP估计值及其3-97%最高密度区间(HDI)。
关键数字:EAP相关系数:π (0.34), σ (-0.30), pδ=0.10 (0.44), pδ=0.25 (0.42)。MAP相关系数:π (0.43), σ (-0.19), pδ=0.10 (0.45), pδ=0.25 (0.46)。
结论:生成的指标(特别是pδ)与人工评分存在中等强度的正相关,σ呈负相关,表明这些指标确实能部分反映人工感知的音准技能。pδ的相关性略高于π。PHC概率分析(图4):
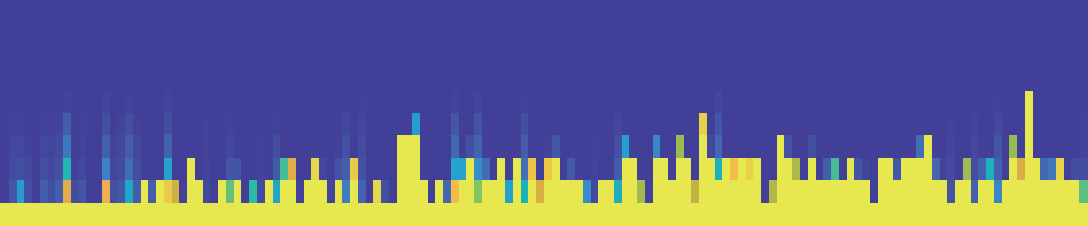 图4说明:展示了π和pδ=0.25两个指标超过阈值c(0到1)的PHC概率热图(上/中),以及对应演唱的人工综合音准分数(下)。演唱按人工分数从高到低排列(从右到左)。
结论:在音准技能高的演唱(右侧),π和pδ在较大c值下仍保持较高的PHC(黄色区域延伸到更大c值)。但论文指出,对于低分演唱,π的PHC在较大c值时仍可能较高,而pδ能更好地抑制这一趋势,因此pδ可能比π更准确地反映实际技能。
图4说明:展示了π和pδ=0.25两个指标超过阈值c(0到1)的PHC概率热图(上/中),以及对应演唱的人工综合音准分数(下)。演唱按人工分数从高到低排列(从右到左)。
结论:在音准技能高的演唱(右侧),π和pδ在较大c值下仍保持较高的PHC(黄色区域延伸到更大c值)。但论文指出,对于低分演唱,π的PHC在较大c值时仍可能较高,而pδ能更好地抑制这一趋势,因此pδ可能比π更准确地反映实际技能。消融实验/细分结果:未提供。
具体数值:相关系数等数值已在上文列出。
⚖️ 评分理由
- 学术质量:5.5/7:创新性(2/3):将贝叶斯概率框架和生成量/PHC概念引入歌唱评估,视角新颖,具有方法论上的启发意义。技术正确性(1.5/2):模型构建合理,MCMC推断设置得当,收敛诊断标准严谨。实验充分性(1/2):实验设计合理,包含了收敛性检验和相关性分析,证明了方法的可行性。但实验规模有限(仅140条),且缺乏与现有主流方法的性能对比,限制了结论的普适性和强度。证据可信度(1/1):实验基于明确的数据集和统计指标,结论基于数据支撑。
- 选题价值:1.5/2:前沿性(0.5/1):为音频分析中的技能评估提供了概率化、可解释的新思路,与当前强调可解释AI的趋势相符。潜在影响与应用空间(1/1):为个性化音乐教育、卡拉OK评分、演唱练习反馈等提供了更细腻的工具,潜力较大。读者相关性(0/1):对于音乐信息检索、音频分析领域的研究者有一定参考价值,但对更广泛的语音/音频社区,相关性中等。
- 开源与复现加成:0.0/1:论文未提供代码、模型或数据集的公开链接。虽然复现所需的工具(Stan, CmdStanPy)和设置(参数、超参数)描述详细,但获取原始数据和完整实现仍需较大努力,因此不提供加成。